13年底,负责数据库中间件的设计,当时的设计文档,拿出来和大家分享:数据库中间层项目背景不再展开,根据前期的调研以及和公司同事的讨论,中间层的核心目标主要有两个:(1)db虚拟化:让db对业务线透明(本文的db均指mysql),业务线不再需要知道db的真实ip,port,主从关系,读写关系,高可用等;(2)无限容量(分库)的支持:让db的分库对业务线透明;上述目标相对比较宽泛,具体来说,数据库中间层需要实现以下功能。db1.58.com:3306
db2.58.com:3306
im.58.com:3306
jiaoyou.58.com:3306
db.58.com:3306
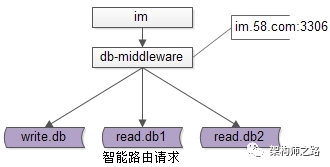
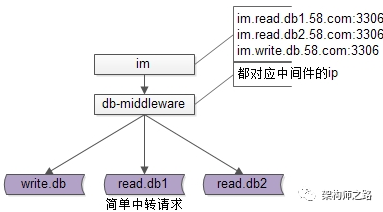
所有的业务线,对db的访问,都只有一个入口,由数据库中间层来进行权限验证,由中间件来路由请求,这是一种完美的情况。当然,统一一个总入口目标有点宏大,可以循序渐进,先各业务线统一读写访问入口,故折衷的目标可以是,从今以后,不再有im.read.db1.58.com:3306
im.read.db2.58.com:3306
im.write.db.58.com:3306
im.58.com:3306
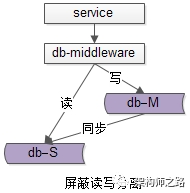
im业务对db的访问,统一到一个入口上来了,由中间层来对请求进行智能路由。更简化的,甚至可以初期同一个业务线的db读写都不对业务线透明,数据库中间层只做简单的请求转发,先初步的把数据库访问入口收拢到数据库中间层来,为后续的统一,再统一打下基础。(2.1)手工用mysql客户端连mysql,直连数据库执行命令;(2.3)c/c++使用libmysqlclient.a来对mysql进行访问;所谓保持访问接口,是指上游对数据库的访问接口完全不用变,中间件服务对上游来说,就是数据库。由于SQL协议是非常复杂的,在db的客户端与服务器插入了一个中间层之后,不一定能对所有的SQL功能都进行支持,支持哪些SQL是需要慎重考虑的。业务层不需要在关注读写分离,由中间件来进行读写请求路由。58的db的水平扩展,基本是用的分库的方式(分库比较好,很容易实现实例的扩容),即:db1.table
db2.table
db3.table
db4.table
这样的话,dao层对于table就只有一个table实例了,比较方便。根据前期与各业务线同学的沟通,58在分库上的业务访问需求为(这个调研的周期比较长,和很多业务线进行了沟通):故对分库上的分布式SQL功能,数据库中间层只需要支持上上述四项即可。第一部分,故障自动发现:下游数据库挂了,能够自动发现问题,并报警周知相关人员。
(5.1)主库挂了,能够自动切换,或者屏蔽写请求;(5.2)从库挂了,能够自动自动切换读请求量流量;(5.3)中间件挂了,自动切换中间件流量,高可用;
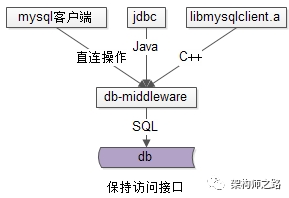
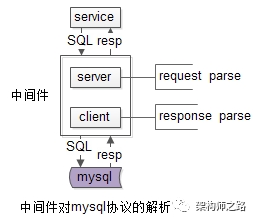
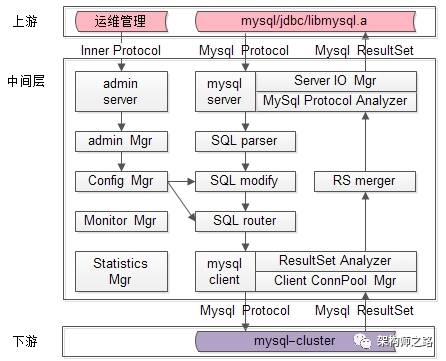
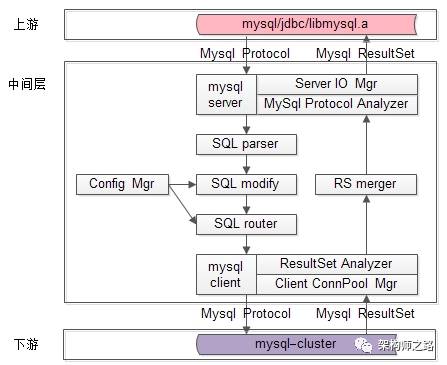
however,只要总的框架设计具备可扩展性,这些功能可以循序渐进,逐步添加。既然选择了mysql client server protocol作为业务层与中间层之间的协议,那么中间层必然是作为mysql-server接收上游的请求,作为mysql-client向真正的mysql发送请求的,中间层的整体结构如下:这样的话,需要对mysql client server protocol做详尽的研究,了解:协议这一块的掌握必须详尽,好在官方文档相对比较全面:http://dev.mysql.com/doc/internals/en/client-server-protocol.html - mysql客户端,java使用jdbc作为上游连接,c/c++使用libmysql.a作为上游连接,使用的是Mysql Client Server协议 - DBA亦可以向中间件发送一些管理命令,或者查看一些统计信息,使用的是自己定义的内部协议处于系统体系结构中的最后端,系统中间件的下游就是mysql集群了,中间件与mysql之间使用的也是Mysql Client Server协议。中间层配置文件管理组件ConfigMgr是中间层中非常重要的一个部分,请求的转发,读写分离,分库功能的支持,都需要通过配置来完成。<mysql>
<db id=0 logic_db="im"type=1>
<item ip="10.58.1.100" port=3306 name="im" />
</db>
<db id=1 logic_db="umc"type=2 patition_count=2 key="uid" hash="mod">
<patition id=0>
<item ip="10.58.1.100" port=3306 role="w" />
<item ip="10.58.1.101" port=3306 role="r" />
<item ip="10.58.1.102" port=3306 role="r" />
</patition>
<patition id=1>
<item ip="10.58.1.100" port=3316 role="w" />
<item ip="10.58.1.101" port=3316 role="r" />
<item ip="10.58.1.102" port=3316 role="r" />
</patition>
</db>
</mysql>
从配置文件可以看出,ConfigMgr需要管理的mysql配置类型有两种:<db id=0 logic_db="im"type=1>
<item ip="10.58.1.100" port=3306 name="im" />
</db>
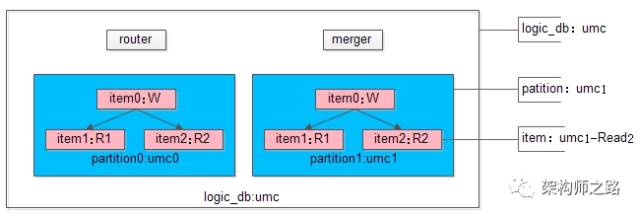
配置的含义是,上游如果访问逻辑数据库logic_db=”im”,中间件则将请求转发到实际的后端数据库item,item中配置了后端数据库的ip/port/name。解释分库支持的配置之前,先说明一下数据库的层次结构LOGIC_DB、PARTITION、ITEM。LOGIC_DB:逻辑数据库,面向上游,例如umcPARTITION:数据库分区,可以理解为分库,例如umc0和umc1,这个对上游是透明的ITEM:数据库项,可以理解为一个分区上的一个读库或者写库,这个对上游也是透明的<db id=1 logic_db="umc"type=2 patition_count=2 key="uid" hash="mod">
<patition id=0>
<item ip="10.58.1.100" port=3306 role="w" />
<item ip="10.58.1.101" port=3306 role="r" />
<item ip="10.58.1.102" port=3306 role="r" />
</patition>
<patition id=1>
<item ip="10.58.1.100" port=3316 role="w" />
<item ip="10.58.1.101" port=3316 role="r" />
<item ip="10.58.1.102" port=3316 role="r" />
</patition>
</db>
- LOGIC_DB:需要关注partition-key-column,也需要关注partition算法,它要实现对PARTITION的请求路由以及结果集的汇总 - PARTITION:需要关注ITEM的读写特性,它要实现对ITEM的读写分离 - ITEM:是最终的数据库,和它相关的配置是数据库ip/port/name/wr-type中间层服务端组件MysqlServerPart是中间层中非常重要的一个部分,它负责端口的监听+请求接收与返回(服务端网络IO),MysqlProtocol的解析。根据其功能,MysqlServerPart组件又主要分为两个组件ServerIOMgr组件(服务端IO管理),MysqlProtocolAnalyzer组件(Mysql协议分析)。 - server网络框架的选取:建议使用异步server - 并发模型的选取:建议使用IO-thread + multi-work-thread的并发模型 - 连接上下文管理,最容易想到的上下文,一个数据库连接是和一个逻辑库LOGIC_DB绑定的 - Mysql如何建立数据库连接:需要考察Mysql协议 - Mysql协议的细化解析:需要考察Mysql协议中间层客户端组件MysqlClientPart是中间层中非常重要的一个部分,它负责中间件对mysql的连接池管理,以及返回结果集的解析。根据其功能,MysqlClientPart组件又主要分为两个组件ClientConnPoolMgr组件(客户端连接池管理),ResultSetAnalyzer组件(返回结果集分析)。 - 连接上下文管理,最容易想到的上下文,一个数据库连接是和一个ITEM绑定的 - Mysql结果集的细化解析:需要考察Mysql协议中间层Sql分析组件SqlParser是中间层中非常重要的一个部分,它负责对sql语句的语法分析与语义分析。为什么要进行Sql语法语义分析?需要解析出什么东东?对于请求的中转,上游一个数据库连接对应一个逻辑库LOGIC_DB,由ConfigMgr可以知道对应下游一个真实的ITEM(ip/port/db),此时直接转发请求即可,无需解析Sql语句。对于分库的支持,解析Sql语句可能需要得到这些问题的答案:Sql是否带了partition-key-column?partition-key-column的值是多少?例如一条Sql语句:select * from user where uid=123456;就必须将“uid”列属性,以及uid的列属性值“123456”解析出来,以用作后续请求路由。注意:更细的情况是,针对每个表,分库partition-key-column都是不一样的,上例中还需要将表名user也解析出来。 - 如何解析Sql语句:可以参考mysql源码对SQL语句的解析,亦可参照cober对SQL语句的解析方法;注:由于我们只需要支持多库,数据库库名信息是在“连接”这一层获取的,又我们支持的分布式Sql的种类有限,故只需解析partition-key-column,offset/limit等少数信息即可。
中间层Sql修改组件SqlModifier是中间层中非常重要的一个部分,它负责对sql语句改写。type=1的请求转发,无需修改Sql,但对于type=2的分库支持,有些Sql语句就必须进行改写。例如:select * from user where uid in(1,2,3,4,5,6);假设PARTITION分了0和1奇偶两个分区,则sql应该分别被改写为:select * from user where uid in(2,4,6); => 路由给0库;select * from user where uid in(1,3,5); => 路由给1库;又例如:select * from user limit 1000,10;select * from user limit 0,1010; => 分别路由到两个库,收集完结果集共2020条记录,再排序取其中1000-1010这10条。只有(2)和(4)两项需要改写,改写方法上文已述,其中(4)的改写效率较低,使用起来要谨慎。中间层Sql路由组件SqlRouter是中间层中非常重要的一个部分,它负责对sql语句进行路由。只有(1)和(2)两项需要路由,(3)和(4)需要将请求分发至所有的PARTITION。中间层结果集合并组件ResultSetMerger是中间层中非常重要的一个部分,它负责对结果集进行合并,筛选。其中(2)和(3)类查询需要将结果集进行合并,(4)不但要合并结果集,还需要将结果集在本地进行排序,然后再筛选出真正的结果集。 - AdminServer:监听一个新端口,接收数据库管理员命令的server - StatisticsMgr:实现数据统计功能的组件上述组件可循序渐进,逐步添加,故一期需要实现的组件及架构图为:感谢看完,说明你对数据库中间件感兴趣,希望大家有,谢转。