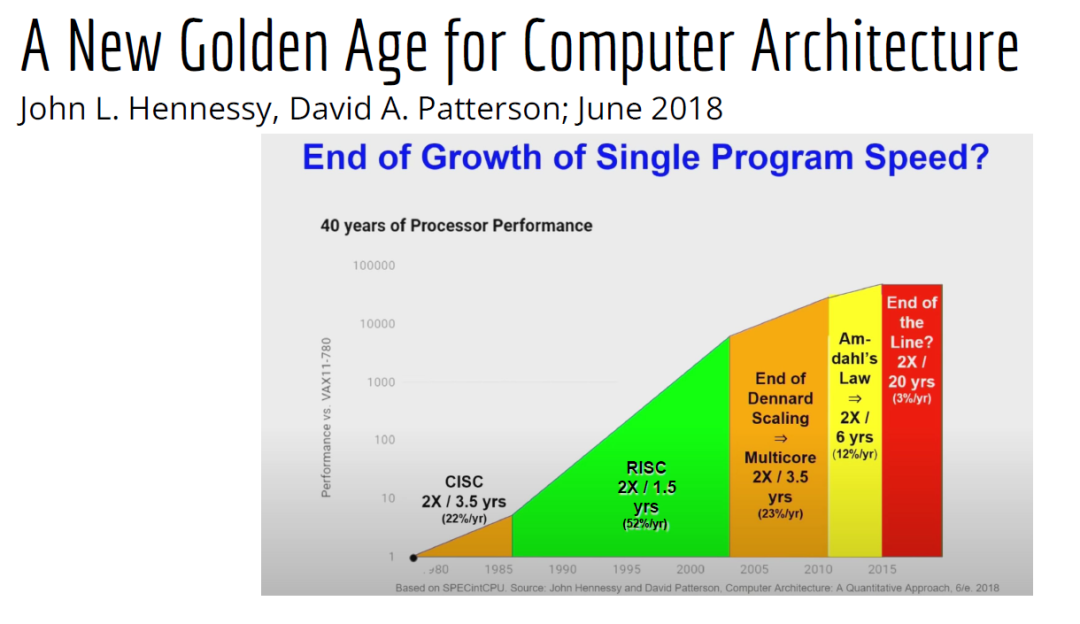
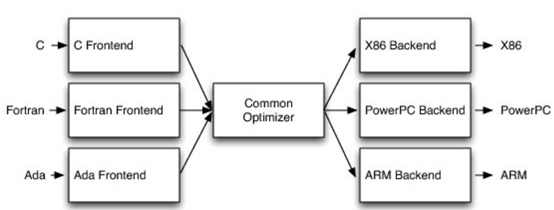
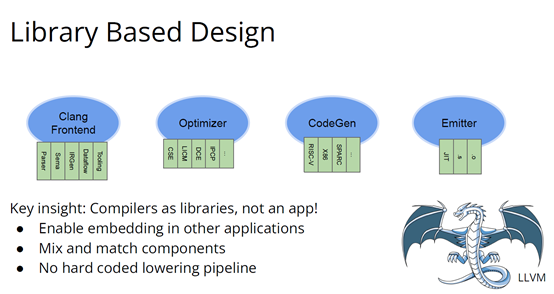
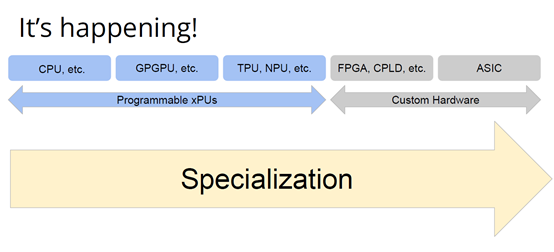
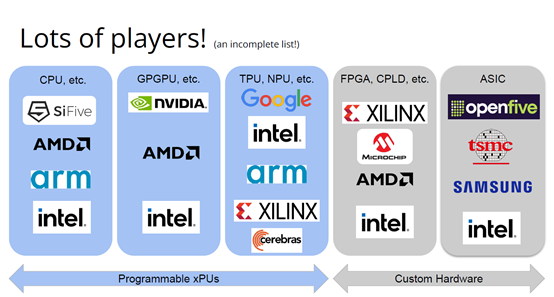
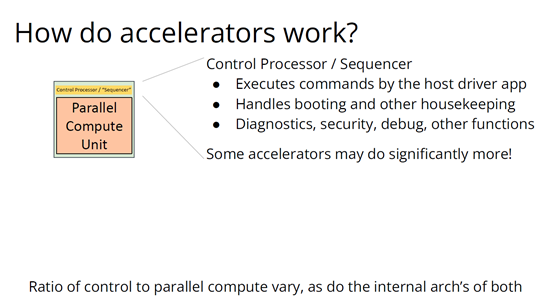
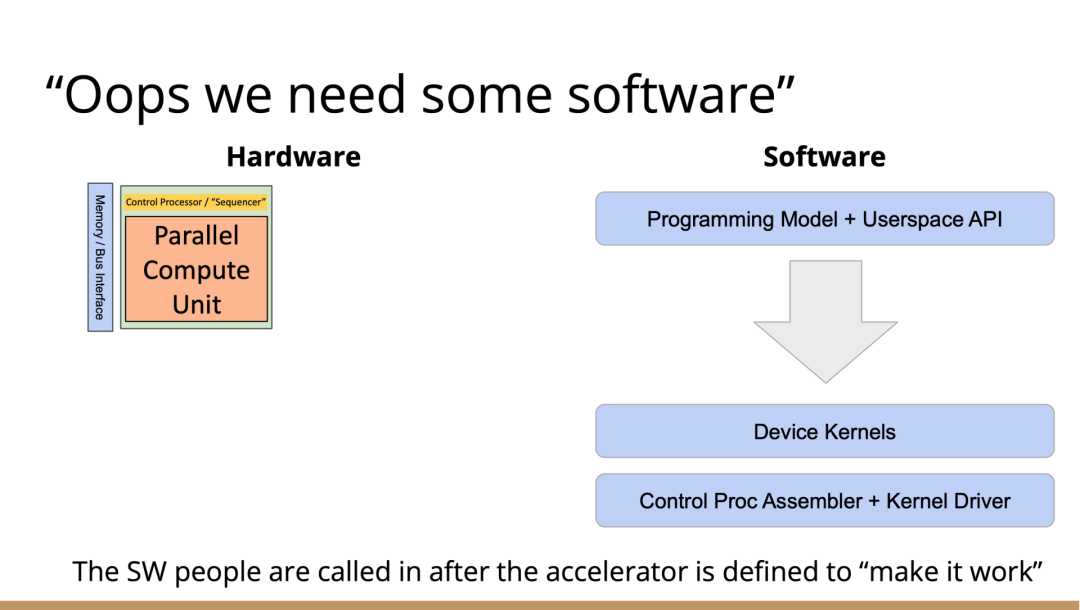
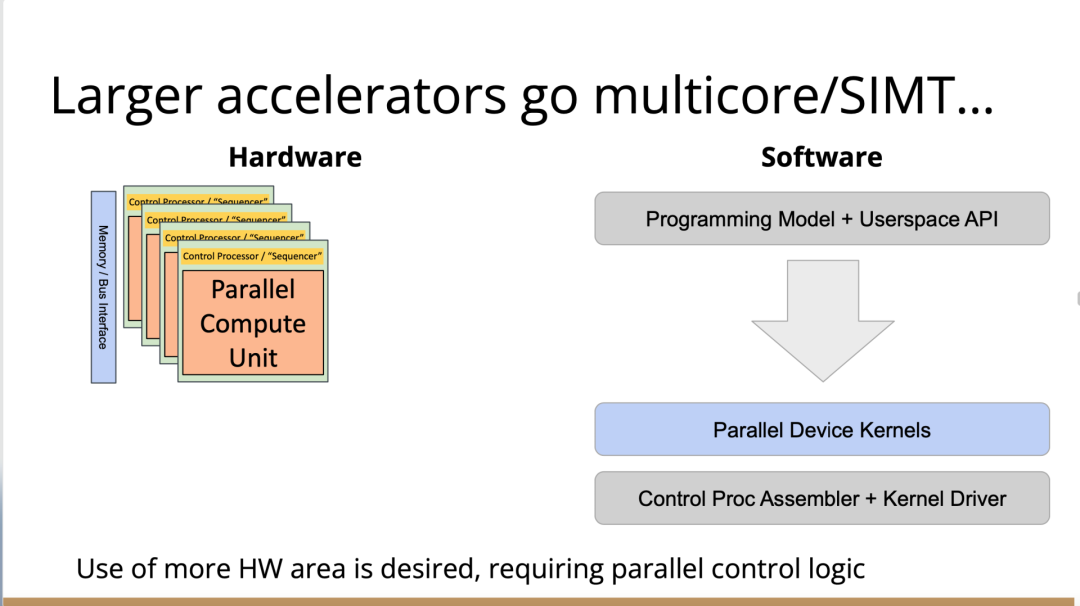
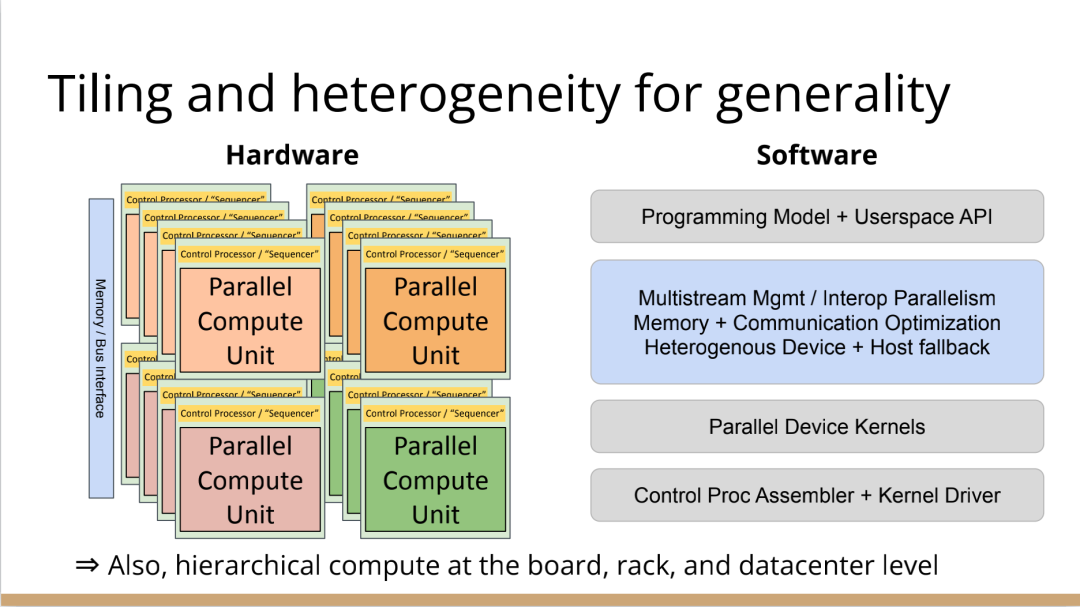
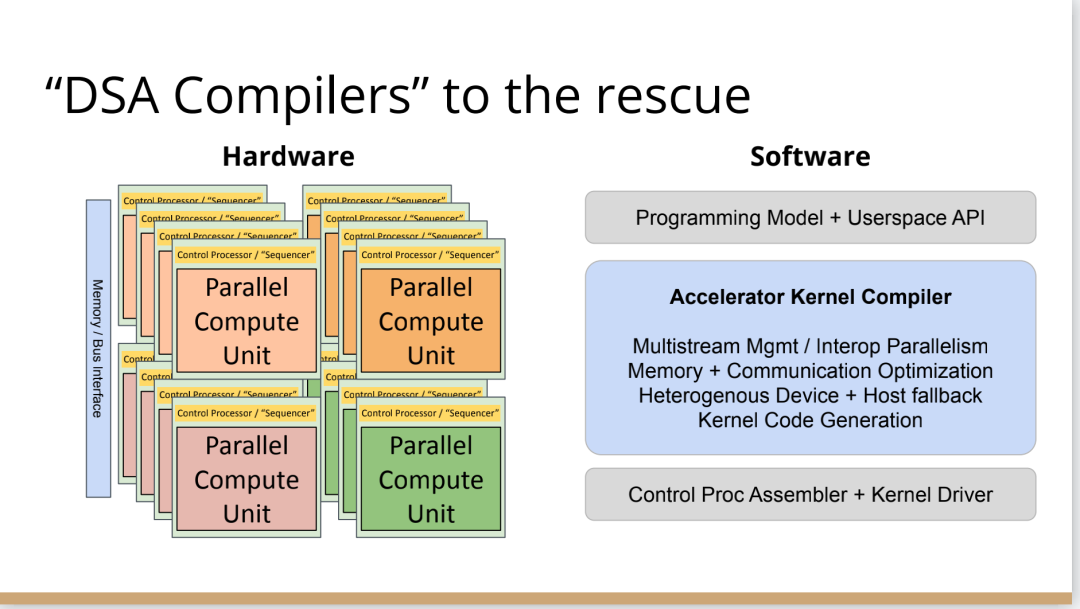
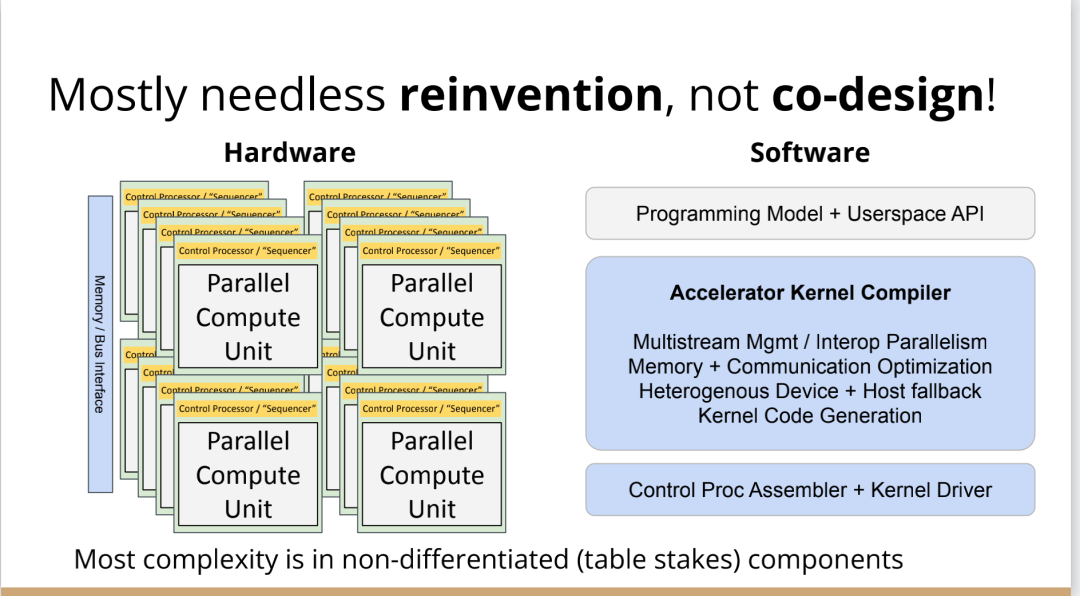
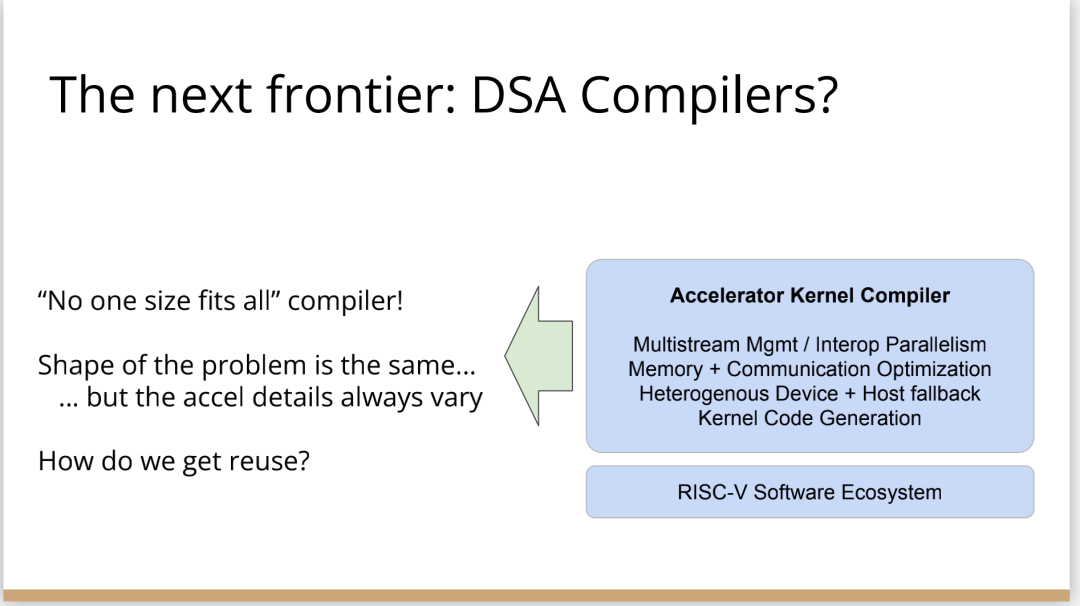
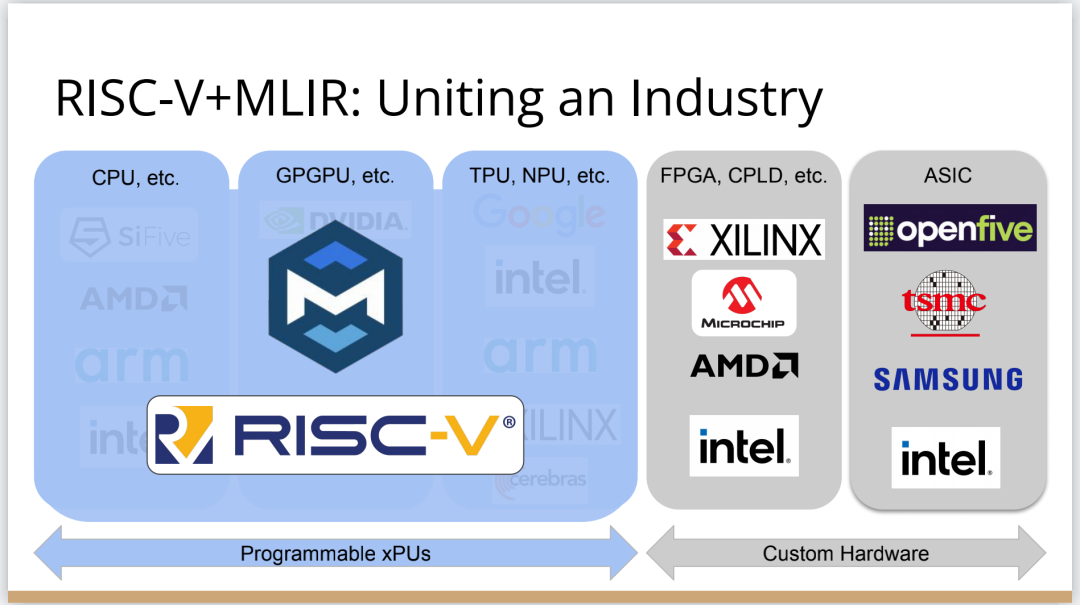
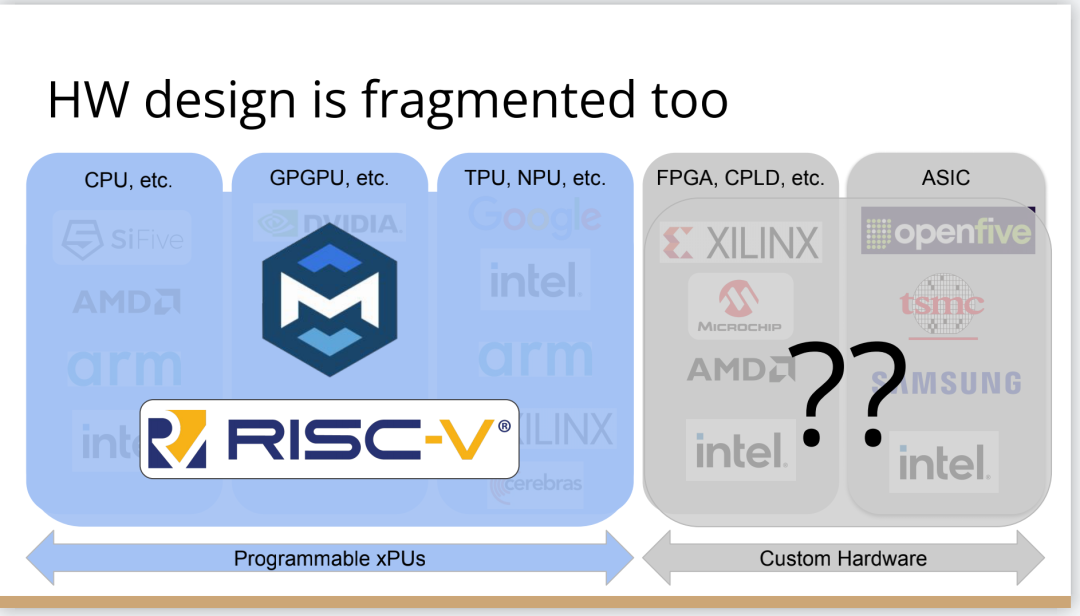
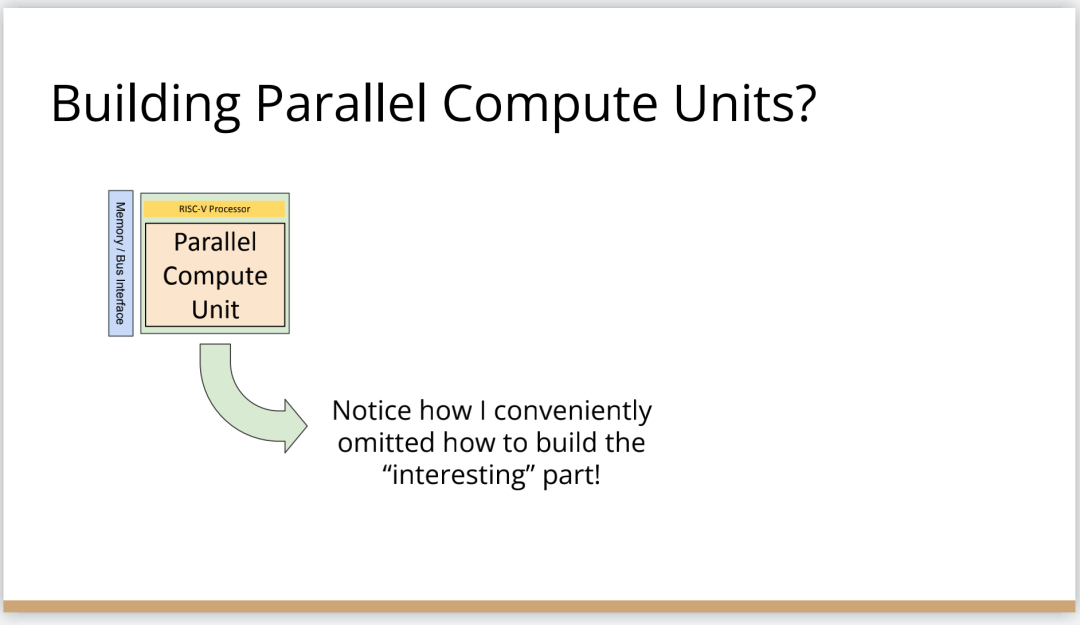
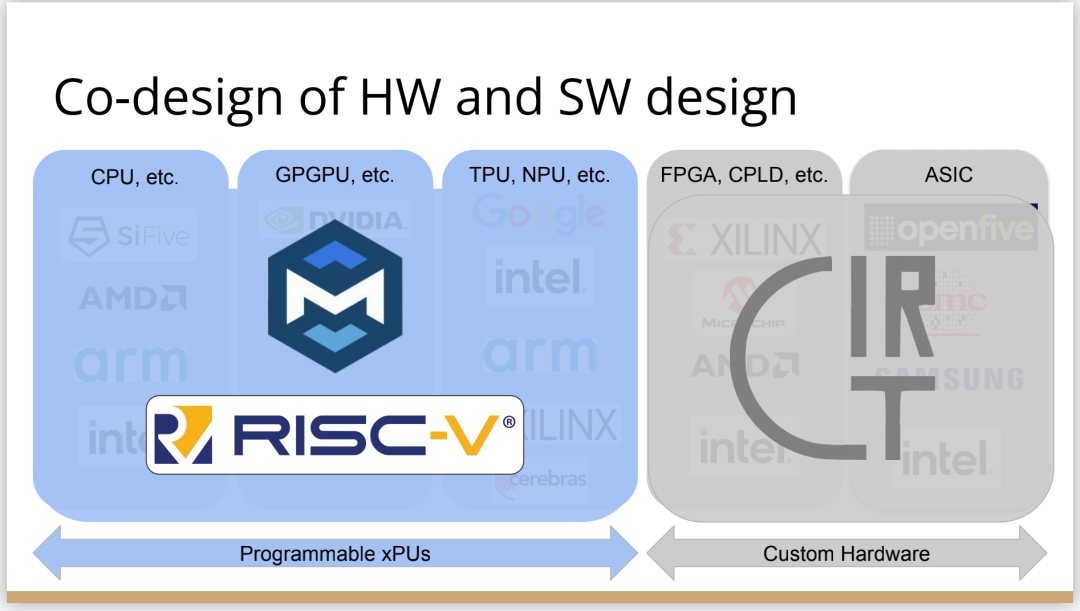
也许你不会感到惊讶,但我认为答案是编译器,这是真正要走的一条路。作为编译器编程语言从业者,我认为硬件设计这个领域已经到了重新评估的地步。整个领域是建立在两种技术之上,但实际上主要是一种叫做Verilog的技术,你大概率可能不喜欢Verilog。它有一个非常复杂的标准,当我看它时,不知道它是被设计成一个IR,也即一个不同工具之间的中间表示,还是被设计成让人们直接书写的东西。我认为,它在这两方面都很失败,它真的很难使用,对工具来说也很难生成。此外,EDA工具、硬件设计工具已经非常成熟,它们非常标准化,有很多大公司正在推动和开发这些工具。但他们的创新速度并不快,设计时并不注重可用性。它们比加速器编译器要差得多,绝对不是以软件架构的最佳实践来构建的,而且成本也非常高。因此,这个领域有巨大的创新机会。我不是第一个认识到这一点的人。在开源社区,已经构建了一堆工具推动行业向前发展。这些工具非常棒,比如Verilator被广泛使用,Yosys是另一个非常棒的工具,它有很好的定理证明器(Theorem Prover)。我的担忧在于,这些工具的理想目标是试图像专有工具一样好,而我并不真的认为专有工具有那么好。另外,这些工具的设计者并没有合作。每个工具都在遵循单一僵化的方法,没有实现大程度的模块化或重复使用,可以从其中一些工具中得到网络列表,用它来解析一些Verilog之类的东西。但是,它不是由基于库的设计构建,与LLVM之类的东西不一样。好消息是,我看到了这里正在发生的不同进展的全面爆发,这与我们一直在谈论的摩尔定律的失效非常相关。我们看到,研究小组正在推动新硬件设计模型的生产,有Bluespec和Chisel等东西。有许多新的不同研究小组在探索不同的硬件设计方法,而且他们最终往往会生成Verilog,这真的很好,因为现在你可以从软件和硬件世界引入新的类型系统方法、编程语言思想、编译器技术。实际上,软件和硬件有很多想法是互通的。只是软、硬件领域用不同的方式说着不同的语言。因此,如果双方能有更多的交集,这对两个行业都有益,这种合作令人惊奇,但他们也遇到了困难,这又回到了这个问题上:Verilog实际上不是一个很好的IR。要创建在语法上正确,并且能表达你想要的东西的Verilog非常困难。此外,因为许多与Verilog有关的工具都有点奇怪,而且很难高质量地预测。生成与工具兼容的Verilog是每个前端工具都必须重新发明的一门黑科技。因此,在堆栈中真的缺失了一种组件,这个组件允许人们在编程模型水平上进行创新,并允许人们找到方法让所有工具都接受它。有一个叫CIRCT的新开源项目正试图解决这个问题。CIRCT的全称是"Circuit IR for Compilers and Tools(编译器和工具的Circuit IR)",它构建在MLIR和LLVM之上。CIRCT社区的目的是提升整个硬件设计世界,促进编程模型的创新,并启用一套新的模块化硬件设计工具。它确实运用了很多我们到目前为止一直在讨论的基于库的技术。 此外,它提供了一个可组合的基于库的工具链,可以建立有趣的新的弹性接口连接,你可以建立Chisel社区正在探索的新编程模型,用它来加速Chisel流程。它带来了很多好处,可以让很多人一起工作,推动不同方式的创新。我们正在建立一个真正伟大的小世界,让关心硬件编译器的人在一起工作,这很有趣。这项工作仍处于早期,目标是更快地构建加速器,让加速器变得更快。我们的大目标是,要把硬件设计和验证过程速度都提高10倍。因此,构建新硬件往往最终需要更多的成本来验证其正确性,这包括形式化方法,相当于单元测试,有很多不同方式可以证明你正在构建的东西在所有情况下都是正确的。这种正确性验证在硬件领域比在软件领域里更复杂,因为硬件领域并没有真正的类型系统,也没有真正的多层次的IR,所以也就不允许将一个状态机表示为一个状态机,并针对它编写证明。现在,正在发生的事情是整个领域被“去掉了糖分(de-sugared)”,变成了基本上没有类型的bits,然后所有的分析和工具都在这个层面上工作,我认为,我们可以通过构建和引入编译器和语言社区中相当知名的技术来迅速提升改善整个领域。因此,我希望我们将能够帮助覆盖整个软件和硬件领域,组合这些标准的开放工具,包括作为指令集的RISC-V,作为编译器堆栈的MLIR,以及作为关注硬件的应用的CIRCT。我们正在努力推动整个行业更快发展。
















 下载APP
下载APP