
我用 Python 自制成语接龙小游戏,刺激!
作者:小小明
原文链接:https://blog.csdn.net/as604049322/article/details/118154687
本文为读者投稿
在 https://github.com/pwxcoo/chinese-xinhua 项目中可以下载到中华成语的语料库,该项目收录包括 14032 条歇后语,16142 个汉字,264434 个词语,31648 个成语。
结构如下:
chinese-xinhua/
|
+- data/ <-- 数据文件夹
| |
| +- idiom.json <-- 成语
| |
| +- word.json <-- 汉字
| |
| +- xiehouyu.json <-- 歇后语
| |
| +- ci.json <-- 词语
可以直接从网络读取该github的json文件:
import pandas as pd
chengyu = pd.read_json(
"https://github.com/pwxcoo/chinese-xinhua/blob/master/data/idiom.json?raw=true")
不过有可能网络不佳导致读取失败,下载好之后读取本地文件更佳:
import pandas as pd
import numpy as np
chengyu = pd.read_json("idiom.json")
chengyu.head(2)

该库有很多列,word列是我们需要的成语,pinyin列已经帮我们转换出了对应的拼音。下面我们整理出我们需要的数据:
t = chengyu.pinyin.str.split()
chengyu["shoupin"] = t.str[0]
chengyu["weipin"] = t.str[-1]
chengyu = chengyu.set_index("word")[["shoupin", "weipin"]]
chengyu
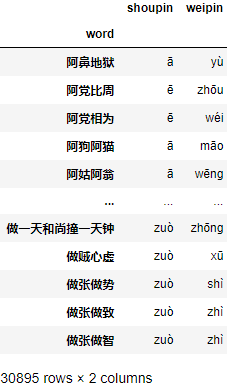
测试获取任意一个成语的接龙结果集:
word = "阿党比周"
words = chengyu.index[chengyu.shoupin == chengyu.loc[word, "weipin"]]
words
Index(['舟车劳顿', '舟水之喻', '舟中敌国', '诌上抑下', '侜张为幻', '周而不比', '周而复始', '周公吐哺', '周规折矩',
'周急继乏', '周郎顾曲', '周情孔思', '周穷恤匮', '周游列国', '诪张变眩', '诪张为幻', '粥少僧多', '粥粥无能'],
dtype='object', name='word')
然后随机任取一个:
np.random.choice(words)
'诪张为幻'
测试没有问题,我们可以写一个批量接龙程序:
word = input("请输入一个成语:")
flag = True
if word not in chengyu.index:
print("你输入的不是一个成语,程序结束!")
flag = False
while flag:
n = input("接龙的次数(1-100次的整数,输入任意字母表示结束程序)")
if not n.isdigit():
print("程序结束")
break
n = int(n)
if not (0 < n <= 100):
print("非法数字,程序结束")
break
for _ in range(n):
words = chengyu.index[chengyu.shoupin == chengyu.loc[word, "weipin"]]
if words.shape[0] == 0:
print("没有找到可以接龙的成语,程序结束")
flag = False
break
word = np.random.choice(words)
print(word)
请输入一个成语:周郎顾曲
接下来程序自动接龙的次数(1-100次的整数,其他情况表示结束)10
曲尽奇妙
妙趣横生
声应气求
求人不如求己
掎挈伺诈
诈痴不颠
颠乾倒坤
昆山之玉
玉叶金枝
织当访婢
接下来程序自动接龙的次数(1-100次的整数,其他情况表示结束)no
结束
完整代码
import pandas as pd
import numpy as np
chengyu = pd.read_json("idiom.json")
t = chengyu.pinyin.str.split()
chengyu["shoupin"] = t.str[0]
chengyu["weipin"] = t.str[-1]
chengyu = chengyu.set_index("word")[["shoupin", "weipin"]]
word = input("请输入一个成语:")
flag = True
if word not in chengyu.index:
print("你输入的不是一个成语,程序结束!")
flag = False
while flag:
n = input("接龙的次数(1-100次的整数,输入任意字母表示结束程序)")
if not n.isdigit():
print("程序结束")
break
n = int(n)
if not (0 < n <= 100):
print("非法数字,程序结束")
break
for _ in range(n):
words = chengyu.index[chengyu.shoupin == chengyu.loc[word, "weipin"]]
if words.shape[0] == 0:
print("没有找到可以接龙的成语,程序结束")
flag = False
break
word = np.random.choice(words)
print(word)
我们还可以写一个与机器对战的成语接龙小游戏:
import pandas as pd
import numpy as np
chengyu = pd.read_json("idiom.json")
t = chengyu.pinyin.str.split()
chengyu["shoupin"] = t.str[0]
chengyu["weipin"] = t.str[-1]
chengyu = chengyu.set_index("word")[["shoupin", "weipin"]]
is_head = input("是否先手(输入N表示后手,其他表示先手)")
if is_head == "N":
word2 = np.random.choice(chengyu.index)
print(word2)
weipin = chengyu.loc[word2, "weipin"]
else:
weipin = ''
while True:
word = input("请输入一个成语(认输或离开请按Q):")
if word == "Q":
print("你离开了游戏,再见!!!")
break
if word not in chengyu.index:
print("你输入的不是一个成语,请重新输入!")
continue
if weipin and chengyu.loc[word, 'shoupin'] != weipin:
print("你输入的成语并不能与机器人出的成语接上来,你输了,游戏结束!!!")
break
words = chengyu.index[chengyu.shoupin == chengyu.loc[word, "weipin"]]
if words.shape[0] == 0:
print("恭喜你赢了!成语机器人已经被你打败!!!")
break
word2 = np.random.choice(words)
print(word2)
weipin = chengyu.loc[word2, "weipin"]
是否先手(输入N表示后手,其他表示先手)
请输入一个成语(认输或离开请按Q):妙趣横生
生米煮成熟饭
请输入一个成语(认输或离开请按Q):饭来开口
口呆目钝
请输入一个成语(认输或离开请按Q):遁名匿迹
计功谋利
由于成语积累量较少,几局就已经快玩不下去,于是我打算再写个成语查询器方便开挂后再上,而不是疯狂的百度,代码如下:
from gooey import Gooey, GooeyParser
import pandas as pd
chengyu = pd.read_json("idiom.json")
t = chengyu.pinyin.str.split()
chengyu["shoupin"] = t.str[0]
chengyu["weipin"] = t.str[-1]
chengyu = chengyu.set_index("word")[["shoupin", "weipin"]]
@Gooey
def main():
parser = GooeyParser(description="成语接龙查询器 - @小小明")
parser.add_argument('word', help="被查询的成语")
args = parser.parse_args()
word = args.word
if word not in chengyu.index:
print("你输入的不是一个成语,请重新输入!")
else:
words = chengyu.index[chengyu.shoupin == chengyu.loc[word, "weipin"]]
if words.shape[0] > 0:
print("满足条件的成语有:")
print("、".join(words))
else:
print("抱歉,没有找到能够满足条件的成语")
print("-----" * 10)
if __name__ == '__main__':
main()
这里我使用了Gooey,需要pip安装:
pip install Gooey
项目地址:https://github.com/chriskiehl/Gooey
体验一把:
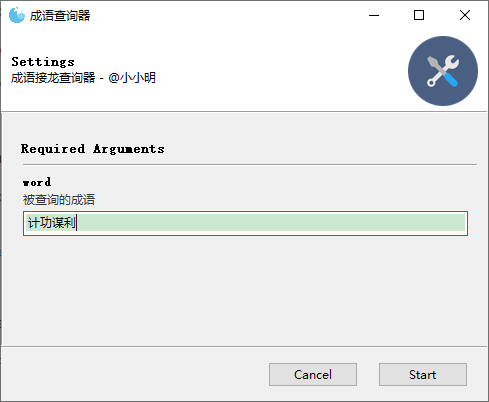
点击start后:
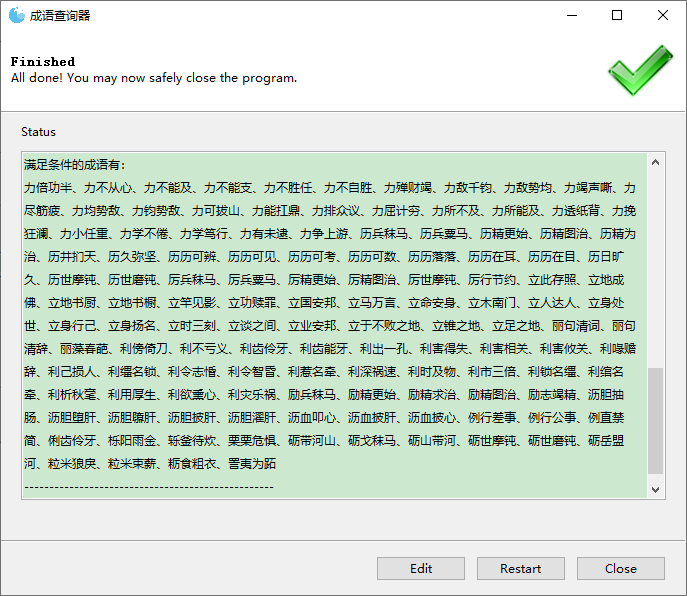
要重新开始查询只需点击Edit按钮即可。Gooey支持的组件还挺多的,可以参考GitHub项目说明。虽然Gooey远不如专业的图形化框架专业,但对于简单的需求也挺简单便捷,能快速把命令行程序转换为图形化程序。
参考
《文本数据挖掘——基于R语言》黄天元
推荐阅读
最详细的 Python 结合 RFM 模型实现用户分层实操案例!
太秀了!用Excel也能实现和Python数据分析一样的功能!

评论