
荣耀NLP算法工程师面试题8道|含解析
10本七月在线内部电子书在文末,自取~
公众号福利
👉回复【100题】领取《名企AI面试100题》PDF
👉回复【干货资料】领取NLP、CV、ML等AI方向干货资料


问题1:讲一下transformer
Transformer是一种用于自然语言处理和机器翻译的神经网络模型。它引入了自注意力机制,能够捕捉输入序列中的长距离依赖关系。Transformer由编码器和解码器组成,每个模块都由多个层堆叠而成。编码器用于将输入序列映射到一系列连续表示,解码器则将这些表示转化为输出序列。
问题2:transformer怎么调优
Transformer的调优可以包括以下几个方面:
调整模型架构:可以尝试增加或减少编码器和解码器层的数量,调整隐藏单元的维度等。
学习率调度:使用学习率调度策略,如逐渐减小学习率、使用预热步骤等。
正则化:使用Dropout、权重衰减等正则化技术,防止过拟合。
批量大小和训练迭代次数:调整批量大小和训练迭代次数,以获得更好的训练效果。
初始化策略:选择合适的参数初始化方法,如Xavier初始化、高斯初始化等。
梯度裁剪:为了防止梯度爆炸,可以对梯度进行裁剪,限制梯度的最大范数。
问题3:讲一下CRF,公式是什么
条件随机场(CRF)是一种用于序列标注任务的统计模型。CRF可以建模输入序列和输出序列之间的依赖关系。其公式如下:
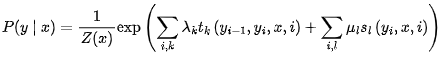 其中,P(y|x)是给定输入序列x的条件下输出序列y的概率,Z(x)是归一化因子,λ_k和u_l是特征函数的权重,t_k和s_l是特征函数,y_i和y_i-1分别表示输出序列的第i个和第(i-1)个标签,N是输出序列的长度,K是标签的数量。
其中,P(y|x)是给定输入序列x的条件下输出序列y的概率,Z(x)是归一化因子,λ_k和u_l是特征函数的权重,t_k和s_l是特征函数,y_i和y_i-1分别表示输出序列的第i个和第(i-1)个标签,N是输出序列的长度,K是标签的数量。
问题4:讲讲word2vec和word embedding区别
Word2Vec是一种用于将单词表示为连续向量的技术,它通过学习上下文信息来为每个单词生成固定维度的向量表示。Word2Vec基于分布式假设,即将上下文相似的单词嵌入到相似的向量空间中。Word2Vec有两种模型:Skip-gram和CBOW(Continuous Bag-of-Words)。Word embedding是指将单词映射到低维度的向量空间的一般术语。Word2Vec是一种用于生成word embedding的具体方法的技术。Word2Vec通过训练一个神经网络模型,从大规模文本语料中学习单词的分布式表示。
区别在于,Word2Vec是一种具体的算法,它是生成word embedding的一种方法。而word embedding是指将单词映射到低维度向量空间的技术,可以使用不同的方法来实现,而不限于Word2Vec。Word2Vec是基于上下文信息的分布式表示方法之一,而word embedding是一个更广泛的概念,涵盖了多种生成单词向量表示的方法,如GloVe、FastText等。
问题5:gpt3和gpt2的区别
GPT-3和GPT-2是由OpenAI开发的两个语言模型。它们的区别主要在于规模和功能上的不同。GPT-3是目前最大的语言模型,具有1750亿个参数,而GPT-2则有15亿个参数。
由于GPT-3规模更大,它在自然语言处理任务上的表现更好,并且能够生成更连贯、更具逻辑性的文本。GPT-3还支持零样本学习,即可以在没有对特定任务进行显式训练的情况下执行各种语言任务。
另一个区别是GPT-3在文本生成方面的能力更强大,可以生成更长的文本,而GPT-2的生成长度有一定的限制。此外,GPT-3的使用需要更高的计算资源和成本。
问题6:讲讲生成模型和判别模型的区别
生成模型和判别模型是两种常见的机器学习模型类型。
生成模型(Generative Model)是指能够学习数据的联合概率分布,并从中生成新的样本。生成模型能够对输入数据进行建模,并学习数据的统计特性,例如生成图像、生成文本等。常见的生成模型包括变分自编码器(VAE)和生成对抗网络(GAN)等。
判别模型(Discriminative Model)则是指通过学习输入数据与标签之间的条件概率分布,来对不同类别进行分类或预测。判别模型关注的是输入与输出之间的关系,能够进行分类、回归等任务。常见的判别模型包括逻辑回归、支持向量机(SVM)和深度学习中的卷积神经网络(CNN)和循环神经网络(RNN)等。
简而言之,生成模型关注数据的生成过程,能够生成新的样本,而判别模型则关注数据的分类或预测问题。
问题7:讲讲LDA算法
LDA(Latent Dirichlet Allocation)是一种用于主题建模的概率图模型。它可以自动地将文本集合划分为多个主题
LDA(Latent Dirichlet Allocation)是一种用于主题建模的概率图模型。它可以自动地将文本集合划分为多个主题,并为每个文档分配主题的概率分布,同时为每个主题分配单词的概率分布。
LDA的基本思想是假设每个文档包含多个主题,并且主题决定了文档中单词的生成过程。具体来说,LDA认为文档的生成过程可以分解为两个步骤:首先,从主题分布中选择一个主题;然后,从选择的主题的单词分布中选择一个单词。通过这种生成过程,可以获得文档中单词的分布,从而推断出主题的分布。
LDA的目标是通过观察到的文本数据来估计主题和单词分布的参数。通常使用基于变分推断或Gibbs采样等方法进行参数估计。一旦得到了主题和单词分布,就可以使用LDA模型来进行主题分析、文本分类、信息检索等任务。
总结来说,LDA是一种无监督学习算法,用于从文本数据中学习主题的概率模型。它可以揭示文本数据的隐含主题结构,并在许多文本处理任务中发挥重要作用。
问题8:有做过NER吗,讲讲prompt learning
"NER"代表命名实体识别(Named Entity Recognition),是指从文本中识别和提取特定类别的命名实体,如人名、地名、组织机构等。"Prompt learning"是一种训练模型的方法,它通过为模型提供一些示例输入和输出对(prompt)来引导模型学习特定的任务。
在NER任务中,prompt learning可以用于训练模型以执行命名实体识别。通常的做法是为模型提供一些示例文本和相应的NER标签作为prompt,然后使用这些prompt进行有监督的训练。通过这种方式,模型可以学习识别文本中的命名实体,并生成相应的标签。
Prompt learning在NER任务中的一个重要应用是零样本学习(zero-shot learning)。零样本学习指的是在没有对特定实体进行显式训练的情况下,通过提示样本的学习,使模型能够识别和分类以前未见过的实体。通过合理设计的prompt,模型可以学习到通用的命名实体识别能力,并在新的实体上进行推断和预测。
总结来说,NER是一项从文本中识别命名实体的任务,而prompt learning是一种训练模型的方法,可以用于引导模型学习NER任务,并在零样本学习中发挥重要作用。
免费送
↓以下10本书电子版免费领,直接送↓


以上8本+《2022年Q4面试题-69道》、《2022年Q3面试题-83道》共10本,
免费送
扫码回复【999】免费领10本电子书
(或
找七月在线其他老师领取
)
点击“
阅读原文
”抢宠粉
福利
~
