
如何锁住数据库中几十亿小姐姐?
数据库中有一张叫后宫佳丽的表,每天都有几百万新的小姐姐插到表中,光阴荏苒,夜以继日,日久生情,时间长了,表中就有了几十亿的小姐姐数据。

看到几十亿的小姐姐,每到晚上,我可愁死了,这么多小姐姐,我翻张牌呢?
办法当然是精兵简政,删除那些 age>18 的,给年轻的小姐姐们留位置...
delete from `后宫佳丽` where age>18
一开始还自我感觉良好,后面我就发现不对了,每到周日,这个脚本一执行就是一整天。

为什么?编不下去了,真实背景是公司中遇到的一张有海量数据表,每次一旦执行历史数据的清理,我们的程序就因为读不到这张表的数据,疯狂地报错。
后面一查了解到,原来是因为定时删除的语句设计不合理,导致数据库中数据由行锁(Row lock)升级为表锁(Table lock)了!?
解决这个问题的过程中把数据库锁相关的学习了一下,这里把学习成果,分享给大家,希望对大家有所帮助。
我将讨论 SQL Server 锁机制以及如何使用 SQL Server 标准动态管理视图监视 SQL Server 中的锁,相信其他数据的锁也大同小异,具有一定参考意义。
铺垫知识
在我开始解释 SQL Server 锁定体系结构之前,让我们花点时间来描述ACID(原子性,一致性,隔离性和持久性)是什么。
ACID 是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:
原子性(atomicity,或称不可分割性)
一致性(consistency)
隔离性(isolation,又称独立性)
持久性(durability)
ACID
①原子性(Atomicity)
一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。
事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
②一致性(Consistency)
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
③隔离性(Isolation)
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。
④持久性(Durability)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
https://zh.wikipedia.org/wiki/ACID
事务(Transaction)
事务是进程中最小的堆栈,不能分成更小的部分。
此外,某些事务处理组可以按顺序执行,但正如我们在原子性原则中所解释的那样,即使其中一个事务失败,所有事务块也将失败。
锁定(Lock)
锁定是一种确保数据一致性的机制。SQL Server 在事务启动时锁定对象。事务完成后,SQL Server 将释放锁定的对象。可以根据 SQL Server 进程类型和隔离级别更改此锁定模式。
这些锁定模式是:
①锁定层次结构
SQL Server 具有锁定层次结构,用于获取此层次结构中的锁定对象。数据库位于层次结构的顶部,行位于底部。

②共享(S)锁(Shared (S) Locks)
当需要读取对象时,会发生此锁定类型。这种锁定类型不会造成太大问题。
③独占(X)锁定(Exclusive (X) Locks)
发生此锁定类型时,会发生以防止其他事务修改或访问锁定对象。
④更新(U)锁(Update (U) Locks)
此锁类型与独占锁类似,但它有一些差异。我们可以将更新操作划分为不同的阶段:读取阶段和写入阶段。
在读取阶段,SQL Server 不希望其他事务有权访问此对象以进行更改,因此,SQL Server 使用更新锁。
⑤意图锁定(Intent Locks)
当 SQL Server 想要在锁定层次结构中较低的某些资源上获取共享(S)锁定或独占(X)锁定时,会发生意图锁定。
实际上,当 SQL Server 获取页面或行上的锁时,表中需要设置意图锁。
SQL Server locking
了解了这些背景知识后,我们尝试再 SQL Server 找到这些锁。SQL Server 提供了许多动态管理视图来访问指标。
要识别 SQL Server 锁,我们可以使用 sys.dm_tran_locks 视图。在此视图中,我们可以找到有关当前活动锁管理的大量信息。
CREATE TABLE TestBlock
(Id INT ,
Nm VARCHAR(100))
INSERT INTO TestBlock
values(1,'CodingSight')
In this step, we will create an open transaction and analyze the locked resources.
BEGIN TRAN
UPDATE TestBlock SET Nm='NewValue_CodingSight' where Id=1
select @@SPID
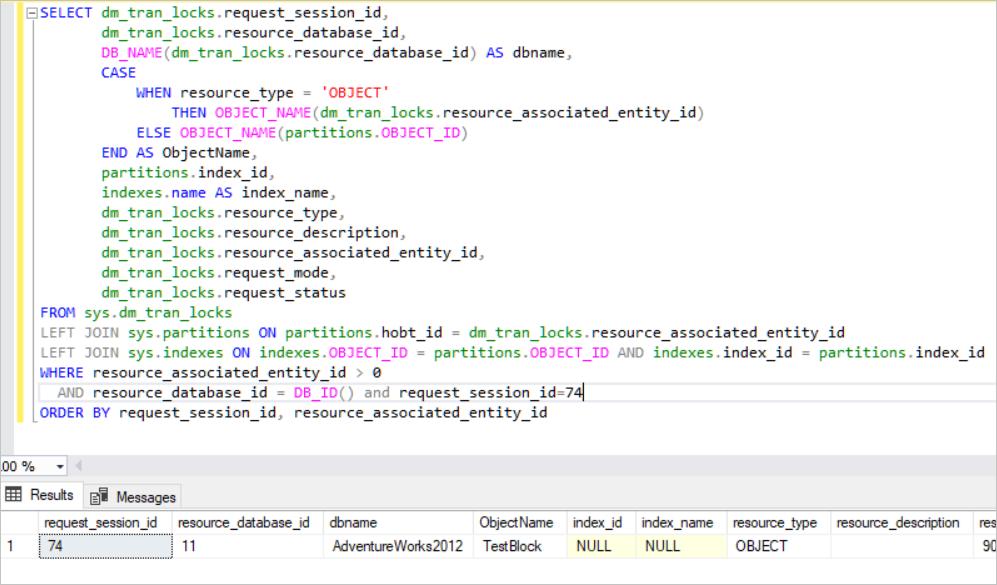
select * from sys.dm_tran_locks WHERE request_session_id=74

此视图返回有关活动锁资源的大量信息,但是是一些我们难以理解的一些数据。
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
and request_session_id=74
ORDER BY request_session_id, resource_associated_entity_id

在上图中,您可以看到锁定的资源。SQL Server 获取该行中的独占锁。(RID:用于锁定堆中单个行的行标识符)同时,SQL Server 获取页中的独占锁和 TestBlock 表意向锁。
这意味着在 SQL Server 释放锁之前,任何其他进程都无法读取此资源,这是 SQL Server 中的基本锁定机制。
现在,我们将在测试表上填充一些合成数据:
TRUNCATE TABLE TestBlock
DECLARE @K AS INT=0
WHILE @K <8000
BEGIN
INSERT TestBlock VALUES(@K, CAST(@K AS varchar(10)) + ' Value' )
SET @K=@K+1
END
--After completing this step, we will run two queries and check the sys.dm_tran_locks view.
BEGIN TRAN
UPDATE TestBlock set Nm ='New_Value' where Id<5000

BEGIN TRAN
UPDATE TestBlock set Nm ='New_Value' where Id<7000
在上面的查询中,SQL Server 在表上创建了独占锁,因为 SQL Server 尝试为这些将要更新的行获取大量 RID 锁。
这种情况会导致数据库引擎中的大量资源消耗,因此,SQL Server 会自动将此独占锁定移动到锁定层次结构中的上级对象(Table)。
我们将此机制定义为 Lock Escalation,这就是我开篇所说的锁升级,它由行锁升级成了表锁。
根据官方文档的描述存在以下任一条件,则会触发锁定升级:
单个 Transact-SQL 语句在单个非分区表或索引上获取至少 5,000 个锁。
单个 Transact-SQL 语句在分区表的单个分区上获取至少 5,000 个锁,并且 ALTER TABLE SET LOCK_ESCALATION 选项设置为 AUTO。
数据库引擎实例中的锁数超过了内存或配置阈值。
链接如下:
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms184286(v=sql.105)
如何避免锁升级
防止锁升级的最简单,最安全的方法是保持事务的简短,并减少昂贵查询的锁占用空间,以便不超过锁升级阈值,有几种方法可以实现这一目标。
①将大批量操作分解为几个较小的操作
delete from `后宫佳丽` where age>18
我们可以不要这么心急,一次只删除 500 个,可以显着减少每个事务累积的锁定数量并防止锁定升级。
SET ROWCOUNT 500
delete_more:
delete from `后宫佳丽` where age>18
IF @@ROWCOUNT > 0 GOTO delete_more
SET ROWCOUNT 0
②创建索引使查询尽可能高效来减少查询的锁定占用空间
如果没有索引会造成表扫描可能会增加锁定升级的可能性,更可怕的是,它增加了死锁的可能性,并且通常会对并发性和性能产生负面影响。
根据查询条件创建合适的索引,最大化提升索引查找的效率,此优化的一个目标是使索引查找返回尽可能少的行,以最小化查询的的成本。
③如果其他 SPID 当前持有不兼容的表锁,则不会发生锁升级
锁定升级始总是升级成表锁,而不会升级到页面锁定。
如果另一个 SPID 持有与升级的表锁冲突的 IX(intent exclusive)锁定,则它会获取更细粒度的级别(行,key 或页面)锁定,定期进行额外的升级尝试。
表级别的 IX(intent exclusive)锁定不会锁定任何行或页面,但它仍然与升级的 S(共享)或 X(独占)TAB 锁定不兼容。
BEGIN TRAN
SELECT * FROM mytable (UPDLOCK, HOLDLOCK) WHERE 1=0
WAITFOR DELAY '1:00:00'
COMMIT TRAN
此查询在 mytable 上获取并保持 IX 锁定一小时,这可防止在此期间对表进行锁定升级。
Happy Ending
长按关注,学习更多
推荐阅读