
详解低延时高音质:编解码篇

语音社交已经出现了数十年,而近期的“互动播客”场景让音频互动再次成为业界焦点。如何提供好的音频互动体验?怎么优化音质?如何应对全球传输下的网络挑战?如何在高音质的基础上让声音更悦耳?我们将从今天开始通过「详解低延时高音质」系列内容,从多个层面深入浅出逐一解答这些问题。

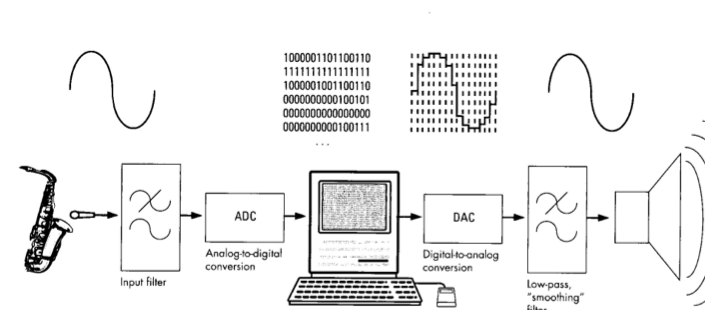
音频编码指的是把音频信号转化为数字码流的过程(如下图所示)。在这个过程中,音频信号会被分析从而产生特定参数。随后,这些参数会按照一定规则写入比特流。这个比特流也就是我们常说的码流。解码端接收到码流后,会按照约定好的规则将码流还原为参数,再使用这些参数构建出音频信号。
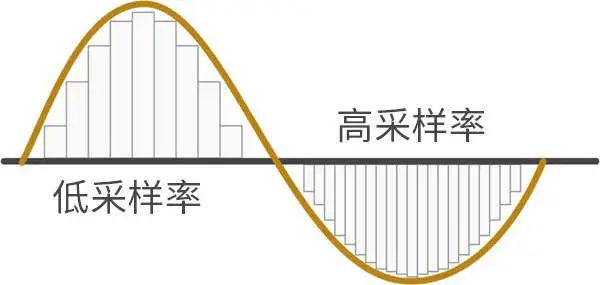
一、采样率
从人耳可以听到的模拟信号,转化到计算机可以处理的数字信号,需要一个采样的过程。声音可以被分解为不同频率不同强度正弦波的叠加。采样可以想象成在声波上采集了一个点。而采样率指的就是在这个过程中每秒采样的点数,采样率越高,表示在这个转化过程损失的信息越少,也就是越接近原声。
关于质量甜点:在视频领域,质量甜点指的是在既定的码率和屏幕大小下通过设定合理的分辨率和帖速率来得到最佳视频主观质量体验。在音频领域也有类似的情况。
客观评价层面,使用 ITU-T P.863 标准定义的客观质量评估算法对两个编解码器的编码-解码语料进行打分,Nova 得分始终比 Opus 略高一筹;
主观评价层面,经过 Nova 编解码的语音信号的还原度要高于经过 Opus 编解码的语音信号,反映在听感上就是更通透,量化噪音更小。
评论