
论文笔记 | CNN 是怎么学到图片绝对位置信息的
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


昨天读到一篇挺有意思的文章,已经被ICLR2020接收为Spotlight。这个工作解释了CNN是怎么学到图片内的绝对位置信息的。
https://openreview.net/forum?id=rJeB36NKvB
CNN和绝对位置,这两个概念很少被一起讨论。
我觉得有两个原因:一是,大家有一个默认的共识,CNN是平移不变的(对分类任务),或者说平移等变的(对分割和检测任务);二是,没有具体任务上的需求。比如对计算机视觉的三大物体感知任务,分类,分割和检测。物体分类跟位置没关系;语义分割作为像素级语义分类,也不依赖于位置;最有可能和绝对位置有关系的物体检测任务,被主流方法解耦了绝对位置,变成相对于锚框或者锚点进行局部相对位置的回归。这样,网络本身不需要知道物体的绝对位置,位置信息作为人为先验被用在前后处理进行坐标换算。
但是一个很显而易见的观察是,人的视觉系统是可以轻松知道绝对位置的,比如:“左上角有一只鸟,它又飞到右边了”。并且,对图像里的物体来说,本质上是通过位置和形状来区分不同实例的,这点我在之前的一个回答里分享过,感兴趣的同学可以移步这边:
https://www.zhihu.com/question/360594484
所以,我觉得CNN和图片中绝对位置的关系,非常值得进一步讨论。之前有几个相关的思考:
1. 为什么2D实例分割可以直接学每个像素的嵌入向量再进行聚类来区分实例[1]?还能取得不错的效果。按道理,理想情况下,比如在一张很大的图片上,有两个一模一样的人,那在用CNN预测每个像素的嵌入向量的时候,这两个人身上对应位置的像素的嵌入向量会是一样的。这样就导致聚类没办法区分这两个人。而在3D点云中,就没有这个问题。网络和位置的关系就非常自然,因为输入点云本身就包含了位置信息,比如在室内点云分割数据集S3DIS里面,一个场景是一个N个点的点云,每个点用坐标和颜色(x,y,z,r,g,b)来表示,这样输入就是Nx6的矩阵。这也是为什么,在做点云实例分割的时候,直接学每个点的嵌入向量,再进行简单聚类,就能取得很好的效果[2]。
2. 最近做2D实例分割[3]的过程中发现,在不显式的提供像素的绝对位置坐标的情况下,CNN也能学到比较不错的绝对位置相关的输出。当时做实验的时候就觉得很惊讶,其实在CoordConv文章中也有类似的结果,普通conv和CoordConv在处理简单的位置映射任务的时候,是80分和100分的区别,而不是0分和100分的区别。当时和孔涛和沈春华老师讨论,猜想是zero-padding透露了位置的信息,但是没有进一步的实验验证。这个猜想非常自然,因为在网络的训练和测试过程中,所有的外在输入只有两个:输入图片和padding。输入图片没有位置信息,那应该就是padding的影响了。
3. Naiyan老师之前分享的文章[4]里有个结论:在单目深度估计中,CNN可能是通过图像里物体的纵坐标来估计深度的。
以上三点都表明,我们广泛使用的CNN模型是可以学到绝对位置信息的。但是问题是:CNN的这种能力是从哪里得到的?
这篇文章用实验得出了这个结论:
位置信息是zero-padding透露的。
足够大的网络(多层或者大kernel)可以把padding透露的边界信息扩散出去,得到粗糙的全局位置信息。
文章的主要实验设计是,输入图片,训练网络输出位置相关的图片。比如,输入噪声图片,希望网络输出水平坐标图:
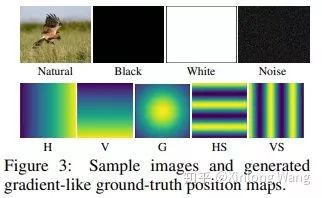
在有zero-padding的情况下,基于VGG和ResNet的模型都可以预测比较合理的位置相关的输出,比如横坐标或者纵坐标。
在没有padding的情况下,输出只会直接响应在输入的内容上,不能预测和内容无关的位置信息:
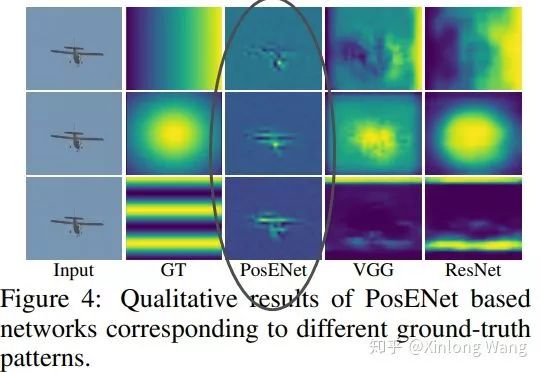
在OpenReview里面,作者还提供了把zero-padding换成circular-padding的实验,结果和没有padding差不多,比zero-padding差很多。说明位置信息确实是从zero-padding带来的。
更多的实验和结论大家可以去读原文,我就不赘述了。
虽然目前的CNN模型可以隐式的学到一定程度的位置信息,但是显然是不充分的。怎样更充分的利用绝对位置信息,非常值得进一步挖掘,CoordConv[5]和semi-conv[6]是很好的探索。
最直接的做法当然就是把每个像素的坐标concat到输入或者中间特征上,这种简单直接做法可以在SOLO[3]的实例分割结果上带来3.6 AP的提升。但是我认为可以有更多方法去进一步充分挖掘图片里的位置信息,期待更多精彩的工作~
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~