
大型翻车现场:如何实现记录存在就更新,如果记录不存在就插入
Hi,大家好!我是白日梦!下文以自导自演的方式,围绕“如何实现记录存在的话就更新,如果记录不存在的话就插入。”展开本话题。看看你能抗到第几问吧
欢迎关注!持续更新中~

Hi同学,前面表现的不错哦。关于MySQL的基础掌握的还可以,现在有时间继续吗?
嗯,有时间!

 这个专题还有好多文章没写完呢!挂了怎么往下写?
这个专题还有好多文章没写完呢!挂了怎么往下写?那我们继续面吧。出一道场景题:现在我的业务中有这样的需求:如果目标记录存在的话我就更新它,如果记录不存在的话我就插入。说说看你知道哪些实现方式吧!
这种方式。
// 伪代码user=User.FindById(1)if user == null{user.Insert()}else{user.Update()}
嗯,还可以像下面这样,我先尝试更新,如果没有这条记录的话,更新函数返回的影响行数就是0。 于是我根据这个影响行数去判断,当影响行数为0时说明数据库中没有这条记录。于是我就写入。
于是我根据这个影响行数去判断,当影响行数为0时说明数据库中没有这条记录。于是我就写入。
通过这种方式和MySQL之间的网络请求次数就有可能降低成1。
// 伪代码effectRows=User.UpdateById(1)if effectRows >0 {user.Insert()}
我看未必吧!并且你这代码存在安全隐患啊!比如遇到这种情况:user实例中的信息和数据库中的记录完全一致。然后你拿着user中的信息去更新数据库中的信息。实际上就没有发生任何改变。 也就是说,你的代码中的UpdateById(1)的返回值是0!
也就是说,你的代码中的UpdateById(1)的返回值是0!
然后你的代码进入else中,很显然id=1的行已经存在了,你还执行insert xxx id = 1,这肯定会报错说:主键冲突啊!
我靠!大佬说的对啊!按你这么说,这确实是个风险。即使每次去更新的时候携带上最新的时间戳也无法保证它一定不会进入到else中!
嗯,对的。我们继续这个话题,你还知道其他的实现方式吗?我提示你一下:你有没有使用过 insert ignore into 语句?
嗯嗯,使用过,insert ignore into的作用是:如果记录存在了就忽略本次ignore本次插入。如果记录不存在就写入。
关于insert ignore into的实战可以看这个示例
Step1:创建库表
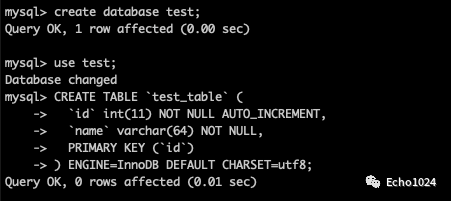
Step2:正常写入一条数据
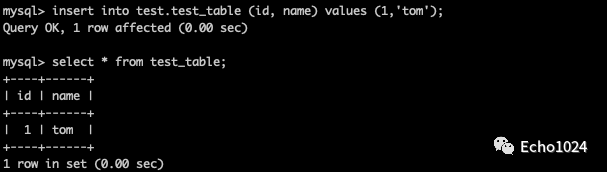
Step3:使用insert ignore 重复写入和上一条SQL完全一种的数据
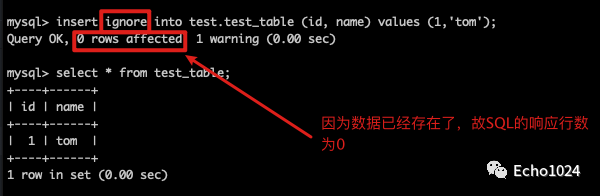
Step4:使用insert ignore写入一条新的数据,会发现可以写入成功。
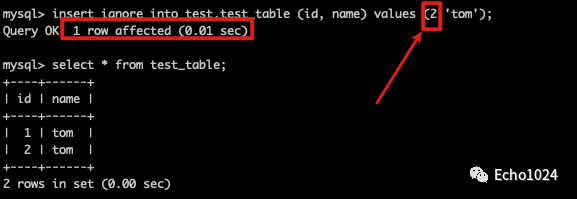
Step5:使用insert ignore写入,测试一下如果想写入的数据的id(唯一key)已经在表中存在了,其他的非唯一键数据不一样。你会发现:也不能重复写入
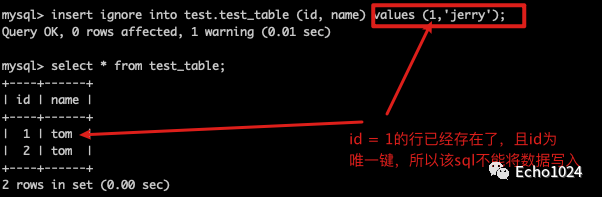
嗯,通过你的实验可以看出:insert ignore into的功能是:如果数据已经存在了就忽略本次写入,如果数据不存在就insert。通过上面你做的实验也可以看出它判断是否可以写入的标准是:唯一键不能重复。
只要你想写入的数据和现有的唯一键冲突了,最终就不会将你的数据落库。
嗯嗯,这么看来insert ignore into 并不能满足我们的业务需求。不过我还了解 replace into。
嗯!那你说说这个replace 吧!
好,replace into的作用是:如果数据已经存在了我就更新。如果数据不存在就更写入。
而判断数据是否已经存在的标准依然是:判断唯一键是否重复。
嗯,继续。
嗯嗯,可以看下面的这个例子:
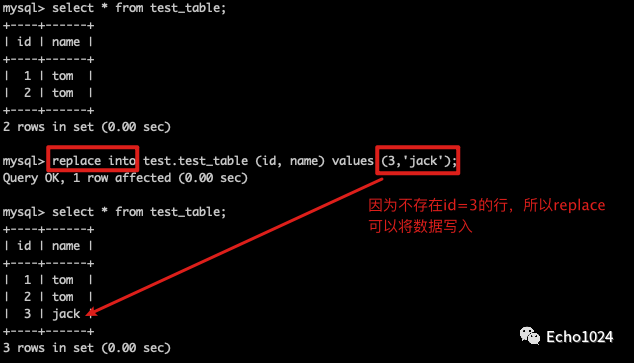
Step1:如果数据不存在replace 可以将数据写入进去
Step2:如果数据存在replace 可以使用新数据替换旧数据。
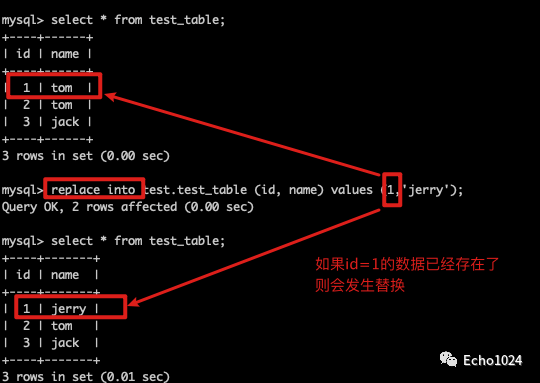
而且这个替换还是全量替换:
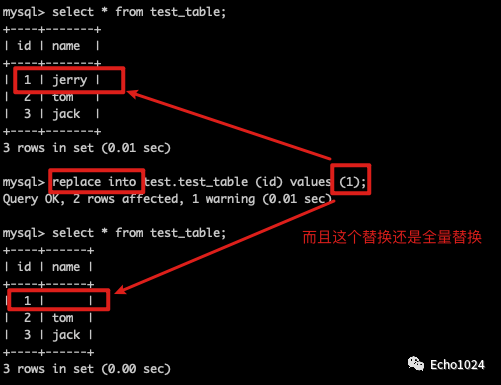
嗯,很好,使用replace into 确实能做到一次网络请求就实现我们的业务需求。
其实我还知道另一种实现方式:也可以通过一次网络请求实现咱们的业务需求。
哦?你说说看!
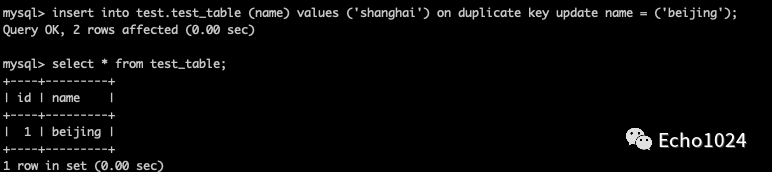
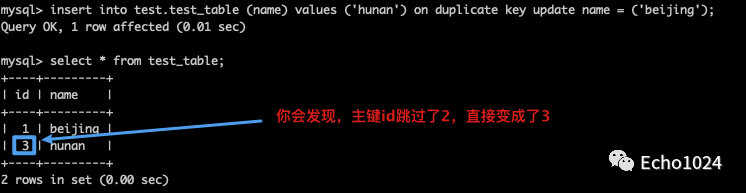
使用 on duplicate key update也可以实现,如果记录存在就更新,如果记录不存在就插入。
关于: on duplicate key update可以看这个例子:
Step1: 如果已经存在了,就更新。
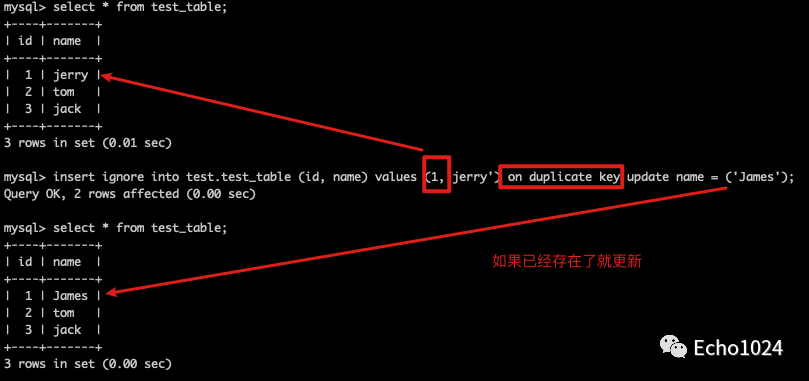
Step2:如果不存在就写入
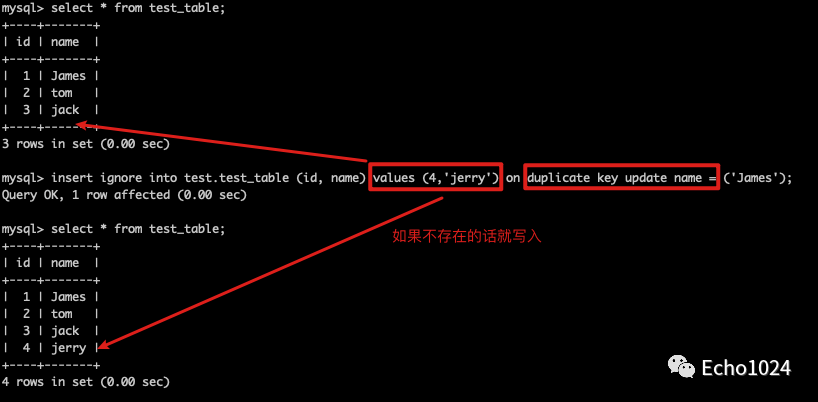
(上面两图中的ignore不影响)
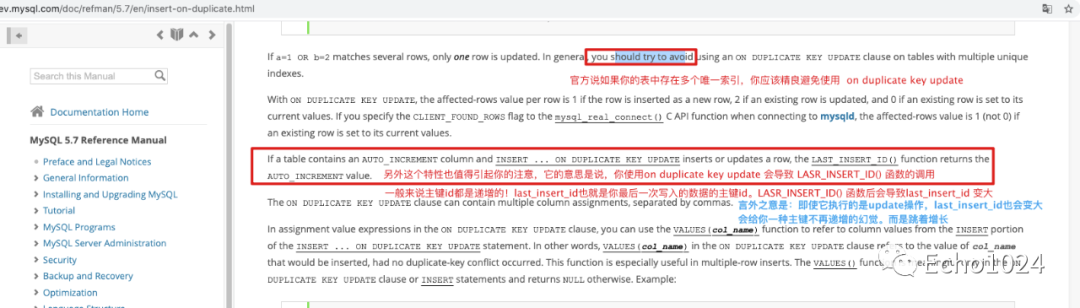
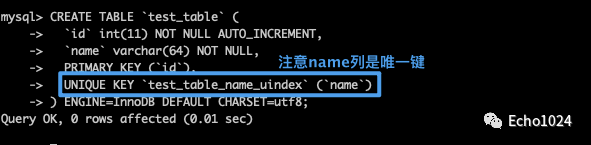

小伙子可以的!整体感觉还不错。
欢迎关注我 。不久会给你安排下一面。
。不久会给你安排下一面。
我没有问题了,你有什么想问我的吗?
感谢大佬 ,点赞、在读、打赏、转发马上安排上!
,点赞、在读、打赏、转发马上安排上!
往期精彩文章:
谁会拒绝一台Win11和MacOS无缝切换的MacBook呢?Parallels17极速体验
使用AI在原神里自动钓鱼,扫描Git仓库泄露的密码 【Github热榜周刊第三期】