
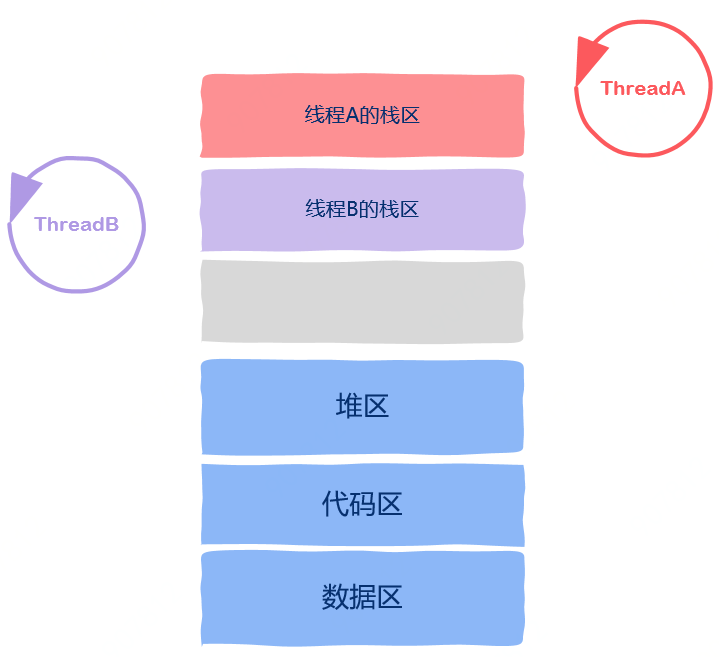
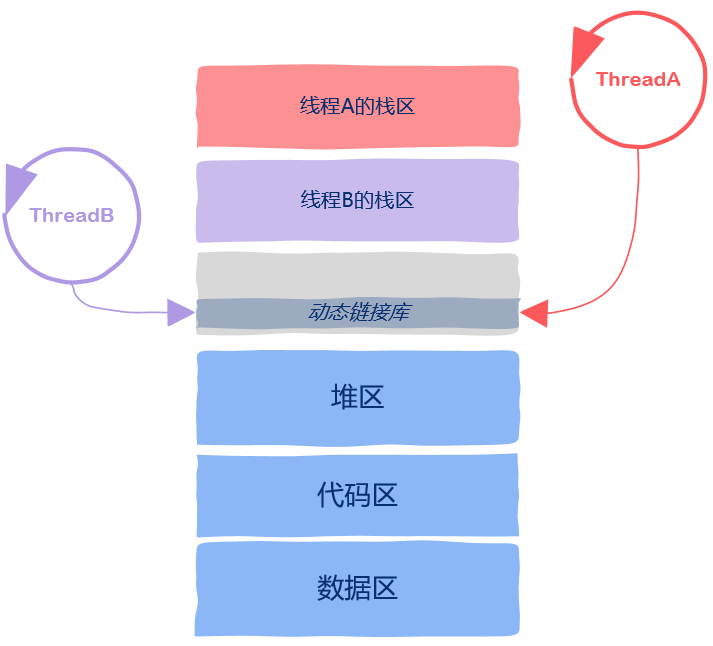
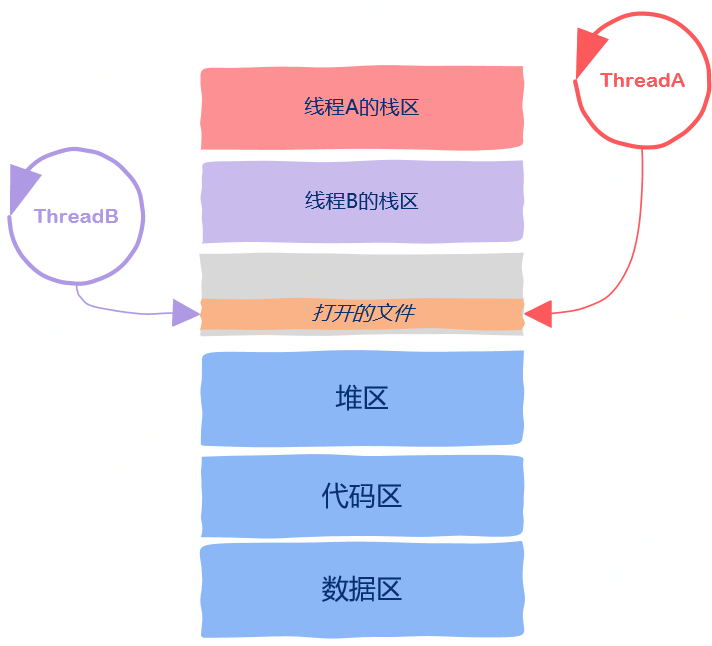
线程间到底共享了哪些进程资源?
记住了不一定真懂
逆向思考
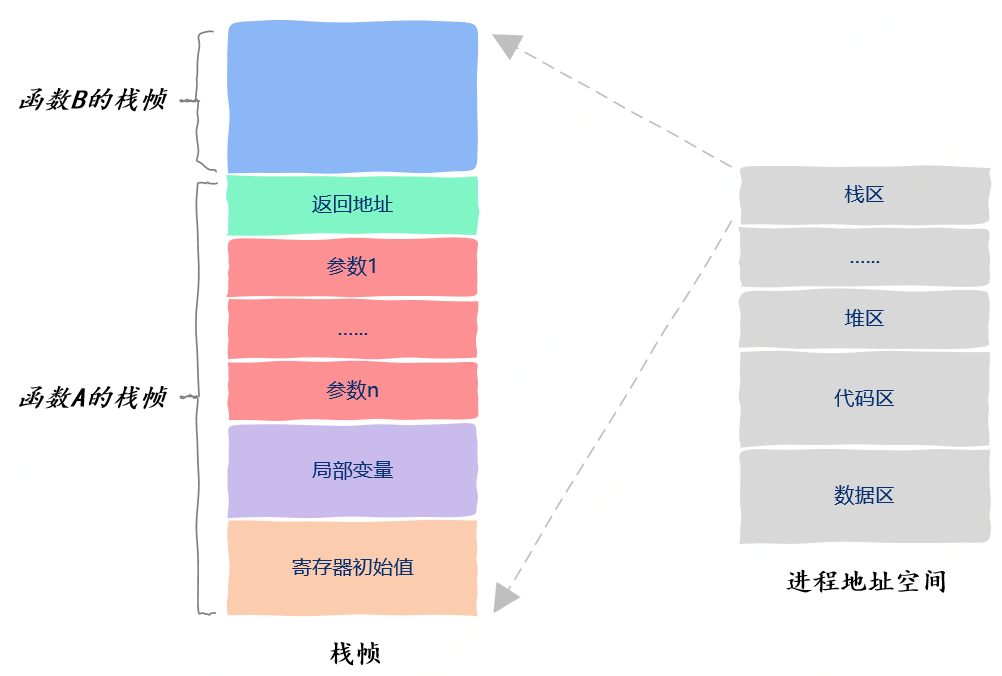
线程私有资源
代码区
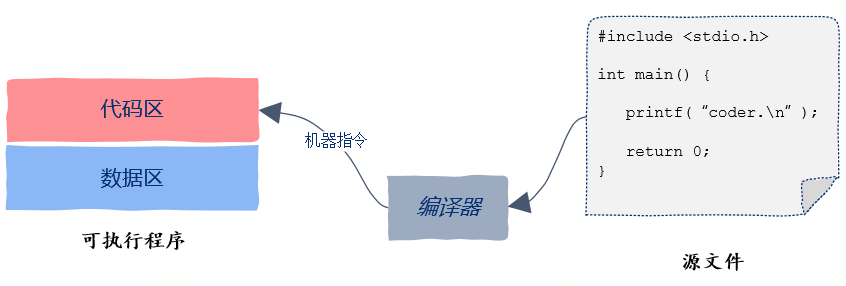
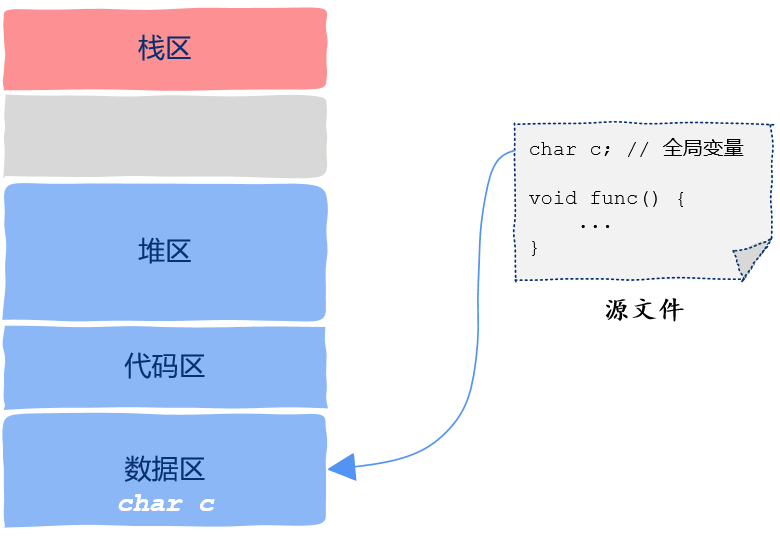
数据区
char c; // 全局变量void func() {}
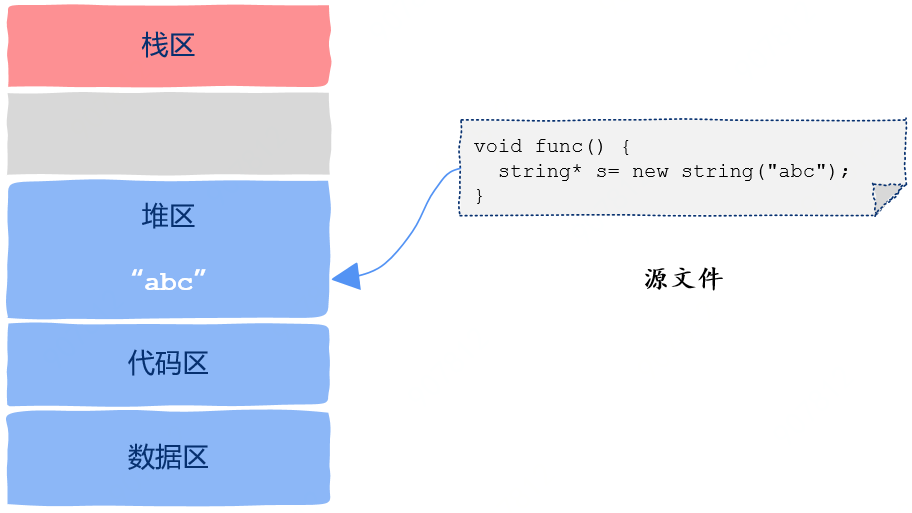
void func(){static int a = 10;}
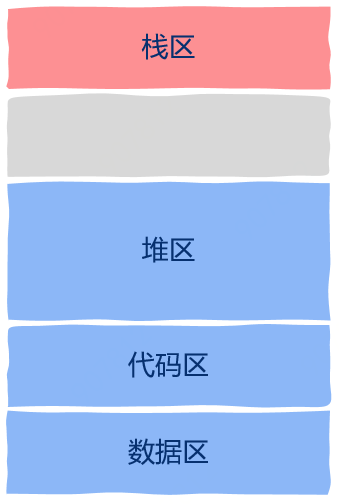
堆区
栈区
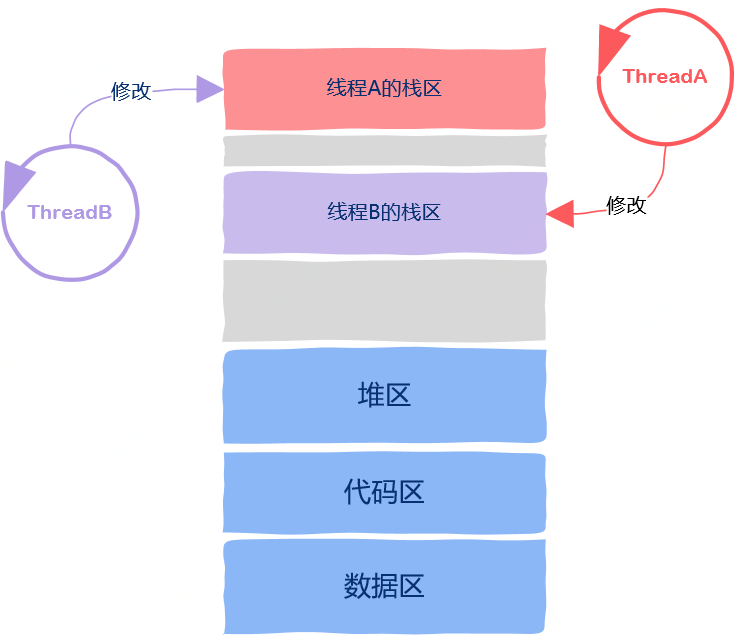
修改线程私有数据
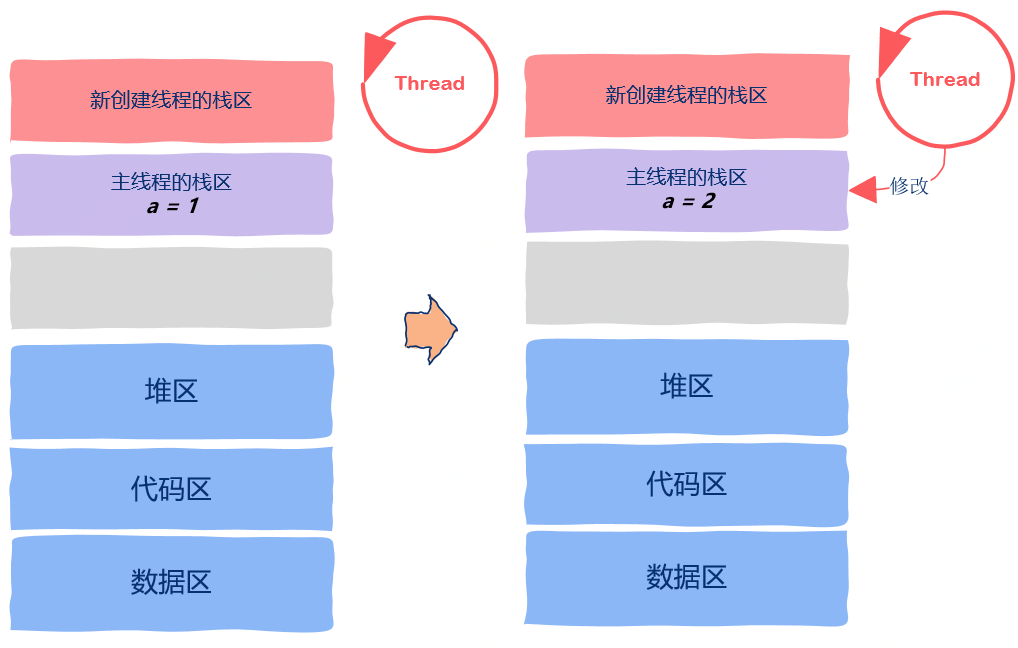
void thread(void* var) {int* p = (int*)var;*p = 2;}int main() {int a = 1;pthread_t tid;pthread_create(&tid, NULL, thread, (void*)&a);return 0;}
动态链接库
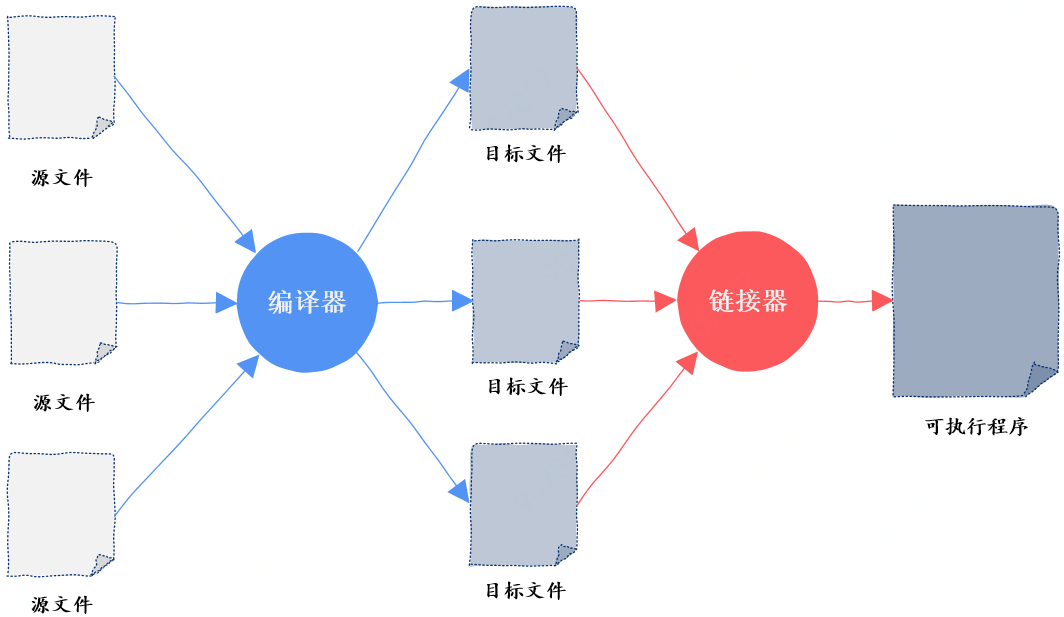
文件
One More Thing:TLS
 。
。存放在该区域中的变量是全局变量,所有线程都可以访问
虽然看上去所有线程访问的都是同一个变量,但该全局变量独属于一个线程,一个线程对此变量的修改对其他线程不可见。
int a = 1; // 全局变量void print_a() {cout<}void run() {++a;print_a();}void main() {thread t1(run);t1.join();thread t2(run);t2.join();}
首先我们创建了一个全局变量a,初始值为1 其次我们创建了两个线程,每个线程对变量a加1 线程的join函数表示该线程运行完毕后才继续运行接下来的代码
23
__thread int a = 1; // 线程局部存储22
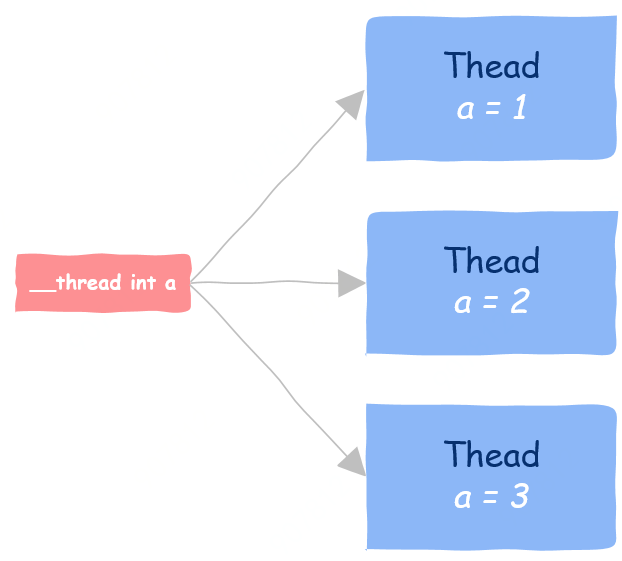
总结

评论