
【时序分析】Prophet
今年打算开新专栏【论文品读】,用于分享自己读论文的笔记和心得。本篇介绍时序中经典模型Prophet。不足之处,还望批评指正。

论文: Forecasting at Scale
代码: https://github.com/facebook/prophet
一、历史研究和瓶颈
ARMA模型在趋势和季节上没有很好的处理,eta(exponential smoothing)和snaive(seasonal navie)虽然能抓住周季节性但不能抓到更长周期性。
二、介绍
2018年Facebook提出的prophet,主要是让分析师将业务知识融入到时序建模当中,同时能批量建模。它的核心思想是y=trend+seasonality+holiday+error。
1. 趋势项
饱和增长模型saturating growth model(非线性、sigmoid-like)和分段线性模型piecewise linear model(线性)。
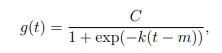
● C为承载量carrying capacity,比如Facebook的用户量的C可能为网民数量。
● k为增长率。
● m为offset参数。
但上述公式有两个问题:(1)C不一定为常数,比如人口会增加,所以网民基数也会增加。(2)增长率不一定为常数,比如新产品增长率会更大。所以作者把C、k、m变为函数:
而分段线性模型如下:

prophet的变点选择可以人工或者自动,详见[2]。变点自动选择会基于Laplace分布,其中增长率变化量delta服从Laplace(0,tau):

tau即为图中的lamda,tau越大,分布越“矮”,增长率变化越灵活,越容易过拟合。当tau趋向于0时,delta也趋向于0。delta也跟变点有着对应关系,当出现变点时,会采样delta出来:
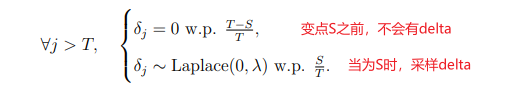
在 Prophet 里面,是需要设置变点的位置的,而每一段的趋势和走势也是会根据变点的情况而改变的。在程序里面有两种方法,一种是通过人工指定的方式指定变点的位置;另外一种是通过算法来自动选择。在默认的函数里面,Prophet 会选择 n_changepoints = 25 个变点,然后设置变点的范围是前 80%(changepoint_range),也就是在时间序列的前 80% 的区间内会设置变点。...(略),首先要看一些边界条件是否合理,例如时间序列的点数是否少于 n_changepoints 等内容;其次如果边界条件符合,那变点的位置就是均匀分布的,这一点可以通过 np.linspace 这个函数看出来。[2] 知乎:Facebook 时间序列预测算法 Prophet 的研究
2. 季节项
季节模型依赖于傅里叶级数(Fourier series),公式如下:

P为常规周期,比如P=365.25为年周期,P=7为周周期。由于使用了N个样本和2类波(sin和cos),所以模型需要估计2N个参数:

N是用于低通滤波的,所以N越大,越平滑,更快帮助模型拟合季节性。
3. 假期项

三、注意事项
1. tau和sigma分别控制趋势变点增长率变化量的Laplace分布和季节正弦/余弦波系数的正态分布,抽象来说控制的是模型的正则化。
2. 关于怎么引入分析师domain knowledge到模型中,作者给了一些建议:基于外部数据参考设置载重量C,结合业务场景人工设置变点、假期和季节周期,试着调整分布量tau、sigma和v。
3. 评估模型时,可以从与baseline模型的对比出发,有时大误差可能来自于异常值,对异常值处理后再训练模型,可能会有更好的表现。观测数据变化,有时候可能就是序列突然变化了,那就加个变点试试。
参考资料
[1] Taylor, S. J., & Letham, B. (2018). Forecasting at scale. *The American Statistician*, *72*(1), 37-45.
[2] Facebook 时间序列预测算法 Prophet 的研究:https://zhuanlan.zhihu.com/p/52330017