
背诵不等于理解,深度解析大模型背后的知识储存与提取
自然语言模型的背诵 (memorization) 并不等于理解。即使模型能完整记住所有数据,也可能无法通过微调 (finetune) 提取这些知识,无法回答简单的问题。


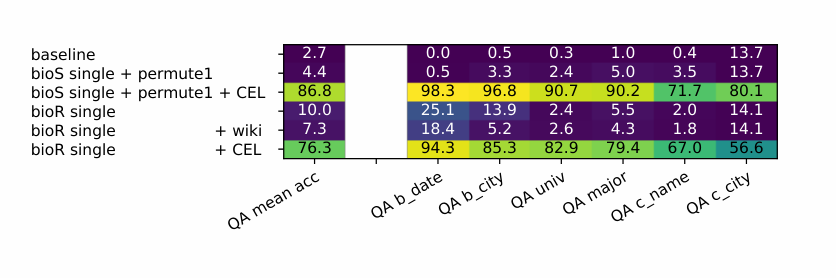
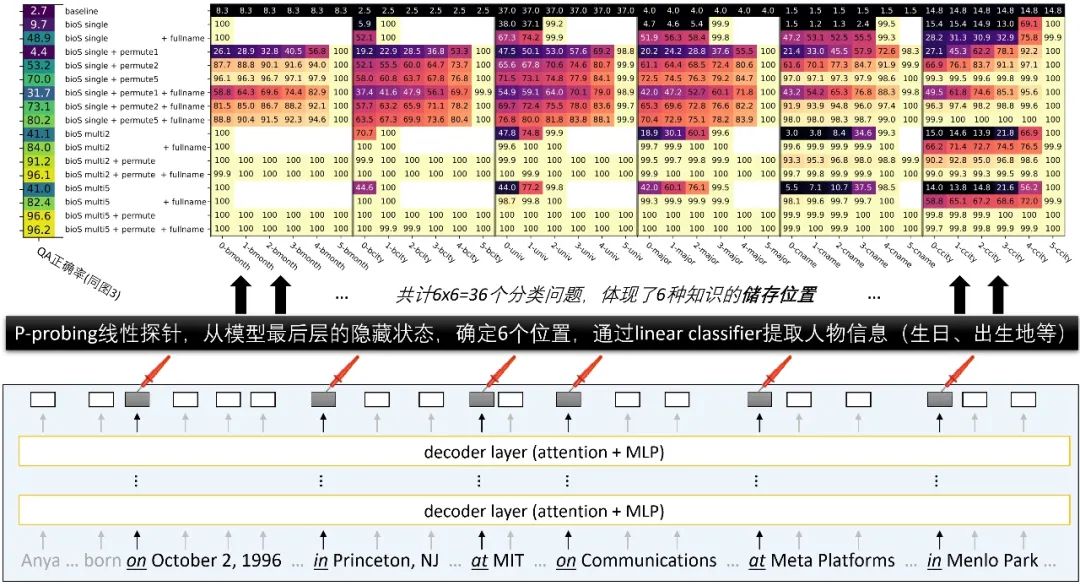
Anya Briar Forger was born on October 2, 1996. She spent her early years in Princeton, NJ. She received mentorship and guidance from faculty members at MIT. She completed her education with a focus on Communications. She had a professional role at Meta Platforms. She was employed in Menlo Park, CA.

Anya Briar Forger originated from Princeton, NJ. She dedicated her studies to Communications. She gained work experience in Menlo Park, CA. She developed her career at Meta Platforms. She came into this world on October 2, 1996. She pursued advanced coursework at MIT.

......
评论