
美团分布式服务治理框架OCTO之二:Mesh化
写在前面
前面的文章主要介绍了美团Octo服务治理框架,随着云原生的崛起,大量服务治理体系普遍“云原生”化,而Mesh则是云原生中非常重要的一个流派,今天我们看下美团的Octo是如何一步步的Mesh化的。
Mesh化
经过一整套服务治理能力的升级,原有Octo已经支持了,包括set化、链路级复杂路由、全链路压测、鉴权加密、限流熔断等治理能力。
但整个治理体系仍存在一些痛点及挑战:
多语言支持不友好:每一个语言搞一套治理体系不现实
中间件和业务绑定在一起,彼此制约迭代:原有的一些治理能力是通过入侵业务代码实现的,比如filter、api、sdk集成等,只是做到了逻辑隔离,未做到物理上的隔离。一般来说核心的治理能力主要由通信框架承载,如果没有更进一步的隔离(如物理隔离),那中间件引入的bug就需要所有业务配合升级,对业务研发效率造成伤害
治理决策比较分散:每个节点根据自己的状态进行决策,无法与其他节点协同仲裁
针对于以上问题,Octo升级到2.0架构,引入了Mesh概念。
Mesh模式下,为每个业务实例部署一个Sidecar代理,所有进出应用的业务流量统一由Sidecar承载,同时服务治理的工作也由Sidecar执行,所有的Sidecar由统一的中心化大脑控制面进行全局管控。
做好Mesh化升级,怎么解决上面的痛点的呢:
Service Mesh 模式下,各语言的通信框架一般仅负责编解码,而编解码的逻辑往往是不变的。核心的治理功能(如路由、限流等)主要由 Sidecar 代理和控制大脑协同完成,从而实现一套治理体系,所有语言通用。
中间件易变的逻辑尽量下沉到 Sidecar 和控制大脑中,后续升级中间件基本不需要业务配合。SDK 主要包含很轻薄且不易变的逻辑,从而实现了业务和中间件的解耦。
新融入的异构技术体系可以通过轻薄的 SDK 接入美团治理体系(技术体系难兼容,本质是它们各自有独立的运行规范,在 Service Mesh 模式下运行规范核心内容就是控制面和Sidecar),目前美团线上也有这样的案例。
控制大脑集中掌控了所有节点的信息,进而可以做一些全局最优的决策,比如服务预热、根据负载动态调整路由等能力。
总结起来:尽量将治理能力与业务逻辑剥离开来,通过轻量级的SDK与业务逻辑耦合,但这一部分设计需要尽量轻薄,更多治理能力下沉到SideCar与控制大脑。
整体架构
Octo2.0整体架构如下:
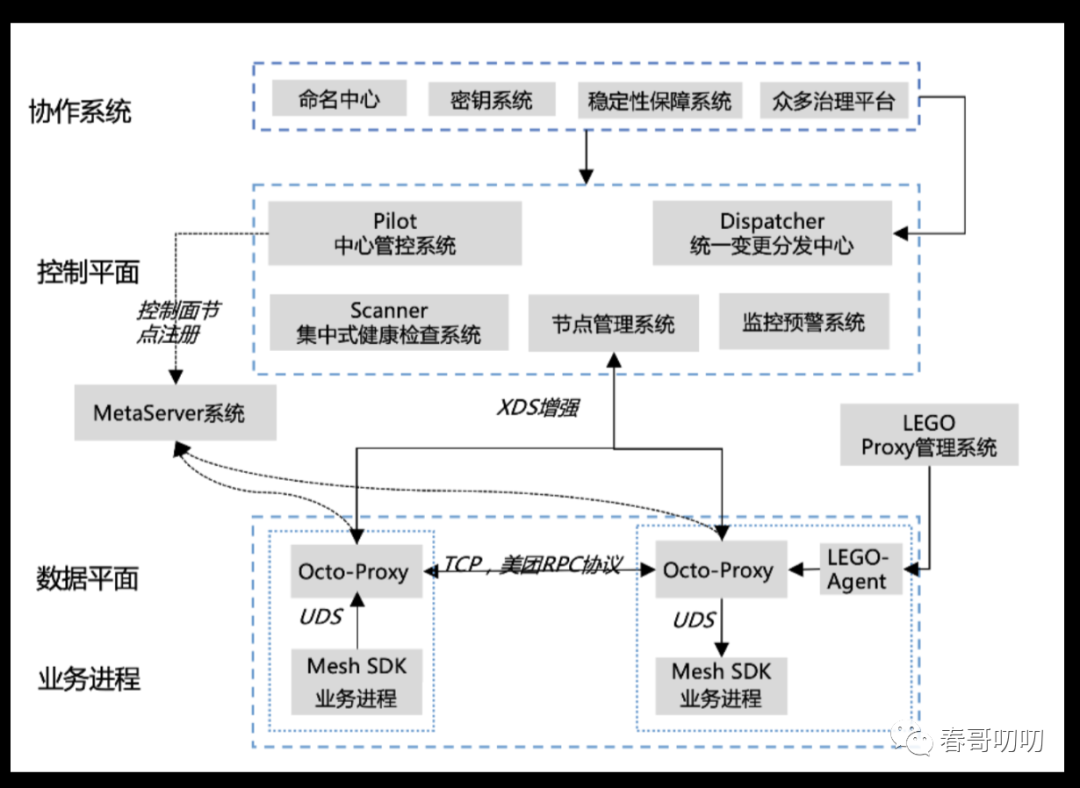
协作系统包括服务治理系统、鉴权服务、配置中心、限流服务等,这些原有服务治理能力在Mesh架构下是可复用的,无需重复开发。
Mesh的技术选型
美团的Mesh改造起步于2018年底,当时的一个核心问题是整体方案的考量应该关注于哪几个方面。
启动计划阶段时,有了一些非常明确的关注点:
Octo体系经过五年的迭代,形成了一系列的标准与规范,进行Mesh改造治理体系升级范围会非常大,在确保技术方案可以落地的同事,也要屏蔽技术升级对于业务改动
治理能力不能减弱,在保障对齐的基础上逐渐提供更精细、更易用的运营能力
可以应对超大规模的挑战,技术方案需要确保支撑当前两级甚至N倍的增量,系统自身不能成为整个治理体系的瓶颈
尽量与社区保持亲和,一定程度上和社区协同演进
于是产出了如下的技术选型方案:

于是选择了一种数据层面基于Envoy二次开发,控制码自研的整体选型与方案。
数据面方面,当时 Envoy 有机会成为数据面的事实标准,同时 Filter 模式及 xDS 的设计对扩展比较友好,未来功能的丰富、性能优化也与标准关系较弱。
控制面自研为主的决策需要考量的内容就比较复杂,总体而言需要考虑如下几个方面:
美团容器化主要采用富容器的模式,这种模式下强行与 Istio 及 Kubernetes 的数据模型匹配改造成本极高,同时 Istio API也尚未确定。
Istio 在集群规模变大时较容易出现性能问题,无法支撑美团数万应用、数十万节点的的体量,同时数十万节点规模的 Kubernetes 集群也需要持续优化探索。
Istio 的功能无法满足 OCTO 复杂精细的治理需求,如流量录制回放压测、更复杂的路由策略等。
项目启动时非容器应用占比较高,技术方案需要兼容存量非容器应用。
整体Mesh方案如下:
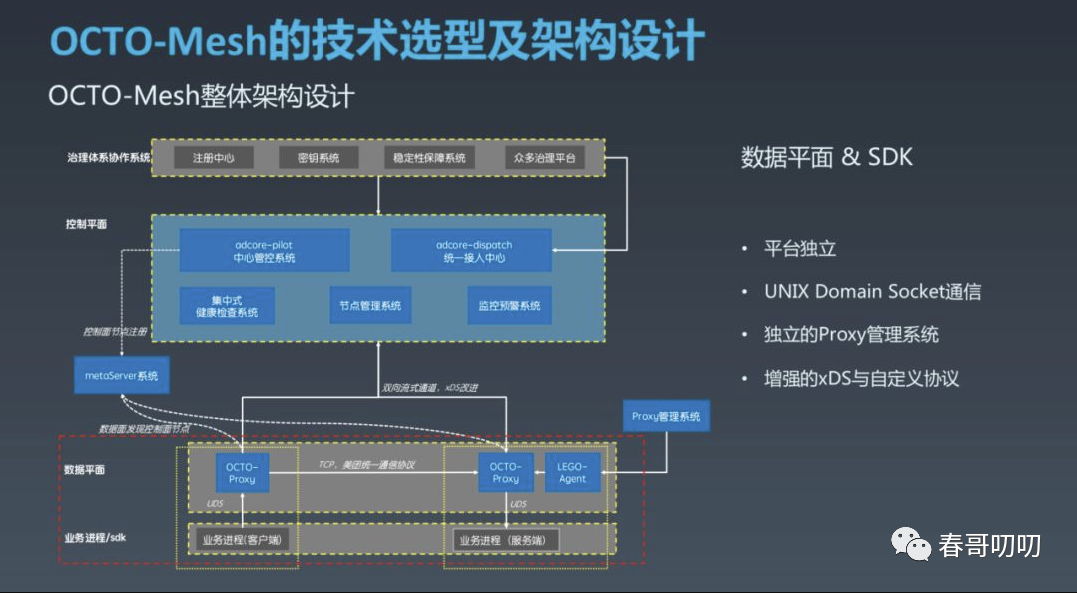
这张图展示了 OCTO Mesh 的整体架构。从下至上来看,逻辑上分为业务进程及通信框架 SDK 层、数据平面层、控制平面层、治理体系协作的所有周边生态层。
先来重点介绍下业务进程及SDK层、数据平面层:
OCTO Proxy (数据面Sidecar代理内部叫OCTO Proxy)与业务进程采用1对1的方式部署。
OCTO Proxy 与业务进程采用 UNIX Domain Socket 做进程间通信(这里没有选择使用 Istio 默认的 iptables 流量劫持,主要考虑美团内部基本是使用的统一化私有协议通信,富容器模式没有用 Kubernetes 的命名服务模型,iptables 管理起来会很复杂,而 iptables 复杂后性能会出现较高的损耗。);OCTO Proxy 间跨节点采用 TCP 通信,采用和进程间同样的协议,保证了客户端和服务端具备独立升级的能力。
为了提升效率同时减少人为错误,我们独立建设了 OCTO Proxy 管理系统,部署在每个实例上的 LEGO Agent 负责 OCTO Proxy 的保活和热升级,类似于 Istio 的 Pilot Agent,这种方式可以将人工干预降到较低,提升运维效率。
数据面与控制面通过双向流式通信。路由部分交互方式是增强语义的 xDS,增强语义是因为当前的 xDS 无法满足美团更复杂的路由需求;除路由外,该通道承载着众多的治理功能的指令及配置下发,我们设计了一系列的自定义协议。
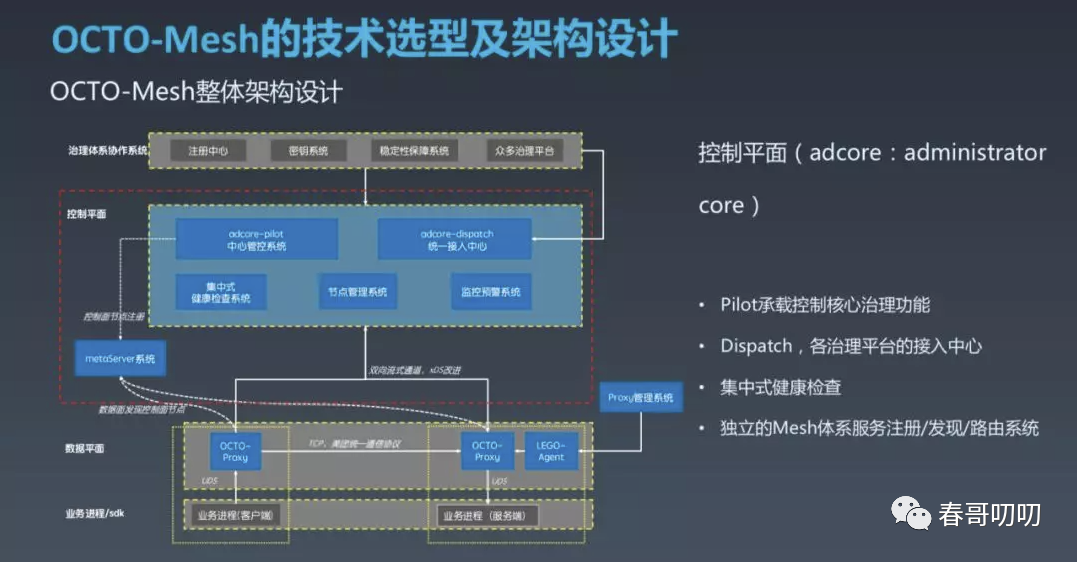
控制面(美团内部名称为Adcore)自研为主,整体分为:Adcore Pilot、Adcore Dispatcher、集中式健康检查系统、节点管理模块、监控预警模块。此外独立建设了统一元数据管理及 Mesh 体系内的服务注册发现系统 Meta Server 模块。
每个模块的具体职责如下:
Adcore Pilot 是个独立集群,模块承载着大部分核心治理功能的管控,相当于整个系统的大脑,也是直接与数据面交互的模块。
Adcore Dispatcher 也是独立集群,该模块是供治理体系协作的众多子系统便捷接入 Mesh 体系的接入中心。
不同于 Envoy 的 P2P 节点健康检查模式,OCTO Mesh 体系使用的是集中式健康检查。
控制面节点管理系统负责采集每个节点的运行时信息,并根据节点的状态做全局性的最优治理的决策和执行。
监控预警系统是保障 Mesh 自身稳定性而建设的模块,实现了自身的可观测性,当出现故障时能快速定位,同时也会对整个系统做实时巡检。
与Istio 基于 Kubernetes 来做寻址和元数据管理不同,OCTO Mesh 由独立的 Meta Server 负责 Mesh 自身众多元信息的管理和命名服务。
实现原理
我们看下核心Mesh架构实现原理。
流量劫持
Octo并未采用Istio的原生方案,而是使用iptables对进出POD的流量进行劫持:
iptables自身存在性能损失大、管控性差的问题:
iptables在内核对于包的处理过程中定义了五个“hook point”,每个“hook point”各对应到一组规则链,outbond流量将两次穿越协议栈并且经过这5组规则链匹配,在大并发场景下会损失转发性能。 iptables全局生效,不能显式地禁止相关规则的修改,没有相关ACL机制,可管控性比较差。 在美团现有的环境下,使用iptables存在以下几个问题:
HULK容器为富容器形态,业务进程和其他所有基础组件都处于同一容器中,这些组件使用了各种各样的端口,使用iptables容易造成误拦截。 美团现在存在物理机、虚拟机、容器等多个业务运行场景,基于iptables的流量劫持方案在适配这些场景时复杂度较高。
鉴于以上两个问题,最终采用了Unix Domain Socket直连方式,实现了业务进程和Octo Proxy进程之间的流量转发。
服务消费者一方,业务进程通过轻量级的Mesh SDK和Octo Proxy监听的UDS地址建立连接。
服务提供者一方,Octo Proxy代替业务进程监听在TCP端口上,业务进程则监听在制定的UDF地址上。
UDS相比于iptable劫持有更好的性能和更低的运维成本,缺点是需要SDK。
服务订阅
原生的Envoy的CDS、EDS请求时全量服务发现模式,是将系统中所有的服务列表都请求到数据面来进行处理。
由于大规模服务集群的服务数量太多,而需要的服务信息是少数的,所以需要改造成按需获取服务的发现模式,只需要请求要访问的后端服务节点列表就可以了。
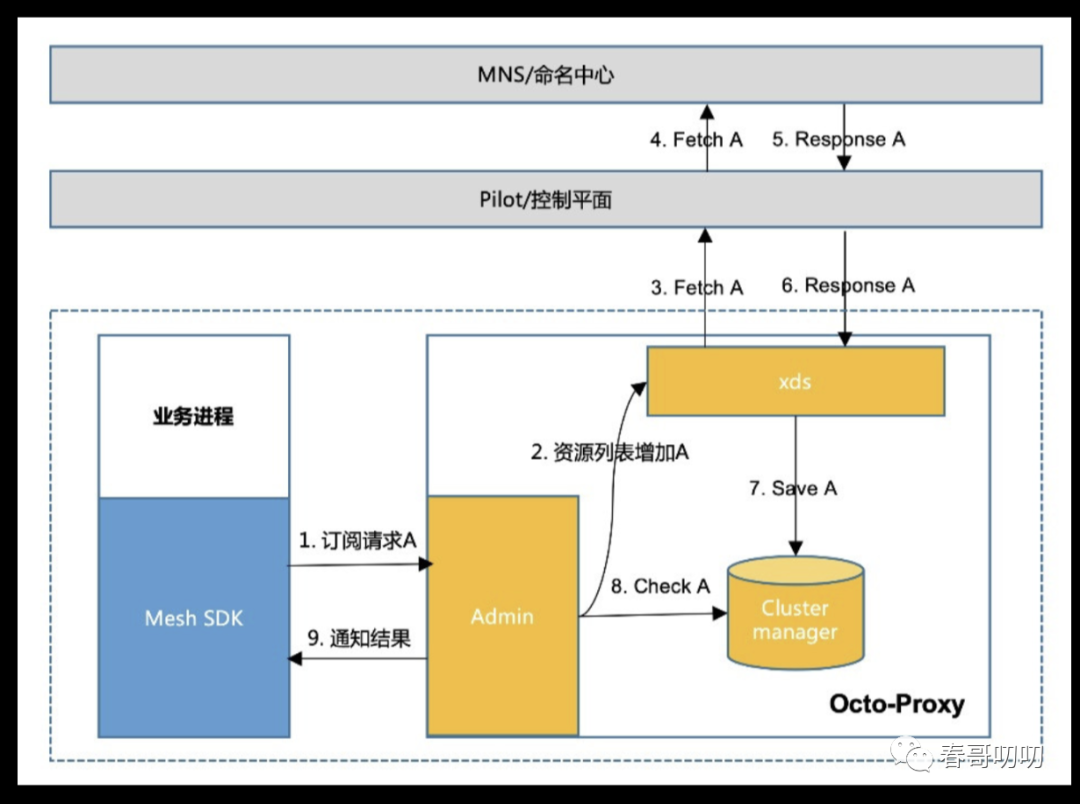
流程如下:
业务进程启动之后,通过http方式向Octo proxy发起服务订阅请求,Octo Proxy将所要请求的后端AppKey更新到Xds中,Xds在向控制面请求具体的服务资源。
为增加整个过程健壮性,降低后期运维成本,做了一定的优化。比如Octo Proxy的启动速度有可能比业务进程启动慢,所以Mesh SDK中增加了请求重试的逻辑,确保请求真正可以经由Octo Proxy发出去。
Mesh SDK和Octo Proxy之间的http请求改成了同步请求,防止pilot资源下发延迟带来问题。
Mesh SDK的订阅信息也会保存在本地文件中,以便在Octo Proxy重启或更新过程中,服务的可用性。
无损热重启
由于业务进程和Octo Proxy是独立的进程,确保Proxy进程热更新时可以持续提供服务,对业务无损无感知就非常重要。社区的Envoy自己支持的热重启不够完善,不能做到完全的无损流量。
我们看下在短连接和长连接两种情况下Octo Proxy重启可能造成的流量损耗问题。
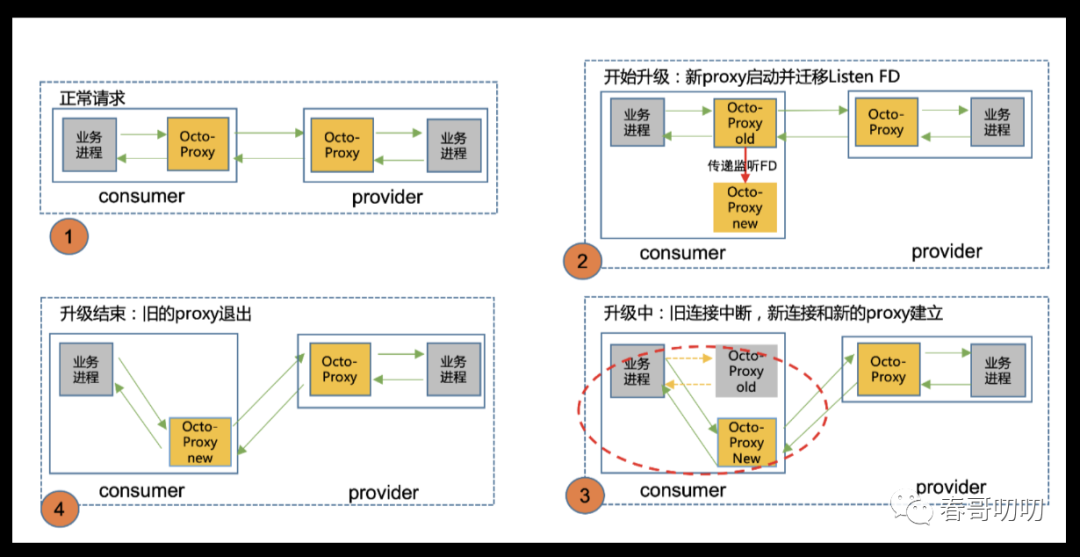
在短连接场景下,所有的新连接会在Octo Proxy New上创建,Octo Proxy Old上已有的连接会在响应到来后主动断开。Octo Proxy Old的所有短连接逐渐断开,当所有连接断开之后,Octo Proxy Old主动退出,Octo Proxy New继续工作,整个过程中流量是无损的。
在长连接场景下,SDK和Octo Proxy Old之间维持一个长连接断不开,并持续使用这个连接发送请求。Ocot Proxy Old进程最终退出时,该链接才被迫断开,这时可能有部分请求还未返回,导致Client端请求超时,因此Envoy的热重启对长连接场景支持的不完美。
为实现基础组件更新过程不对业务流量造成损耗,业界的主要方式是滚动发布。也就是,不是直接全部更新,而是一部分一部分的更新,滚动的承接流量+主动断开连接。
服务节点分批停止服务,执行更新,然后重启,投入使用,直到集群中所有实例都更新为最新版本。这个过程中会主动摘到业务流量,保证升级过程中业务流量不丢失。
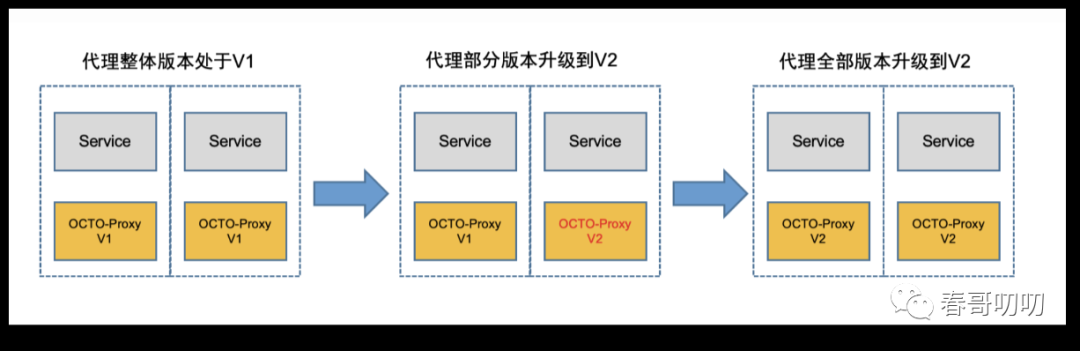
美团的方案是进行角色划分,将业务服务分为两个角色:
对外提供服务的server端;
发起请求调用的client端;
client端octo proxy热更新:
octo proxy old进入重启状态,对后续的请求直接返回“热更新”标志的响应协议,client sdk在收到“热更新”的协议标识之后,主动切换连接进行重试。然后断开sdk上和octo proxy old之间的长连接。
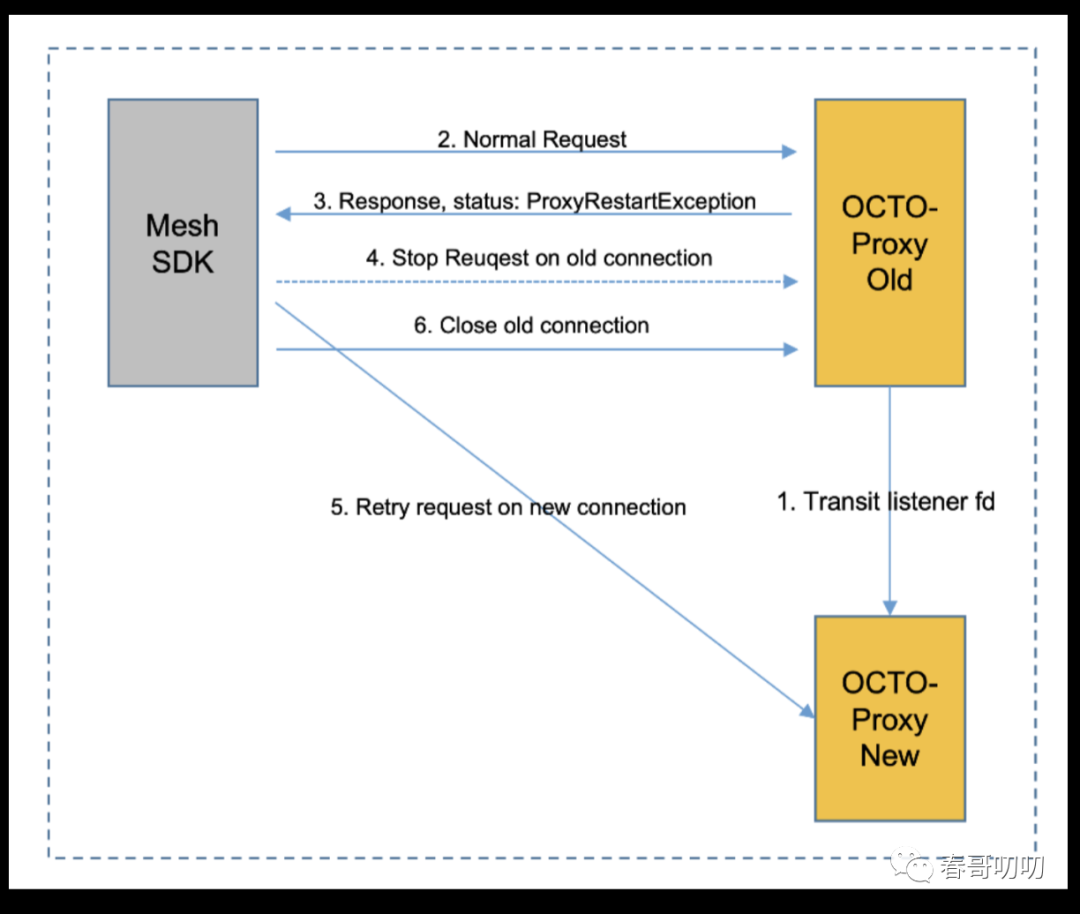
通过client sdk和octo proxy之间的交互配合,可以实现client在octo proxy升级过程中的流量安全。
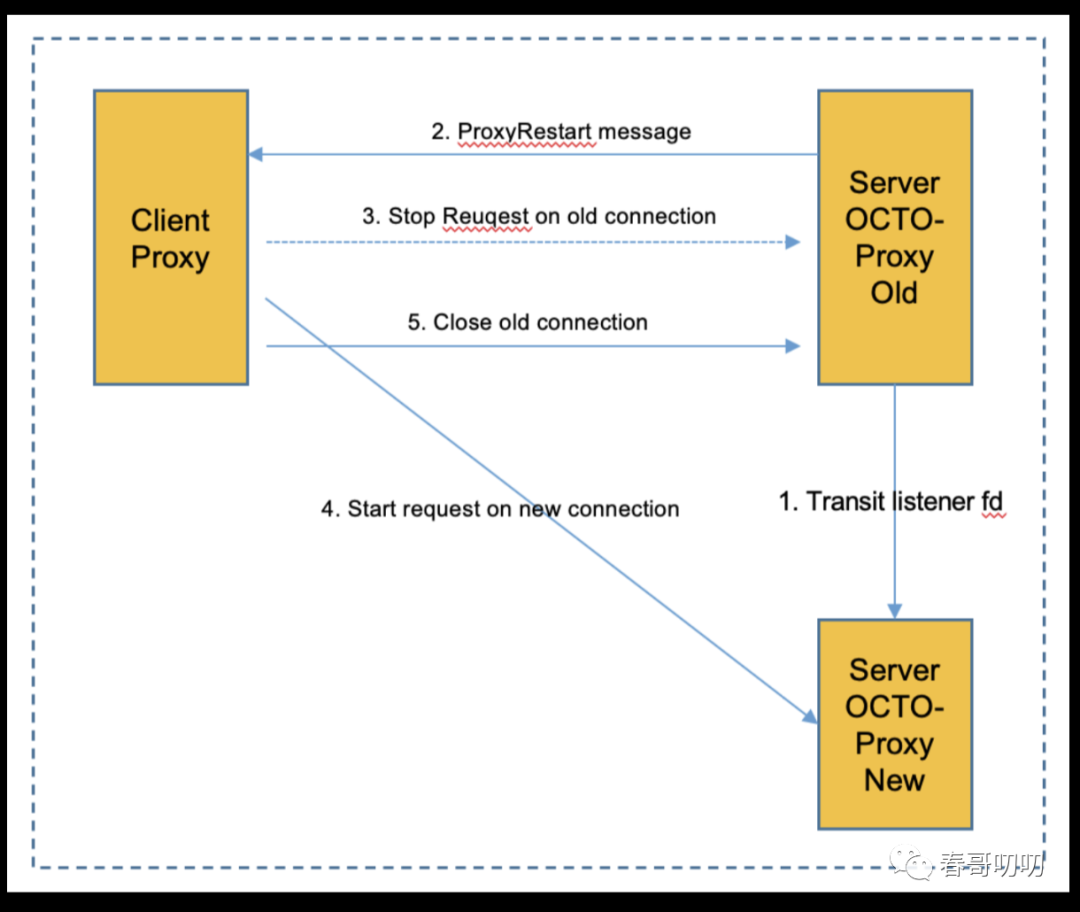
server端coto proxy热更新:
server端的octo proxy在热更新开始后,主动向client侧的octo proxy发送proxy restart消息,也就是要求client侧的octo proxy主动切换新连接,避免当前client侧octo proxy持有的旧链接被强制关闭,导致请求失败。
client侧octo proxy收到“主动切换新连接”的请求后,应及时从可用连接池中清除老的长连接。
数据面运维
在云原生环境下,Envoy运行在标准的K8s Pod中,通常会独立出一个Sidecar容器,这样可以借助K8s的能力实现对Envoy Sidecar容器的管理,比如容器注入、健康检查、滚动升级、资源限制等。
美团内部的容器运行时模式为:单容器模式。就是在一个pod内只包含一个容器。
由于业务进程和所有基础组件都运行在一个容器中,所以只能采用进程粒度的管理措施,无法做到容器粒度的管理。
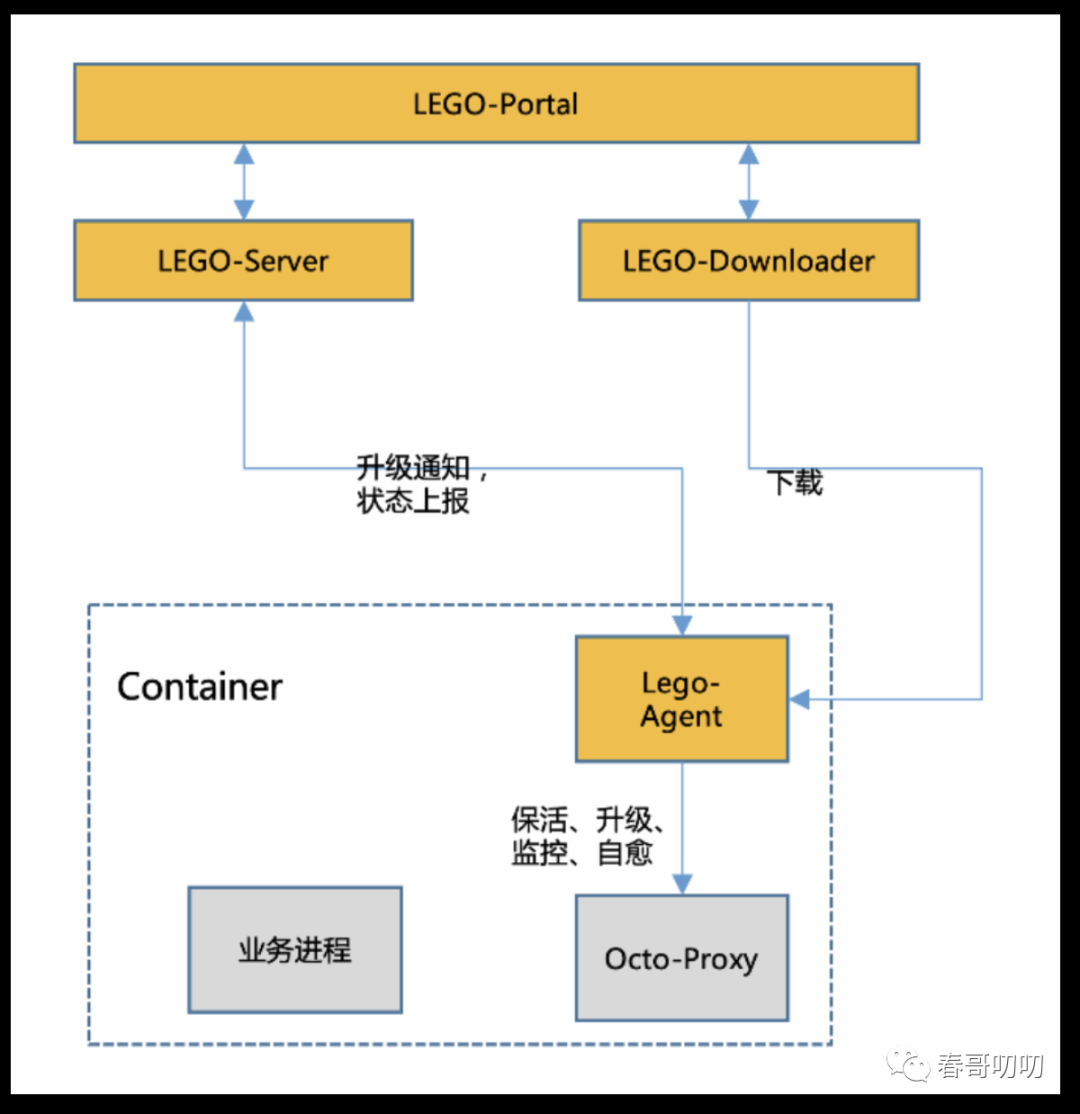
Lego Agent支持了对Octo Proxy热更新的感知,还负责对Octo Proxy进行健康检查、故障状态重启、监控信息上报和版本发布等。相对于原生k8s的容器重启方式,进程粒度重启会更快。
扩展性及完善的运维体系
关键设计
大规模治理体系 Mesh 化建设成功落地的关键点有:
系统水平扩展能力方面,可以支撑数万应用/百万级节点的治理。
功能扩展性方面,可以支持各类异构治理子系统融合打通。
能应对 Mesh 化改造后链路复杂的可用性、可靠性要求。
具备成熟完善的 Mesh 运维体系。
围绕这四点,便可以在系统能力、治理能力、稳定性、运营效率方面支撑美团当前多倍体量的新架构落地。

对于社区 Istio 方案,要想实现超大规模应用集群落地,需要完成较多的技术改造。
因为 Istio 水平扩展能力相对薄弱,内部冗余操作多,整体稳定性较为薄弱。
解决思路如下:
控制面每个节点并不承载所有治理数据,系统整体做水平扩展。
在此基础上提升每个实例的整体吞吐量和性能。
当出现机房断网等异常情况时,可以应对瞬时流量骤增的能力。
只做必要的 P2P 模式健康检查,配合集中式健康检查进行百万级节点管理。
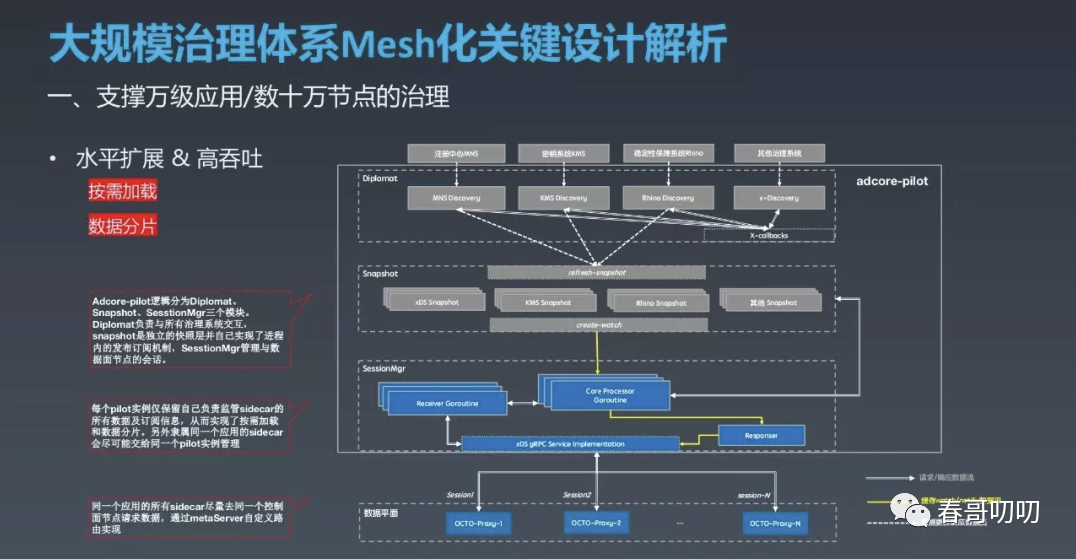
按需加载和数据分片主要由 Adcore Pilot、Meta Server 实现。
Pilot 的逻辑是管理每个数据面会话的全生命周期、会话的创建、交互及销毁等一系列动作及流程;
维护数据最新的一致性快照,对下将资源更新同步处理,对上响应各平台的数据变更通知,将存在关联关系的一组数据做快照缓存。
控制面每个 Pilot 节点并不会把整个注册中心及其他数据都加载进来,而是按需加载自己管控的 Sidecar 所需要的相关治理数据。
同一个应用的所有 OCTO Proxy 由同一个Pilot 实例管控,Meta Server,自己实现控制面机器服务发现和精细化控制路由规则,从而在应用层面实现了数据分片。
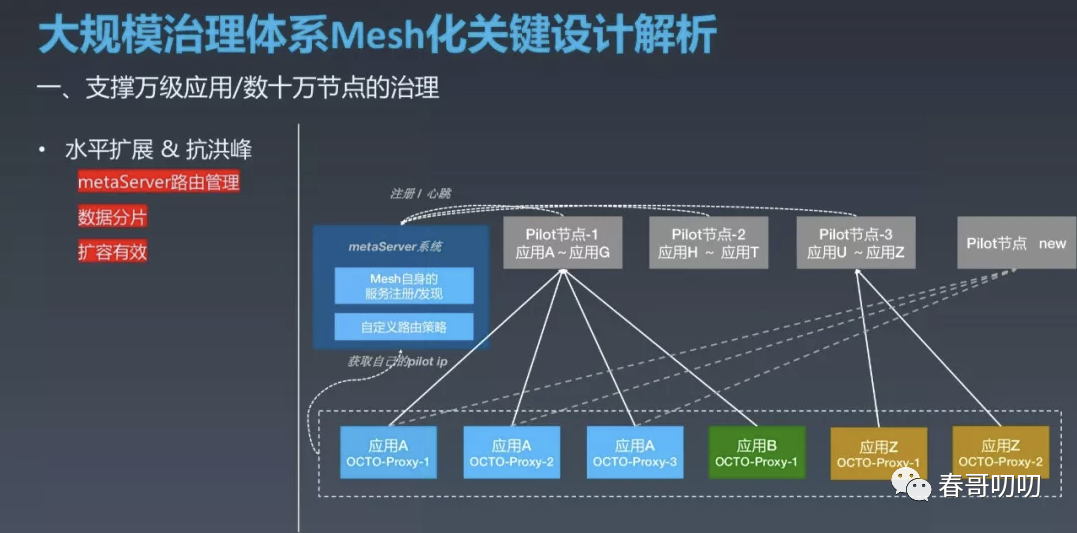
Meta Server 管控每个Pilot节点和OCTO Proxy的归属关系。
当 Pilot 实例启动后会注册到 Meta Server,此后定时发送心跳进行续租,长时间心跳异常会自动剔除。
Meta Server 内部有一致性哈希策略,会综合节点的应用、机房、负载等信息进行分组。当一个 Pilot 节点异常或发布时,该 Pilot 的 OCTO Proxy 都会有规律的连接到接替节点,而不会全局随机连接对后端注册中心造成风暴。
当异常或发布后的节点恢复后,划分出去的 OCTO Proxy 又会有规则的重新归属当前 Pilot 实例管理。
对于关注节点特别多的应用 OCTO Proxy,也可以独立部署 Pilot,通过 Meta Server 统一进行路由管理。
稳定性保障设计

围绕控制故障影响范围、异常实时自愈、可实时回滚、柔性可用、提升自身可观测性及回归能力进行建设。
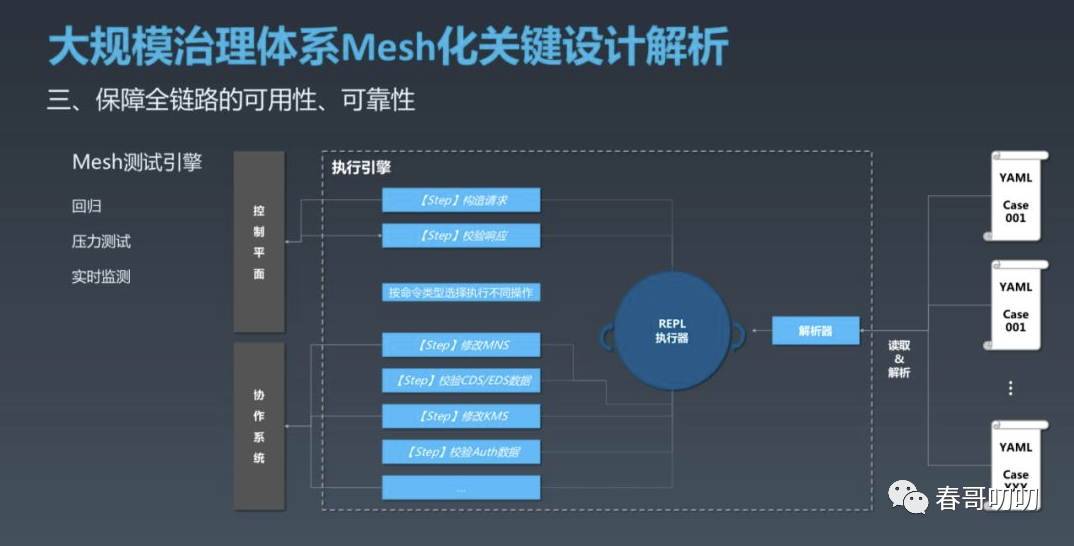
命名服务与注册中心打通
Mesh体系的命名服务需要 Pilot 与注册中心打通。
采用ZK实现的方式是每个 OCTO Proxy 与 Pilot 建立会话时,作为客户端角色会向注册中心订阅自身所关注的服务端变更监听器,如果这个服务需要访问100个应用,则至少需要注册100个 Watcher 。
如果存在1000个实例同时运行,就会注册 100 x 1000 = 100000 个 Watcher。还有很多应用有相同的关注的对端节点,造成大量的冗余监听。
规模较大后,网络抖动或业务集中发布时,很容易引发风暴效应把控制面和后端的注册中心打挂。
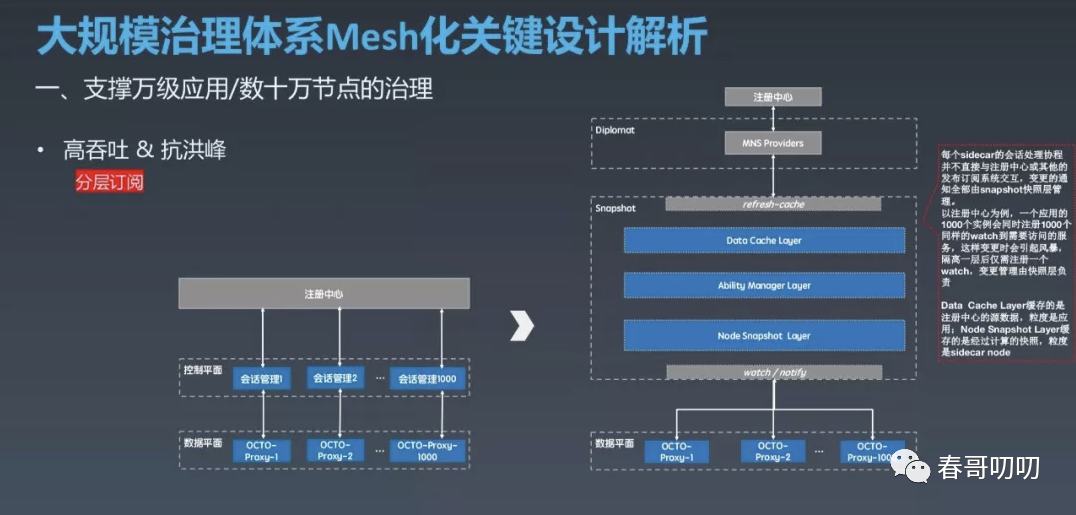
针对这个问题,可以采用分层订阅方式。
就是每个 OCTO Proxy 的会话并不直接和注册中心或其他的发布订阅系统交互,而是将变更的通知全部由 Snapshot 快照层管理。
Snapshot 内部又划分为3层:
Data Cache 层对接并缓存注册中心及其他系统的原始数据,粒度是应用;
Node Snapshot 层则是保留经过计算的节点粒度的数据;
Ability Manager 层内部会做索引和映射的管理,当注册中心存在节点状态变更时,会通过索引将变更推送给关注变更的 OCTO Proxy;
回到刚才的场景,隔离一层后1000个节点仅需注册100个 Watcher,一个 Watcher 变更后仅会有一条变更信息到 Data Cache 层,再根据索引向1000个 OCTO Proxy 通知,从而极大的降低了注册中心及 Pilot 的负载。
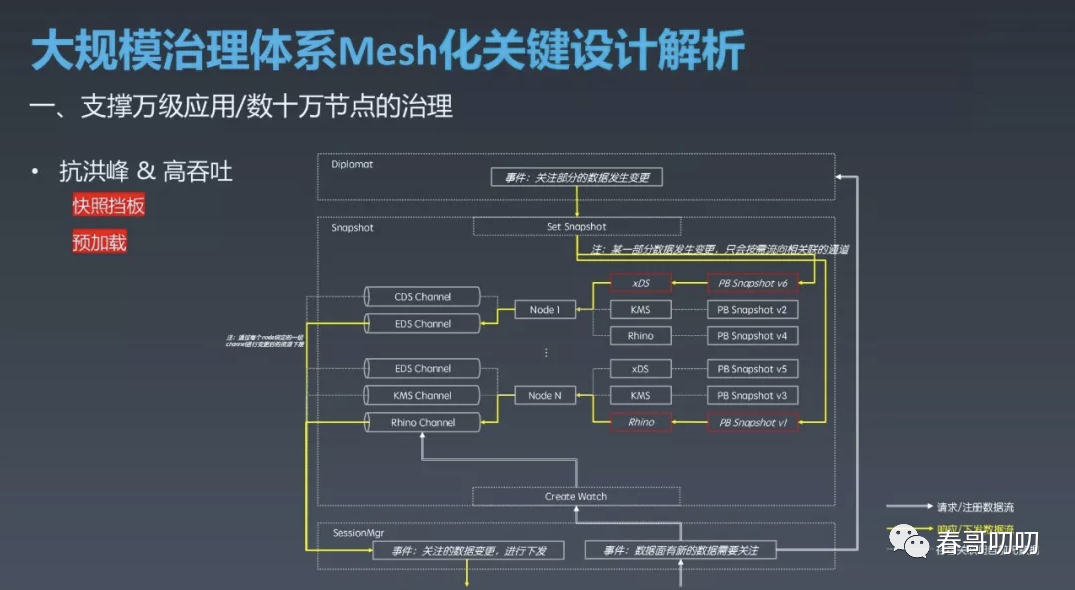
Snapshot 层除了减少不必要交互提升性能外,还会将计算后的数据格式化缓存下来,这样瞬时大量的请求会在快照层被缓存挡住。
预加载的主要目的是提升服务冷启动性能。
在 Pilot 节点中加载好最新的数据,当业务进程启动时,Proxy 就可以立即从 Snapshot 中获取到数据,避免了首次访问慢的问题。
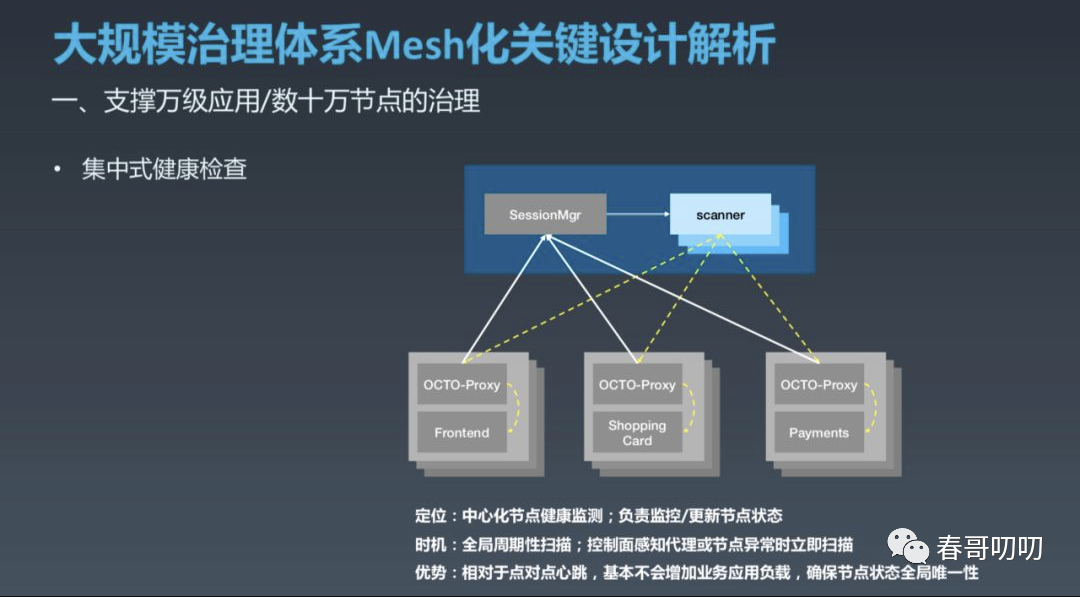
Istio 默认每个 Envoy 代理对整个集群中所有其余 Envoy 进行 P2P 健康检测。
当集群有N个节点时,一个检测周期内就需要做N的平方次检测,另外当集群规模变大时,所有节点的负载就会相应提高,这都将成为扩展部署的极大障碍。
美团采用了集中式的健康检查方式,同时配合必要的P2P检测:
由中心服务 Scanner 监测所有节点的状态,当 Scanner 主动检测到节点异常或 Pilot 感知连接变化通知 Scanner 扫描确认节点异常时, Pilot 立刻通过 eDS 更新节点状态给 Proxy,这种模式下检测周期内仅需要检测 N 次。(Google 的Traffic Director 也采用了类似的设计,但大规模使用需要一些技巧:第一个是为了避免机房自治的影响而选择了同机房检测方式,第二个是为了减少中心检测机器因自己 GC 或网络异常造成误判,而采用了Double Check 的机制)。
除了集中健康检查,还会对频繁失败的对端进行心跳探测,根据探测结果进行摘除操作,提升成功率。
异构治理系统融合设计
Istio 和 Kubernetes 将所有的数据存储、发布订阅机制都依赖 Etcd 统一实现,但美团的10余个治理子系统功能各异、存储各异、发布订阅模式各异,呈现出明显的异构特征,如果接入一个功能就需要平台进行存储或其他大规模改造,这样是完全不可行的。
一个思路是由一个模块来解耦治理子系统与 Pilot ,这个模块承载所有的变更并将这个变更下发给 Pilot。
独立的统一接入中心,屏蔽所有异构系统的存储、发布订阅机制;
Meta Server 承担实时分片规则的元数据管理;
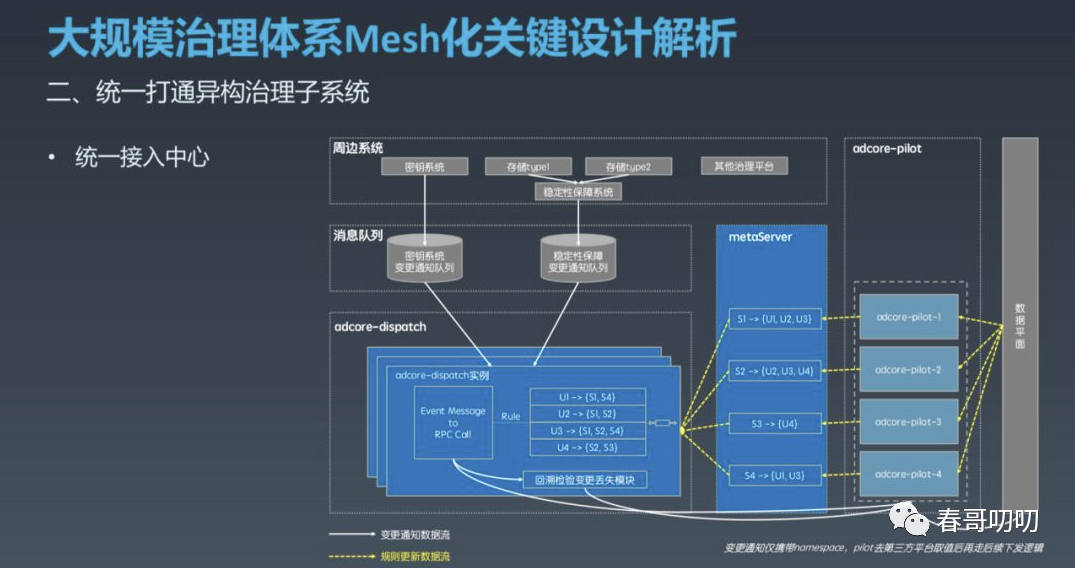
执行机制如上图:
各系统变更时使用客户端将变更通知推送到消息队列,只推送变更但不包含具体值(当Pilot接收到变更通知后,会主动Fetch全量数据,这种方式一方面确保Mafka的消息足够小,另一方面多个变更不需要在队列中保序解决版本冲突问题。);
Adcore Dispatcher 消费信息,并根据索引将变更推送到关注的 Pilot 机器,当 Pilot 管控的 Proxy 变更时会同步给 Meta Server,Meta Server 实时将索引关系更新并同步给Dispatcher;
为了解决 Pilot 与应用的映射变更间隙出现消息丢失,Dispatcher 使用回溯检验变更丢失的模式进行补偿,以提升系统的可靠性;
运维体系设计
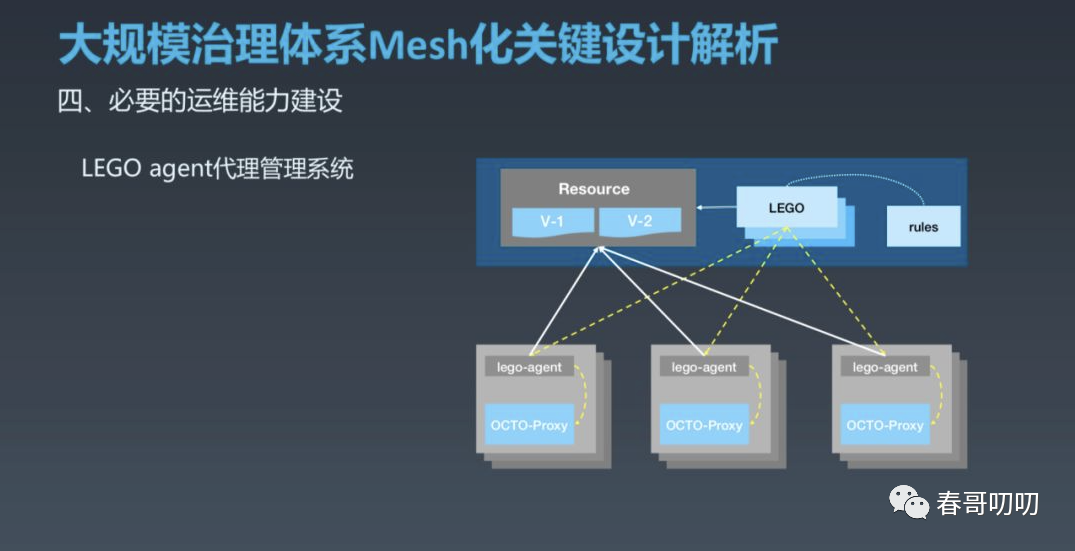
操作流程如下:
运维人员在 LEGO 平台发版,确定发版版本;
新版本资源内容上传至资源仓库,并更新规则及发版范围至 DB;
升级指令下发至所要发布的范围;
收到发版命令机器的 LEGO Agent 去资源仓库拉取要更新的版本(如有失败,会有主动 Poll 机制保证升级成功);
新版本下载成功后,由 LEGO Agent 启动新版的 OCTO Proxy;
总结
美团的Mesh方案已经看不懂了,看不懂只能后续再熟悉Mesh一些回头再看。
整体看来,美团这套Mesh演进方案对大家还是非常有借鉴意义的,因为上Mesh势必是已经到了一定的治理规模,这里会遇到一个很重要的问题是,如何将Mesh的治理能力有机的集成到已经成熟的某套治理能力下,比如微服务治理体系。
所以这种面向未来新的治理体系来了之后,更多的问题是如何借鉴新模式方案方式去优化我们的系统中,简单说是要个“神”,而不必是“形”,比如你可以按需替换掉Mesh里面某些模块、组件等,以我们成熟的能力去承接。