
云上个性化推荐——基于PAI和Hologres的个性化推荐最佳实践
本文内容来自于
由达摩院领航举办的3月20日向量检索专场Meetup讲师演讲内容
天邑
阿里云计算平台高级算法工程师。主要从事基于PAI平台的召回和排序算法研发,及基于云产品的推荐系统解决方案研发,赋能客户个性化推荐解决方案落地。
一、云上个性化推荐
二、向量召回
三、最佳实践
解决方案简介
(一) 个性化推荐 - 核心能力
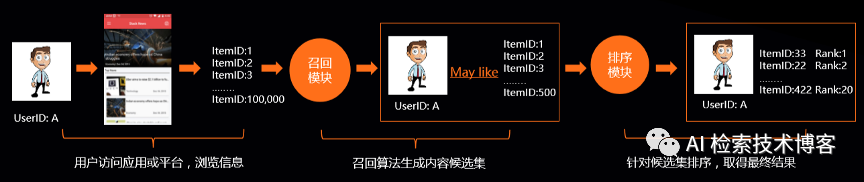
个性化推荐核心价值是要做到千人千面,实现用户需求和资源的最佳匹配,从而提升流量到业务目标的转化效果。

个性化推荐流程一般分召回和排序两个部分,我们要从海量的数据中来精准的筛选出几个到几十个Item给用户推荐过去。
常见推荐方案一:运营经验制定推荐策略
需要有推荐经验的产品设计或运营人员,通过积累的个人经验,制定业务推荐策略,并结合数据分析,调整推荐方案,通常在业务规模比较小的企业,冷启动 阶段使用,有明显的效果弊端:
推荐方案及效果,受到人为影响而不可控。
方案难以实时结合业务发展快速更新,迭代速度慢。
数据计算能力有限,大规模数据分析时候困难。
缺少算法人员搭建企业推荐系统,影响企业提升市场竞争
常见推荐方案二:开源框架自建推荐系统常见推荐方案一:运营经验制定推荐策略
越来越多的企业选择结合AI技术实现企业推荐系统,但使用开源框架自建推荐系统,也存在诸多问题,影响业务发展:
成本高 需要企业采购大量机器用于支持数据计算,不仅一次性投入资金多,且大部分企业都会存在机器资源闲置的浪费问题
工程化工作量大 需要适配主流开源框架,存在巨大的工程化工作,以实现不同业务场景最优推荐效果,或实现支持多部门模型需求。
运维难承载海量数据、多任务运行,日常运维难度很大。
效果不理想。
(三)个性化推荐 – 云上方案
在云上我们可以利用云上的工程基建和算法基建来减缓这部分的成本。在云上提供了两种的推荐方案,一种是黑盒化的,一种是白盒化的,黑盒化的解决方案低门槛易上手。白盒化的解决方案,整个算法流程是工程师全部自主可控的,它适合于有一定规模的,日处理数据百万起的团队,可以支持推荐算法的快速迭代。

(四)云上个性化推荐 – 白盒解决方案
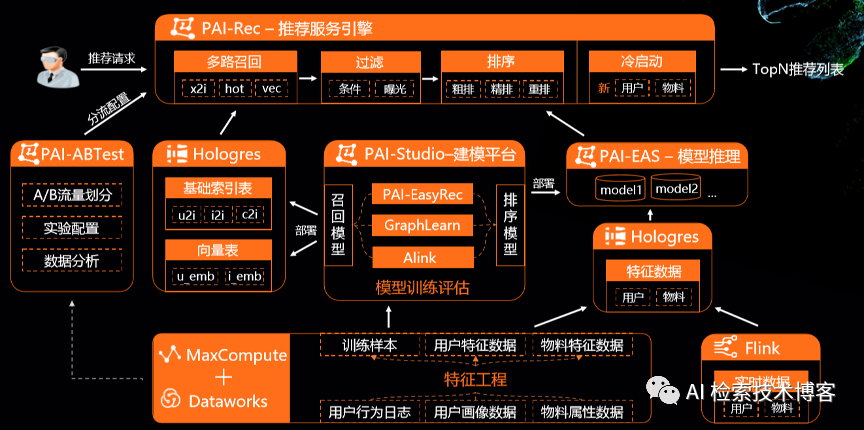
这是整个白盒化的推进解决方案的架构图,我们从下往上看,最下层是数据处理模块,MaxCompute和Dataworks的负责离线的特征处理,得到一些离线训练样本和用户的特征数据物料数据,而Flink是支持实时的特征处理,有了特征样本数据,会流入到PAI-Studio一体化的建模平台中。
其中PAI-EasyRec负责推荐算法,由GraphLearn和Alink负责一些图算法和传统机器设计算法。有了这一些算法,一般会产出两部分的模型,召回模型和排序模型。召回模型我们可以例行部署到Hologres上,部署成各种基础索引表,向量召回的话会部署成向量表,这边图不太好画,user部分向量也可以在EAS上进行实时推理。排序模型的话,我们会部署成在线的模型推理服务来进行在线的打分推理。
有了基础索引表向量表和模型的推理服务,我们再往上层就是整个推荐服务的引擎,我们称之为PAI-Rec推荐服务引擎,PAI-Rec直接接受用户的推荐请求,串联了多路召回、过滤、排序和冷启动模块来给出TopN推荐列表。
PAI-Rec之外,我们有PAI-ABTest来做ab实验,它主要负责科学流量划分和指标的分析,支持我们云上推荐的效果的快速迭代。
(五)云上个性化推荐 – PAI-EasyRec算法框架
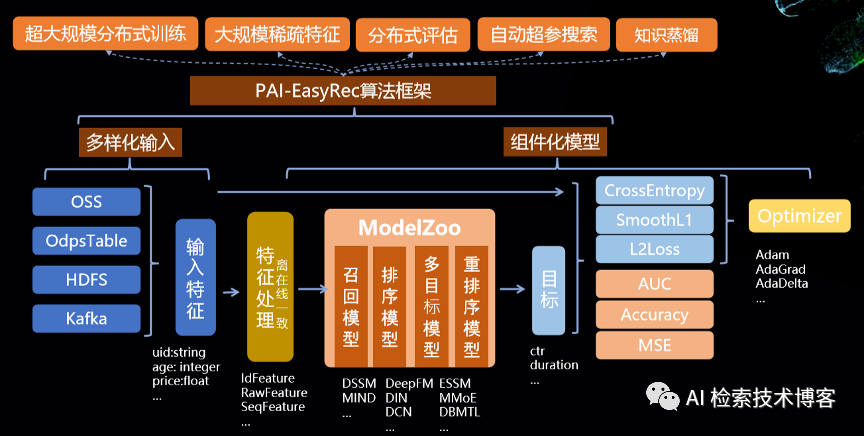
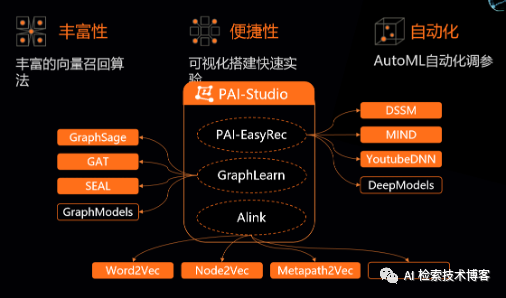
我们重点来看一下其中的几个模块,首先是PAI-EasyRec的整个推荐算法框架,可以支持多样化的数据源,比如说OSS、OdpsTable、HDFS、Kafka等等,有了这样的特征数据,我们会进入一个离在线一致的特征处理模块,这里面可以支持IdFeature 、RawFeature 、SeqFeature等等的特征处理。最中间的是ModelZoo,包含很多PAI精心沉淀的排序模型、召回模型和多目标模型,当然也支持算法工程师来基于此自定义自己的算法。整体上看,EasyRec能在PAI上提供万亿样本、千亿特征的超大规模分布式训练、分布式的评估能力,还支持自动超参搜索和知识蒸馏等调优效果的功能。
(六)云上个性化推荐 – PAI冷启动方案
除了通用的推荐算法之外,我们还提供了PAI冷启动方案,我们为什么需要冷启动?
因为常见的推荐算法对新物品和新用户是不太友好的,
新物品在很大程度上是常常会被低估的。
冷启动问题处理不好会影响内容创造者的积极性,进而影响平台生态的健康发展

我们PAI上的冷启动方案分为用户冷启动和物品冷启动两部分。用户冷启动主要是基于用户的基本画像,基于社交关系,基于用户兴趣的一些热门推荐,U2U的推荐。物品的冷启动的算法的则比较丰富了,有基于内容理解的,有基于快速试探强化学习的,基于不同场景间迁移学习的,此外,少样本学习、知识图谱的算法,我们也在逐步的研发上线中。
(七)云上个性化推荐 – PAIRec推荐引擎
PAIRec推荐引擎从上往下看,分为接口层、召回层、过滤层、排序层、重排层,这些模块它端到端的串联起了整个推荐服务的各个流程,并且其中的一些内置模块是可以简单的通过config文件来配置化使用的。

当然为了满足各种各样场景定制化的需求,我们也支持在各个层便捷的注册各种定义的实现来满足灵活性的要求。
(八)云上个性化推荐 – PAI-A/BTest
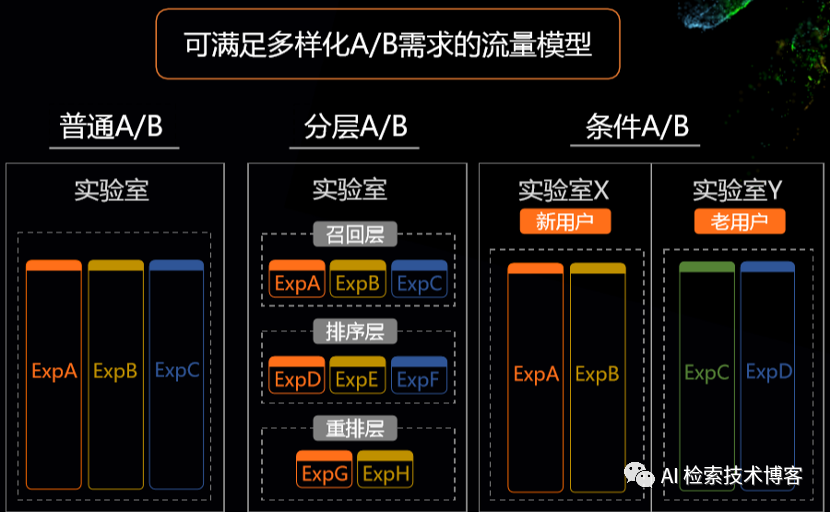
PAI-A/BTest是我们保障快速做推荐迭代效果很重要的一环,我们首先来看一下A/B Test是什么,我们会在同一时间维度将用户划分成两组,在保证用户特征相同的情况下,让用户看到不同的两个ab方案的设计,然后根据最后数据的好坏来决定到底选择哪个方案,最终把哪个方案来推全,他要走的更进一步,可以满足各多样化的A/B Test的需求。
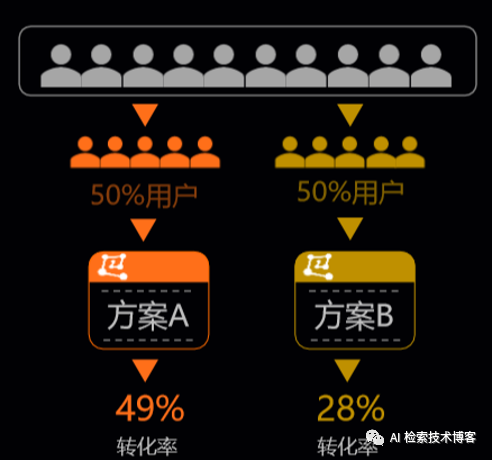
推荐场景为例,我们可以支持这种普通的流量划分,还可以支持分层的流量划分,分层流量划分有什么好处?
推荐场景我们分为召回、排序、重排的这些模块,这些流量是完全可以正交复用的,我们可以在很小的流量场景之下就可以上很多的实验上去帮助我们快速的迭代,PAI-A/BTest还支持在实验室上设置各种各样的条件,比如区分新用户和老用户,来满足各种各样多样化的ab的需求。
PAI召回算法 & HOLO向量检
(一)向量召回 – 简介
召回是在整个推荐系统中很重要的一环,它是在整个推荐系统最前线的部分,决定了整个推荐系统算法效果的上限。
传统的召回算法,如 CF、Swing等,他们虽然是简单高效的,但是他们完全基于用户的历史行为来进行推荐,没有结合用户的画像信息,物品的属性信息来产出推荐结果,这导致了整个推荐效果发现性很弱,会导致越推越窄。
而向量召回是将User、Item都嵌入到一个向量空间中去,一定程度上缓解了发现性的问题。一般向量召回分为 U2I和I2I两种。U2I的向量召回主要代表性的如 DSSM、MIND、YoutubeDNN 等,思想很简单,将User侧和Item侧都抽取到向量空间中去,用User的向量在Item的向量集合中查出最临近的TopK个Item出来。
I2I的如Node2Vec、Metapath2Vec等向量算法,它不同之处是需要Trigger Item,基于用户的历史行为来选择这些Trigger,然后通过Trigger Item的向量,在Item的向量集合中查询出TopK个临近的Item。
(二)向量召回 – PAI向量召回
在PAI上我们提供了丰富的召回算法,在PAI-Studio中我们PAI-EasyRec有提供DSSM、YoutubeDNN、MIND等一系列深度的向量召回模型, GraphLearn提供的GraphSage、GAT、SEAL等基于图的向量召回模型,还有Alink提供Word2Vec、Node2Vec、Metapath2Vec等一系列向量召回模型。在PAI-Studio中,我们想把这些算法快速可视化搭建快速实验,进行离线效果测试和在线的部署,并且我们还支持AutoML自动化调参,有了这些算法基建,可以帮助我们在云上快速的迭代推进效果。
(三)向量召回 – Hologres向量检索
Hologres深度集成阿里达摩院自研的向量检索引擎Proxima,这款向量检索引擎具有超大规模索引构建和检索、高纬&高精度、高性能低成本等核心能力,能够帮助Hologres提供提供低延时、高吞吐的在线查询服务。并且Hologres是以SQL的查询接口来暴露给用户的,十分简单易用,它能很容易支持水平扩展,因为它是分布式构建向量索引的方式。

(四)向量召回 – Hologres向量检索
在具体的推荐业务场景中,很重要的一环是向量查询,Hologres不仅能支持全量item集合上的检索,面对复杂条件下的检索, holo也能用sql的形式来支持。例如有很多推荐场景需要查询最近活跃,当需要查询某个类目下的,此时写一个Where语句就能很容易的完成检索。
全量检索
select id, pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3}')) as distance where data_time between '1990-11-11 12:00:00' and '1990-11-11 13:00:00’ and tag in ('X', 'Y', ‘Z') from feature_tb order by distance asc limit 10;
复杂条件下检索
select id, pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3}')) as distance where data_time between '1990-11-11 12:00:00' and '1990-11-11 13:00:00’ and tag in ('X', 'Y', ‘Z') from feature_tb order by distance asc limit 10;
某社交APP首页推荐
(一)最佳实践 – 某社交APP首页推荐
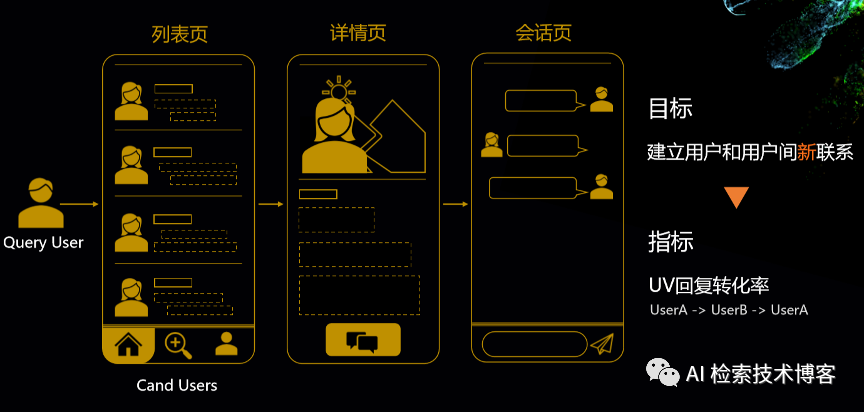
我们以一个社交APP的首页推荐的场景来体感一下这整套解决方案是怎么运行的。这是一个社交APP首页推荐的场景,分为列表页、详情页和会话页,通过点击列表页,可以看到用户的具体详情,进而发起会话进行聊天。整个首页推荐的目标是要建立用户和用户之间的新联系,因此我们设计了UV回复转化率这个指标,就是必须用户回复,才算一个有效的会话。
(二)最佳实践 –首页推荐方案
我们来看一下整个首页推社交APP首页推荐问题的难点。
算法需具备发现性,能建立新联系 ;“有效回复”优化目标非常稀疏,这导致我们优化整个模型的难度也非常高。
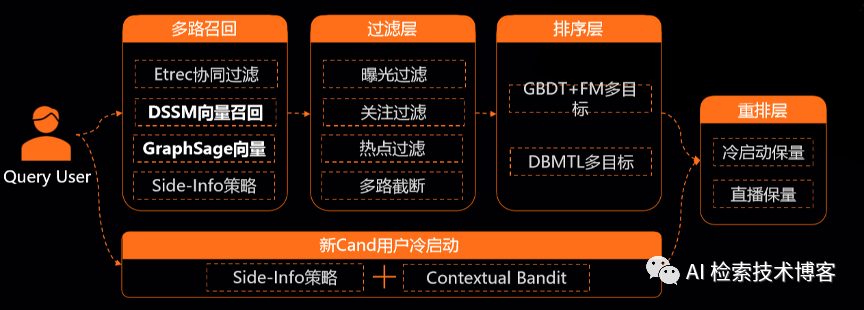
下面是整个首页推荐的方案,我们有常见的多路召回、过滤、排序和用户的冷启动和最后会有一个重排。其中的重点是召回里面DSSM的向量召回和GraphSage的向量召回,还有新用户的冷启动,这保证了整体的算法具有发现性。然后另一块是排序这边做了一个多目标的模型,包括点击、关注、会话和回复,多个目标的层次递进的关系,解决了有效回复这个目标非常稀疏的问题。
(三)最佳实践 – 向量召回算法 PAI-EasyRec | DSSM
重点来看一下其中向量召回,我们以其中的DSSM为例,
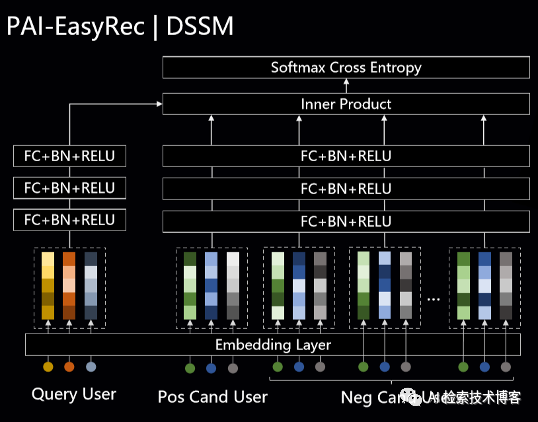
它是一个典型的双塔架构,优势是能充分利用Side-Info , 能支持分布式训练时的负采样和负样本MiniBatch内的共享。
(四)最佳实践 – 向量召回算法 PAI-EasyRec | DSSM – 优化技巧
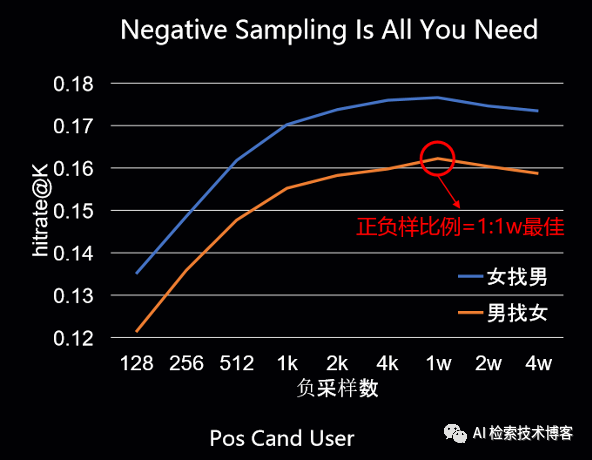
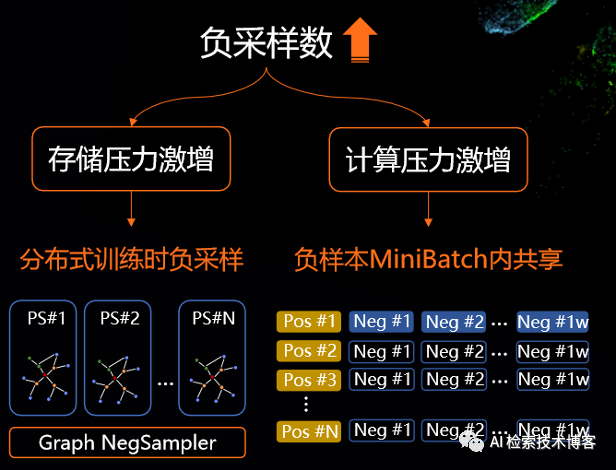
双塔架构上模型一个核心的问题点是怎么做负采样?负采样决定了整个召回模型效果的好坏,我们来看这个离线hitrate的曲线,可以看到随着负采量数的增加,基本上是一个稳步上涨的趋势,最高点是正负样本比例等于1:1W的时候最佳。所以当然随着负采样数的增加,特别是要达到1:1W的采样,对于存储的压力和计算压力都是非常大的。我们想要离线的去join出这个1:1W的正负样本来做存储基本是不太现实的。因此PAI-EasyRec支持在分布式训练时的实时的负采样,我们在存储的时候只存点击的正样本,在训练时分布式采样出相应的负样本来做训练。
下面是我们做分布式负采样的方案,其实是将用户的历史行为和用户的一些属性特征,以图结构形式存在参数服务器上,然后基于我们从参数服务器上进行实时的负采样,跟正样本join起来进行训练。1:1W正负样本对于我们的计算压力也是提出了很大的挑战。在PAI-EasyRec在里面我们做了一个优化, MiniBatch内负样本是共享的,不用将N*1W个负样本都计算一次,它只需要整体计算1W次,在做内积的时候以矩阵乘的方式展开,就可以达到简化共享负样本计算的效果。
(五)最佳实践 – HOLO向量检索
我们再来看一下工程系统在首页推荐上实践的HOLO向量检索,我们首先需要在Hologres中建立向量表,建表的语句也非常简单,其中重点是要在其中设置proxima的向量引擎和其他向量引擎所需要的检索参数,有了这样的向量表,我们就很容易的把MaxCompute上的外表数据来导入到Hologres中,这是一个异性推荐的场景,我们就可以在性别条件下进行向量的检索。

(六)最佳实践 – 首页推荐效果
推荐解决方案使得社交APP首页推荐的UV回复转化率提升了39%,UV会话转化率提升了30%,是一个很成功的案例。

(七)PAI上其他向量算法能力
PAI上其实还提供了很多其他的向量算法能力,包括图像的、文本的PAI-EasyVision、PAI-EasyTransfer,PAI-EasyTransfer已经在github上开源了,我们在PAI上还有人脸人脸匹配的能力、图片搜索能力、问答匹配的能力等等,都可以用到其中的向量引擎。欢迎大家来使用。


“ AI 检索技术博客”
由阿里巴巴达摩院系统 AI 实验室创立,
关注 “ AI 检索技术博客” 公众号,
获取更多技术干货文章、
AI 检索领域 Meetup 动态。