
Iceberg 实践 | B站基于 Iceberg 的湖仓一体架构实践
背景
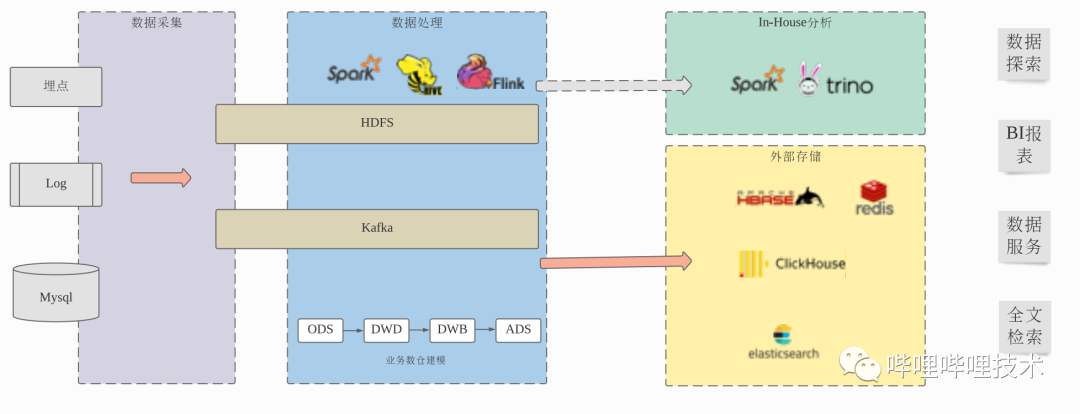
为了提升查询效率,从Hive表出仓到ClickHouse、HBase、Redis、ElasticSearch、Mysql等外部系统中,需要额外的数据开发工作,额外的存储冗余,但同时拥有了更少的数据灵活性,复杂的组件支持增加了数据服务开发的成本,更长的数据处理流程也降低了稳定性和可靠性。 对于未出仓的数据,用户无论是进行数据探索还是使用BI报表,都还受SQL on Hadoop本身性能所限,和用户期望的交互式响应有很大差距。
为什么需要湖仓一体
使用统一的分布式存储系统,可假设为无限容量。 有统一的元数据管理系统。 使用开放的数据存储格式。 使用开放的数据处理引擎对数据进行加工和分析。
自定义的数据存储格式。 自己管理数据的组织方式。 强Schema数据,对外提供标准的SQL接口。 具有高效的计算存储一体设计和丰富的查询加速特性。

B站的湖仓一体架构
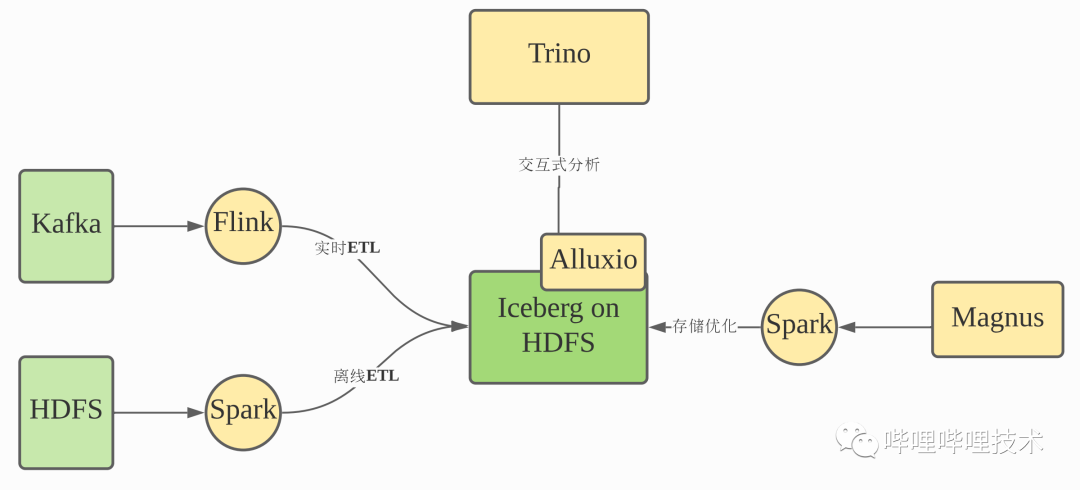
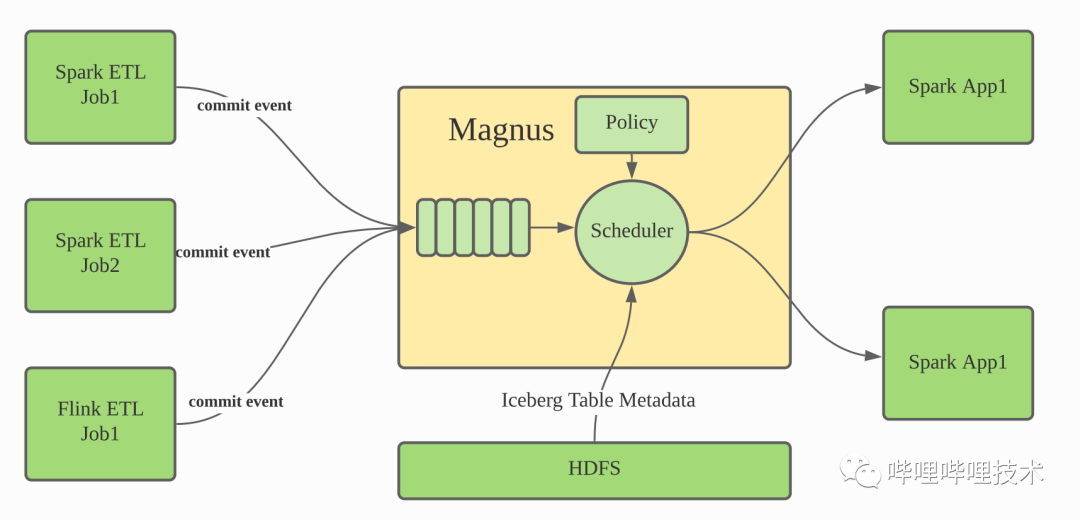
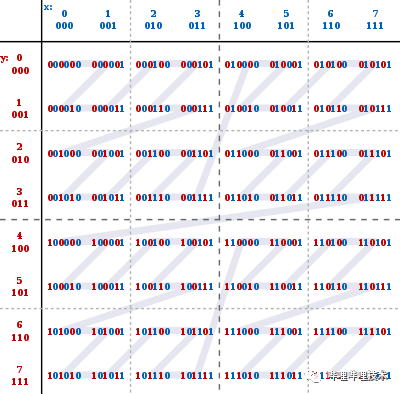
索引
需要存储字段基数对应个BitMap,存储代价太大。
在Range过滤时,使用BitMap判断是否可以Skip文件时,需要访问大量BitMap,读取代价太大。
为了解决以上问题,我们引入了Bit-sliced Encoded Bitmap实现。具体详情可查询参考文献[2](通过索引加速湖仓一体分析)。
总结和展望
星型模型的数据分布组织,支持按照维度表字段对事实表数据进行排序组织和索引。 预计算,通过预计算对固定查询模式进行加速。 智能化,自动采集用户查询历史,分析查询模式,自适应调整数据的排序组织和索引等。
评论