
第二弹!爬虫批量下载高清大图
前言
在上一篇写文没高质量配图?教你python爬虫绕过限制一键搜索下载图虫创意图片!!中,我们在未登录的情况下实现了图虫创意无水印高清小图的批量下载。虽然小图能够在一些移动端可能展示的还行,但是放到pc端展示图片太小效果真的是很一般!建议阅读本文查看上一篇文章,在具体实现不做太多介绍,只讲个分析思路。
当然,本文可能技术要求不是特别高,但可以当作一个下图工具使用。也欢迎讨论交流!
环境:python3+pycharm+requests+re+BeatifulSoup+json

这个确实也属实有一些勉强,不少童鞋私信问我有木有下载大图的源码,我说可能会有,现在分享给大家。
当然对于一个图片平台来说,高质量图片下载可能是其核心业务,并且我看了一下,那些高质量大图下载起来很贵!所以笔者并没有尝试付费下载然后查看大图的地址,因为这个可以猜想成功率很低,并且成本比较高,退而求其次,笔者采取以下几种方法。
对图虫平台初步分析之后,得到以下观点:
原版高质量无水印图片下载太贵,由于没付费下载没有找到高质量图的高清无水印原图真实地址。没有办法(能力) 下载原版高清无水印。并且笔者也能猜测这个是一个网站的核心业务肯定也会层层设套。不会轻易获得,所以并没有对付费高清高质量无水印图片穷追不舍。
但是高质量展示图在预览时候的是可以查看带有水印的高清图的(带着图虫创意水印)。
网站有一些免费的高清大图图片可以获取到。虽然这个
不是精选图,但是质量也还可以!
下载免费共享大图
在图虫创意有个板块的图片是免费开放的。在共享图片专栏。的图片可以搜索下载。
https://stock.tuchong.com/topic?topicId=37 图虫创意url地址

找到一张图片点进去,检查地址你可以直接访问得到。而有相关因素的就是一个图片服务器域名+图片id组成的图片url地址。也就是我们要批量找到这些图片的id。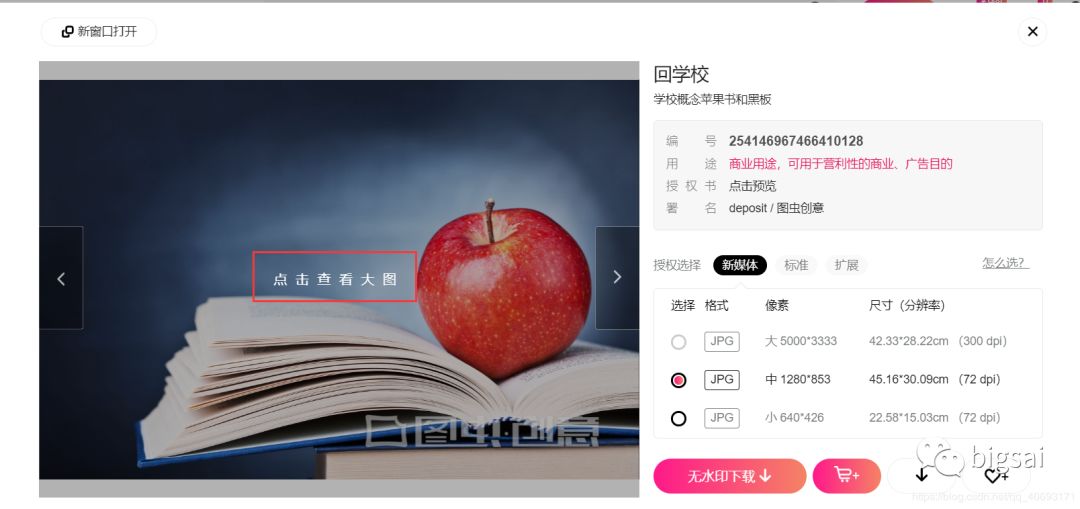
在搜索界面查看源码,发现这个和前面的分析如出一辙,它的图片id藏在js里面。我们只需通过正则解析。拿到id然后拼凑url即可完成所有图片地址,这个解析方式和上文基本完全一致,只不过是浏览器的URL和js的位置有相对的变化只需小量修改,然后直接爬虫下载保存即可!而这个搜索html的url就是https://stock.tuchong.com/free/search/?term=+搜索内容。这个下载内容的实现在上一篇已经分析过。请自行查看或看下文代码!这样

下载带水印的精选图
好的图片都在优选图片专栏。然而这部分图片我们可以免费获取带水印的图片。
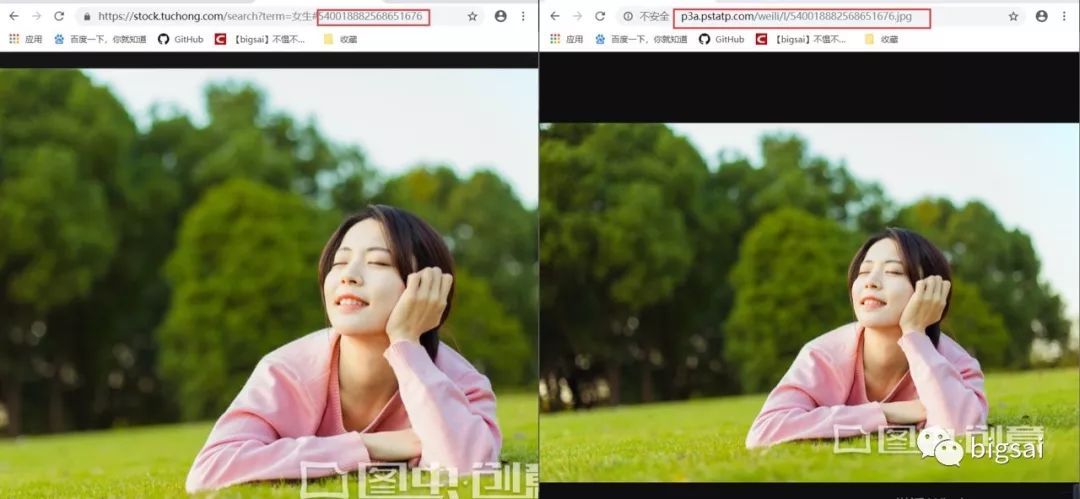
在登录账号之后点开的图片预览,当你点开预览的时候是可以看得到图片的。每张图片对应一个唯一ID,这个地址可以获得但是比较麻烦。我们尝试能不能获得一个简单通用的url地址呢?
经过尝试发现这个图片的url可以在我们上面的免费高清大图url地址共用!也就是我们可以得到这个ID通过上个url来批量获取下载图片!下载图片的方法一致不需要重复造轮子。而id的获取方法我们在下载高清小图就已经详细介绍过了也是一样的。那么分析就已经成功了,代码将在后面给出,这样我们可以下载带水印的高清大图了!
##js的解析规则:
#----
js=soup.select('script') js=js[4]
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js内容
#-------
代码与总结
import requests
from urllib import parse
from bs4 import BeautifulSoup
import re
import json
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Cookie': 'wluuid=66; ',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-encoding': 'gzip, deflate, br',
'Accept-language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'connection': 'keep-alive'
, 'Host': 'stock.tuchong.com',
'Upgrade-Insecure-Requests': '1'
}
def mkdir(path):
import os# 引入模块
path = path.strip()# 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符号
isExists = os.path.exists(path) # 判断路径是否存在 # 存在 True # 不存在 False
if not isExists: # 判断结果
os.makedirs(path)# 如果不存在则创建目录 # 创建目录操作函数
return True#print (path + ' 创建成功')
else:
# 如果目录存在则不创建,并提示目录已存在
#print(path + ' 目录已存在')
return False
def downloadimage(imageid,imgname):##下载大图和带水印的高质量大图
url = 'https://weiliicimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
url2 = 'https://icweiliimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
b=False
r = requests.get(url)
print(r.status_code)
if(r.status_code!=200):
r=requests.get(url2)
with open(imgname+'.jpg', 'wb') as f:
f.write(r.content)
print(imgname+" 下载成功")
def getText(text,free):
texturl = parse.quote(text)
url="https://stock.tuchong.com/"+free+"search?term="+texturl+"&use=0"
print(url)
req=requests.get(url,headers=header)
soup=BeautifulSoup(req.text,'lxml')
js=soup.select('script')
path=''
if not free.__eq__(''):
js=js[1]
path='无水印/'
else:
js=js[4]
path='图虫创意/'
print(js)
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js内容
print(va)
va = va.replace('{', '{').replace('}', '},,')
print(va)
va = va.split(',,,')
print(va)
index = 1
for data in va:
try:
dict = json.loads(data)
print(dict)
imgname='img2/'+path+text+'/'+dict['title']+str(index)
index+=1
mkdir('img2/'+path+text)
imgid=dict['imageId']
downloadimage(imgid,imgname)
except Exception as e:
print(e)
if __name__ == '__main__':
num=input("高质量大图带水印输入1,普通不带水印输入2:")
num=int(num)
free=''
if num==2:
free='free/'
text = input('输入关键词:')
getText(text,free)
这样,整个流程就完成了,对于目录方面,我也对图虫有水印的和没水印的进行了区分,供大家使用。在使用方面,先输入1或2(1代表有水印高质量图,2代表共享图),在输入关键词即可批量下载。


-- end --
喜欢就三连呀
点击"阅读原文"可跳转至我的博客。
关注 Stephen,一起学习,一起成长。