
PyFlink 开发 | PyFlink 开发环境利器:Zeppelin Notebook
摘要:PyFlink 作为 Flink 的 Python 语言入口,其 Python 语言的确很简单易学,但是 PyFlink 的开发环境却不容易搭建,稍有不慎,PyFlink 环境就会乱掉,而且很难排查原因。今天给大家介绍一款能够帮你解决这些问题的 PyFlink 开发环境利器:Zeppelin Notebook。主要内容为:
准备工作 搭建 PyFlink 环境 总结与未来
 GitHub 地址
GitHub 地址 ■ 1. 能够在 PyFlink 客户端使用第三方 Python 库,比如 matplotlib:
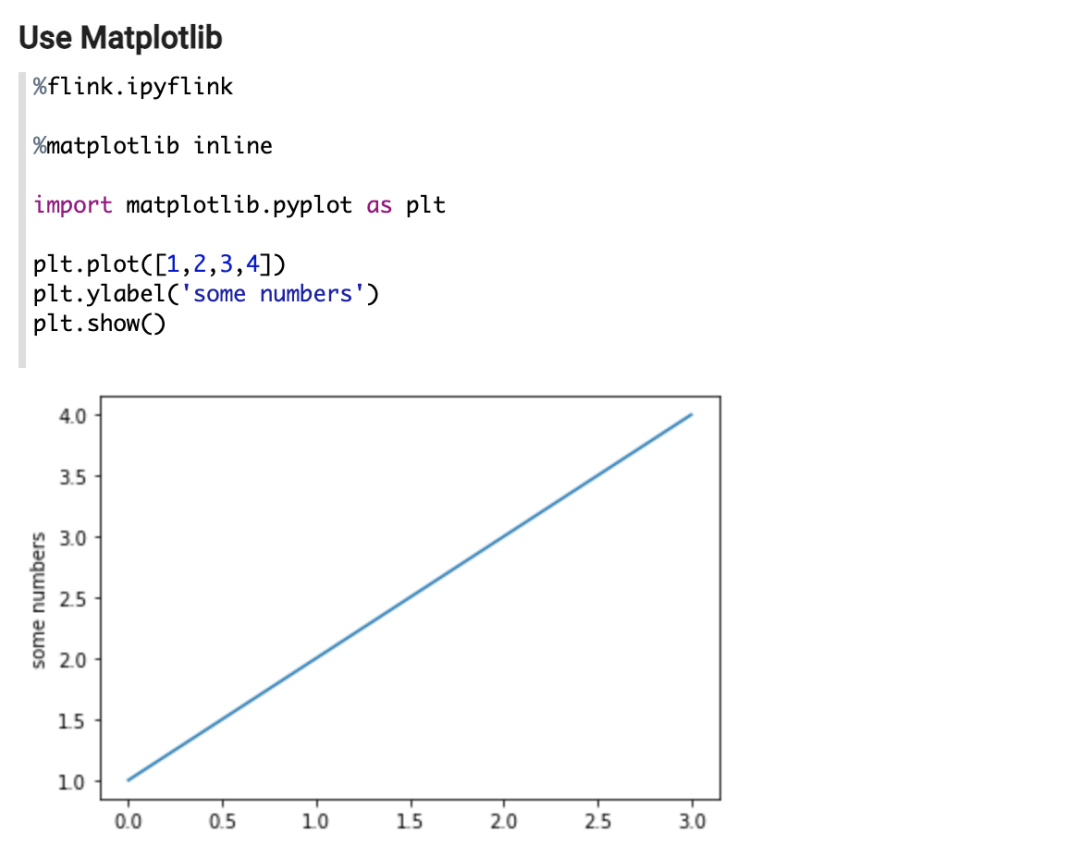
■ 2. 可以在 PyFlink UDF 里使用第三方 Python 库,如:
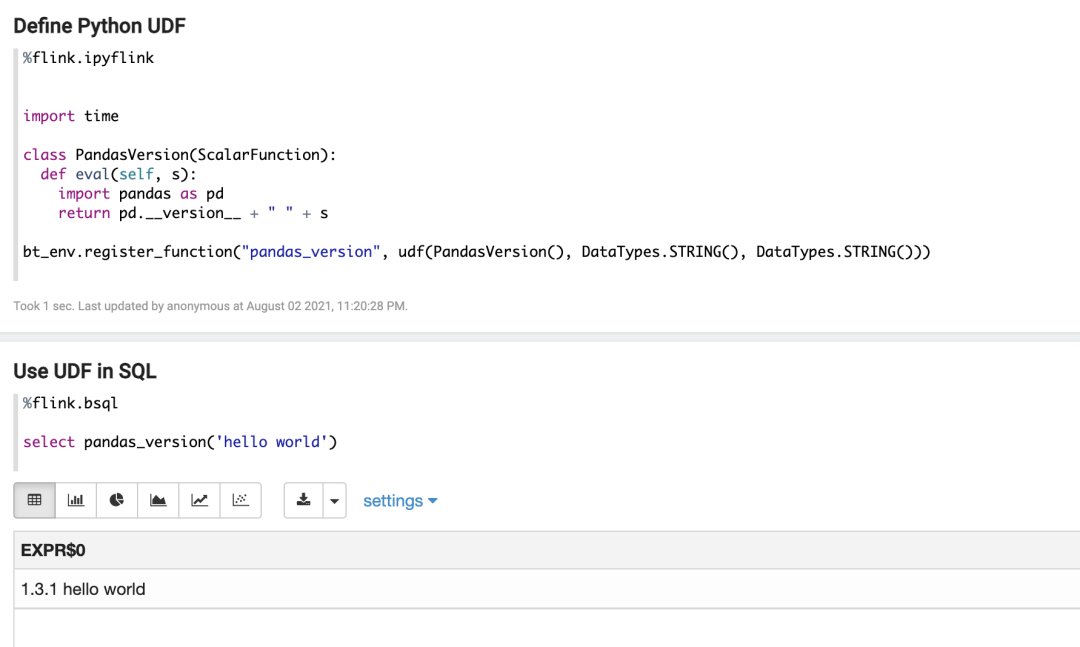
一、准备工作
Step 1.
把 flink-Python-*.jar 这个 jar 包 copy 到 Flink 的 lib 文件夹下;
把 opt/Python 这个文件夹 copy 到 Flink 的 lib 文件夹下。
Step 3.
miniconda:
https://docs.conda.io/en/latest/miniconda.html
conda pack:
https://conda.github.io/conda-pack/
mamba:
https://github.com/mamba-org/mamba
二、搭建 PyFlink 环境
Step 1. 制作 JobManager 上的 PyFlink Conda 环境
某个版本的 Python (这里用的是 3.7)
apache-flink (这里用的是 1.13.1)
jupyter,grpcio,protobuf (这三个包是 Zeppelin 需要的)
# make sure you have conda and momba installed.
# install miniconda: https://docs.conda.io/en/latest/miniconda.html
# install mamba: https://github.com/mamba-org/mamba
echo "name: pyflink_env
channels:
- conda-forge
- defaults
dependencies:
- Python=3.7
- pip
- pip:
- apache-flink==1.13.1
- jupyter
- grpcio
- protobuf
- matplotlib
- pandasql
- pandas
- scipy
- seaborn
- plotnine
" > pyflink_env.yml
mamba env remove -n pyflink_env
mamba env create -f pyflink_env.yml
%sh
rm -rf pyflink_env.tar.gz
conda pack --ignore-missing-files -n pyflink_env -o pyflink_env.tar.gz
hadoop fs -rmr /tmp/pyflink_env.tar.gz
hadoop fs -put pyflink_env.tar.gz /tmp
# The Python conda tar should be public accessible, so need to change permission here.
hadoop fs -chmod 644 /tmp/pyflink_env.tar.gz
Step 2. 制作 TaskManager 上的 PyFlink Conda 环境
某个版本的 Python (这里用的是 3.7)
apache-flink (这里用的是 1.13.1)
echo "name: pyflink_tm_env
channels:
- conda-forge
- defaults
dependencies:
- Python=3.7
- pip
- pip:
- apache-flink==1.13.1
- pandas
" > pyflink_tm_env.yml
mamba env remove -n pyflink_tm_env
mamba env create -f pyflink_tm_env.yml
%sh
rm -rf pyflink_tm_env.zip
conda pack --ignore-missing-files --zip-symlinks -n pyflink_tm_env -o pyflink_tm_env.zip
hadoop fs -rmr /tmp/pyflink_tm_env.zip
hadoop fs -put pyflink_tm_env.zip /tmp
# The Python conda tar should be public accessible, so need to change permission here.
hadoop fs -chmod 644 /tmp/pyflink_tm_env.zip
Step 3. 在 PyFlink 中使用 Conda 环境
flink.execution.mode 为 yarn-application, 本文所讲的方法只适用于 yarn-application 模式;
指定 yarn.ship-archives,zeppelin.pyflink.Python 以及 zeppelin.interpreter.conda.env.name 来配置 JobManager 侧的 PyFlink Conda 环境;
指定 Python.archives 以及 Python.executable 来指定 TaskManager 侧的 PyFlink Conda 环境;
指定其他可选的 Flink 配置,比如这里的 flink.jm.memory 和 flink.tm.memory。
flink.execution.mode yarn-application
yarn.ship-archives /mnt/disk1/jzhang/zeppelin/pyflink_env.tar.gz
zeppelin.pyflink.Python pyflink_env.tar.gz/bin/Python
zeppelin.interpreter.conda.env.name pyflink_env.tar.gz
Python.archives hdfs:///tmp/pyflink_tm_env.zip
Python.executable pyflink_tm_env.zip/bin/Python3.7
flink.jm.memory 2048
flink.tm.memory 2048
下面的例子里,可以在 PyFlink 客户端 (JobManager 侧) 使用上面创建的 JobManager 侧的 Conda 环境,比如下边使用了 Matplotlib。
下面的例子是在 PyFlink UDF 里使用上面创建的 TaskManager 侧 Conda 环境里的库,比如下面在 UDF 里使用 Pandas。
三、总结与未来
目前我们需要创建 2 个 Conda env ,原因是 Zeppelin 支持 tar.gz 格式,而 Flink 只支持 zip 格式。等后期两边统一之后,只要创建一个 Conda env 就可以;
apache-flink 现在包含了 Flink 的 jar 包,这就导致打出来的 Conda env 特别大,Yarn container 在初始化的时候耗时会比较长,这个需要 Flink 社区提供一个轻量级的 Python 包 (不包含 Flink jar 包),就可以大大减小 Conda env 的大小。
伴随着海量数据的冲击,数据处理分析能力在业务中的价值与日俱增,各行各业对于数据处理时效性的探索也在不断深入,作为主打实时计算的计算引擎 - Apache Flink 应运而生。
为给行业带来更多实时计算赋能实践的思路,鼓励广大热爱技术的开发者加深对 Flink 的掌握,Apache Flink 社区联手阿里云、英特尔、阿里巴巴人工智能治理与可持续发展实验室 (AAIG)、Occlum 联合举办 "第三届 Apache Flink 极客挑战赛暨 AAIG CUP" 活动,即日起正式启动。

▼ 扫描二维码,了解更多赛事信息 ▼
 戳我,了解 Flink 挑战赛信息~
戳我,了解 Flink 挑战赛信息~