
万字长文剖析C语言结构体的高级用法
ID:txp学Linux
作者:txp
前言
在写这篇文章之前,说实话,自身对结构体的用法,只会两点——就是点访问式和指针式访问结构体内部成员。这对一个搞底层的工程师来讲,显然实在太low了。不妨读者看到这里,可以停下来思索一下,看看自己对c语言结构体掌握了多少。下面是我这几天结合自己的学习而总结的一篇算比较全的关于结构体的用法,欢迎大家来吐槽。
其实在之前的文章里面,我已经有说为啥在c语言里面要引入结构体这一概念——超详细的链表学习,这里的话,我就不再废话了,直接来点实际的。
一、结构体的各种使用方法(很全):
这里的话,我以实际例子直接开干,就不过多的介绍一些非常基础的东西(有没看明白的读者可以上网查)。
1# include
2# include
3
4struct Student {
5 char name[20];
6 float fScore[3];
7}student = {"dire",98.5,89.0,93.5}; //初始化结构体变量
8
9
10void Display(struct Student *pStruct)
11{
12 printf("------Information-------\n");
13 printf("Name:%s\n",pStruct->name);
14 printf("Chinese:%.2f\n",(*pStruct).fScore[0]);
15 printf("Math:%.2f\n",(*pStruct).fScore[1]);
16 printf("English:%.2f\n",pStruct->fScore[2]);
17}
18
19
20int main ()
21{
22 Display(&student); //将结构体变量的首地址作为实参传入pStruct指针变量中
23
24 return 0;
25}

说明:
b、再来看一个示例(结构体变量做形参):
1 #include
2 typedef struct A{
3 int a;
4 }s;
5 void fun(s b)
6 {
7 b.a=99;
8 printf("the b.a is %d\n",b.a);
9 }
10 int main(void)
11 {
12 s c; //这里的s等价于struct A
13 c.a=8;
14 printf("the c.a is %d\n",c.a);
15
16 fun(c);
17
18 return 0;
19 }
演示结果:

说明:
2、结构体数组的几种使用形式:
a、结构体数组示例:
1 #include
2 struct{
3 char *name; //姓名
4 int num; //学号
5 int age; //年龄
6 char group; //所在小组
7 float score; //成绩
8 }class[5] = {
9 {"Li ping", 5, 18, 'C', 145.0},
10 {"Zhang ping", 4, 19, 'A', 130.5},
11 {"He fang", 1, 18, 'A', 148.5},
12 {"Cheng ling", 2, 17, 'F', 139.0},
13 {"Wang ming", 3, 17, 'B', 144.5}
14};
15int main()
16{
17 int i, num_140 = 0;
18 float sum = 0;
19 for(i=0; i<5; i++)
20 {
21 sum += class[i].score;
22 if(class[i].score < 140) num_140++;
23 }
24 printf("sum=%.2f\naverage=%.2f\nnum_140=%d\n", sum, sum/5, num_140);
25 return 0;
26 }
演示结果:

说明:
上面的结构体数组class[5]相当于数组里面的每个一个元素是一个结构体。
b、结构体指针数组:
1 #include
2 typedef struct A{
3 int a;
4 }s,*st;
5 int main(void)
6 {
7 s stu1,stu2;
8 st array[2];
9 stu1.a=2;
10 stu2.a=3;
11 array[0]=&stu1;
12 array[1]=&stu2;
13 printf("thearray[0]=%d,array[1]=%d\n",array[0]- >a,array[1]->a);
14
15 return 0;
16 }
演示结果:

说明:
1 #include
2 struct R{
3int a;
4int b;
5char *name;
6}s[3]={{2,4,"like"},{3,5,"like"},{2,4,"like"}};
7int main(void)
8{
9 struct R (*array)[3];
10 array=&s;
11 printf("the array->b is %d\n",array[0]->a);
12
13return 0;
14 }
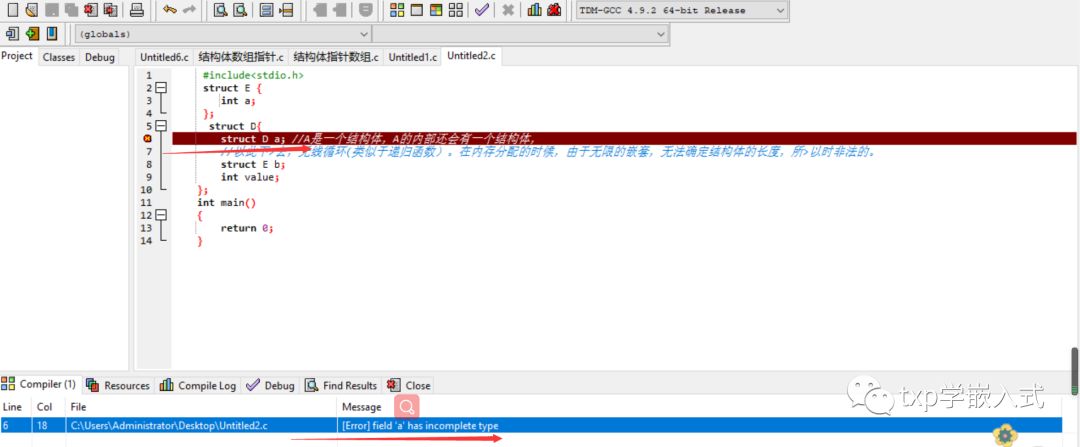
c、结构体里面嵌套结构体数组(这里就顺便也讲了结构体嵌套的知识点了):
结构体嵌套的问题有哪些?
----结构体的自引用,就是在结构体内部,包含指向自身类型结构体的指针。
----结构体的相互引用,就是说在多个结构体中,都包含指向其他结构体的指针
结构体应该注意的问题?
----结构体定义中可以嵌套其他结构体类型的变量,不可以嵌套自己这个类型的变量。
1 #include
2 struct E {
3 int a;
4 };
5 struct D{
6 struct D a; //A是一个结构体,A的内部还会有一个结构体,
7 //以此下>去,无线循环(类似于递归函数)。在内存分配的时候,由于无限的嵌套,无法确定结构体的长度,所>以时非法的。
8 struct E b;
9 int value;
10};
11int main()
12{
13 return 0;
14}
演示结果:
----可以嵌套自己类型的指针。
1 #include
2 struct E {
3 int a;
4 };
5 struct D{
6
7 struct D *c;
8 struct E b;
9 int value;
10};
11int main()
12{
13 return 0;
14}说明:
由于指针的长度时确定的(在32位机器上指针长度是4),所以编译器能够确定该
结构体的长度。
这个指针看似指向自身,其实不是,而是执行同一类型的不同结构。
综合应用:
1#include
2 struct A{
3int year;
4int month;
5int day;
6 };
7
8 struct B{
9 long int num;
10 struct A a;
11 // struct A *b;
12 struct A array[3];
13 char *name;
14}s1={200,{1998,2,3},{{1999,3,4},{1999,5,6},
15 {1999,7,8}},"wangwu"};
16
17 int main(void)
18 {
19 struct B s2;
20 s2=s1;
21 printf("%ld %s %d\n",s2.num,s2.name,sizeof(int));
22printf("year:%d,month:%d,day:%d\n",s2.a.year,s2.a.month,s2.a.day);
23printf("year:%d,month:%d,day:%d\n",s2.array[0].year,s2.array[0].month,s2.array[0].day);
24printf("year:%d,month:%d,day:%d\n",s2.array[1].year,s2.array[1].month,s2.array[1].day);
25printf("year:%d,month:%d,day:%d\n",s2.array[2].year,s2.array[2].month,s2.array[2].day);
26 return 0;
27 }
演示结果:
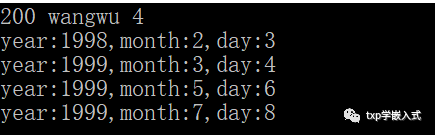
说明:
在这里我们可以看到,结构体之间是可以进行赋值的,就比如s2=s1,这样就可以用结构体变量s2来继续访问结构体里面的各个成员(可以达到同样的效果的)。这里在结构体里面嵌套了结构体变量和结构体数组,用法和不嵌套的时候是一样的。下面我们关键来讲一下这个结构体里面嵌套结构体指针,该怎样来操作呢,这是要讲的重点了(读者看到这里也可以先想想该如何进行操作):
1 #include
2 struct B{
3 long int num;
4 struct B*b;
5 }s1={200,0};
6
7 int main(void)
8 {
9struct B s2={200,&s1
10};
11
12 printf("the s2.num=%ld\n",s2.num);
13 printf("(*(s2.b)).num=%ld\n",(*(s2.b)).num);
14
15return 0;
16 }
演示结果:

说明:
这里操作的话,转了一个弯来,总之还是那句话,你在使用指针的时候,记得事先一定要给它赋有效的地址值,千万不要是NULL(关于这个原因可以看这里——c专题之指针---野指针和空指针解析)。下面是我在网上看到的多嵌套的写法(大家只要了解一下就行,实际写代码不会这样搞,这样搞确实是比较恶心):
1 #include
2 struct s1
3 {
4 float a;
5 struct
6 {
7 int ba;
8 int bb;
9
10 struct
11 {
12 int bca;
13 int (*bcb)[3];//数组指针
14 } *bc;
15 } b;
16 };
17int main( void )
18{
19int a[3]={3};
20struct
21{
22 int bca;
23 int (*bcb)[3];
24}bc=
25{
26 3,
27 &a
28};
29
30struct s1 s=
31{
32 3.14,
33 {
34 1,
35 2,
36 ( void* )&bc
37 }
38};
39 struct s1 *p=&s;
40 printf("%d\n",*(p->b.bc->bcb)[0]);
41 return 0;
42 }
演示结果:

3、结构体函数指针:
1 #include
2 #include
3 struct A{
4int(*add)(int a,int b);//函数指针
5int(*sub)(int a,int b);
6int(*mult)(int a,int b);
7 };
8 int test_add(int a,int b)
9 {
10 return (a+b);
11 }
12 int test_sub(int a,int b)
13 {
14 return (a-b);
15 }
16 int test_mult(int a,int b)
17 {
18 return (a*b);
19 }
20 void print_usage()
21 {
22 printf("打印用法\n");
23 }
24 int main(int argc,char **argv)
25 {
26 struct A s={
27 .add=test_add,
28 .sub=test_sub,
29 .mult=test_mult,
30 };
31 int a=9,b=3;
32 printf("a+b=%d\n",s.add(a,b));
33 printf("a-b=%d\n",s.sub(a,b));
34 printf("a*b=%d\n",s.mult(a,b));
35
36 return 0;
37 }
演示结果:

说明:
用法还是和函数指针的用法一样,区别不大。
二、高级用法小结:
上面汇总了一些结构体的高级用法,有些不怎么常见,但是开阔一些眼界还是有的,哈哈。
三、结构体对齐问题:
1、在讨论这个问题之前,我们先来看一个代码示例:
1 #include
2 struct A{
3
4 };
5 int main(void)
6 {
7
8 printf("the struct A is %d\n",sizeof(struct A));
9
10 return 0;
11 }
演示结果:

在gcc编译环境演示结果:
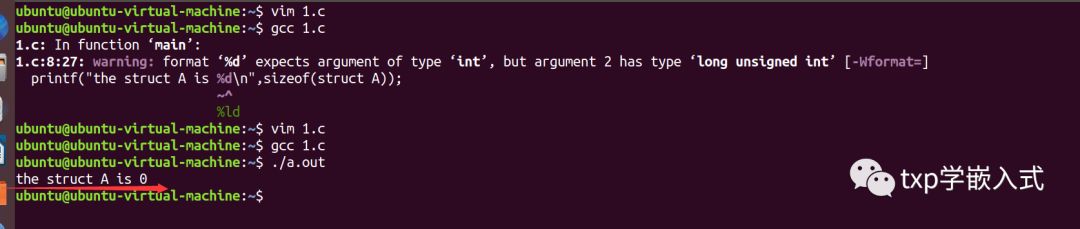
说明:
1#include
2struct student
3{
4
5};
6int main(void)
7{
8 printf("the struct A is %d\n",sizeof(struct student));
9
10 return 0;
11
12
13 }
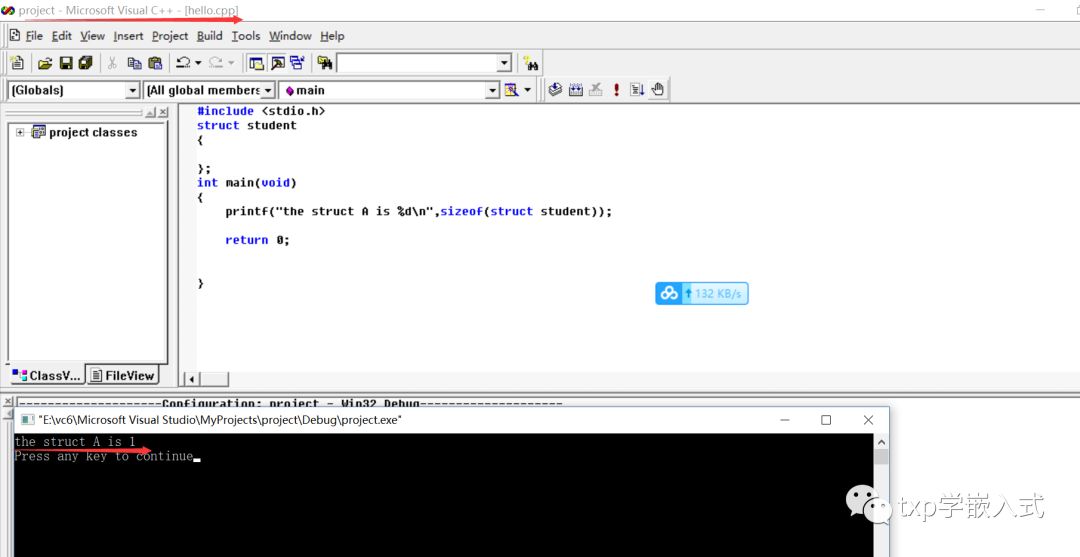

1 #include
2 struct A{
3 int a;
4 char b;
5 float c;
6 };
7 int main(void)
8 {
9 printf("the int is %d\n",sizeof(int));
10 printf("the char is %d\n",sizeof(char));
11 printf("the float is %d\n",sizeof(float));
12 printf("the struct A is %d\n",sizeof(struct A));
13 return 0;
14 }

在C语言中,结构体是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元(我上面有介绍)。在结构中,编译器为结构体的每个成员按其自然边界(alignment)分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。为了使CPU能够对变量进行快速的访问,变量的起始地址应该具有某些特性,即所谓的”对齐”. 比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除。
b、为啥要字节对其呢,主要有以下几种原因:
(1)结构体中元素对齐访问主要原因是为了配合硬件,也就是说硬件本身有物理上的限制,如果对齐排布和访问会提高效率,否则会大大降低效率。
(2)内存本身是一个物理器件(DDR内存芯片,SoC上的DDR控制器),本身有一定的局限性:如果内存每次访问时按照4字节对齐访问,那么效率是最高的;如果你不对齐访问效率要低很多。
(3)还有很多别的因素和原因,导致我们需要对齐访问。譬如Cache的一些缓存特性,还有其他硬件(譬如MMU、LCD显示器)的一些内存依赖特性,所以会要求内存对齐访问。
(4)对比对齐访问和不对齐访问:对齐访问牺牲了内存空间,换取了速度性能;而非对齐访问牺牲了访问速度性能,换取了内存空间的完全利用。
小结:说白了,就是为访问结构体成员效率高,也就是读取数据更为高效(但是这里也会牺牲一点点内存)。
c、我们还是用上面的那个例子来分析
1 #include
2 struct A{
3 int a;
4 char b;
5 float c;
6 };
7 int main(void)
8 {
9 printf("the int is %d\n",sizeof(int));//4
10 printf("the char is %d\n",sizeof(char));//1
11 printf("the float is %d\n",sizeof(float));//4
12 printf("the struct A is %d\n",sizeof(struct A));//12
13 return 0;
14 }
分析过程:
首先是整个结构体,整个结构体变量4字节对齐是由编译器保证的,我们不用操心。然后是第一个元素a,a的开始地址就是整个结构体的开始地址,所以自然是4字节对齐的。但是a 的结束地址要由下一个元素说了算。然后是第二个元素b,因为上一个元素a本身占4字节,本身就是对齐的。所以留给b的开始地址也是 4字节对齐地址,所以b可以直接放(b放的位置就决定了a一共占4字节,因为不需要填充)。b的起始地址定了后,结束地址不能定(因为可能需要填充,所谓填充就是我上面说的要浪费一点内存了,但是没关系啦,我们提高了访问速度,不用多次去访问。),结束地址要看下一个元素来定。然后是第三个元素c,float类型需要4字节对齐(float类型元素必须放在类似0,2,4,8这样的 地址处,不能放在1,3这样的奇数地址处),因此c不能紧挨着b来存放,解决方案是在b之后添加3字节的填充(padding),然后再开始放c。c放完之后还没结束 当整个结构体的所有元素都对齐存放后,还没结束,因为整个结构体大小还要是4的整数倍,这一点非常重要,所以最后就是12个字节啦。下面是我用示意头图来展示:
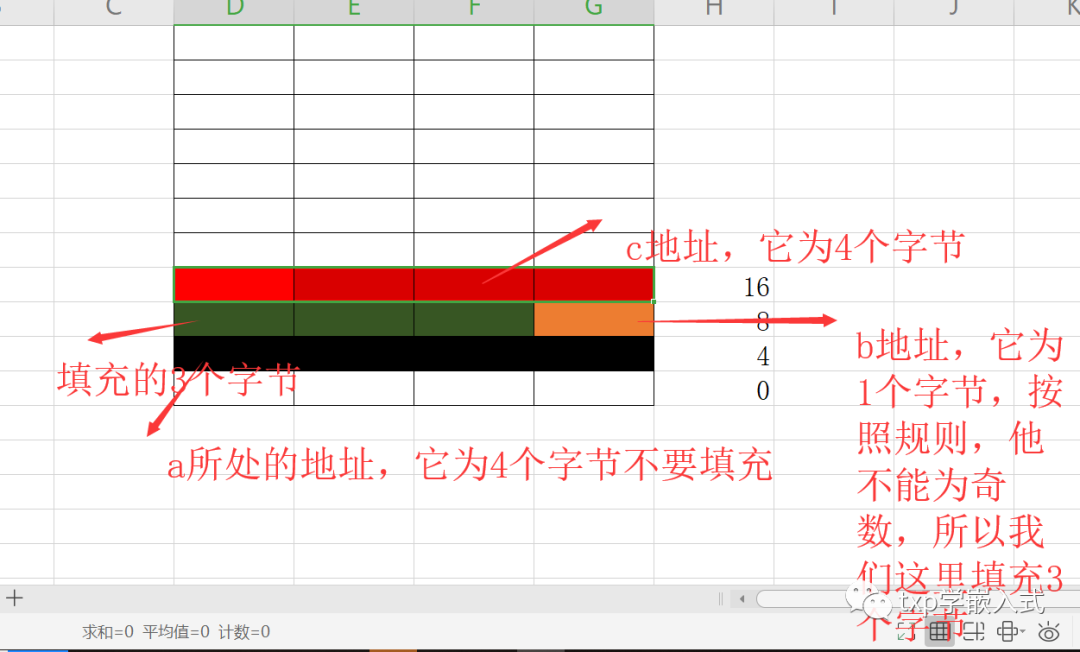
这里我还要说明一下,有人可能有这样的疑惑,b加一个字节不就是2个字节了吗,然后c直接放到b后面就可以了,这样cpu在访问的时候,也只要访问三次(加起来就是10个字节了),但是这符合我上面说的那个规律(不能被4字节整除,哈哈哈,而且要注意的是,这里我是在32位环境下操作的,这个很关键,不同环境结果会不一样)。
下面我再举几个例子来演示(这里我就不仔细分析了,读者可以牛刀小试一下):
1 #include
2 struct mystruct1
3 { // 1字节对齐 4字节对齐
4 int a; // 4 4
5 char b; // 1 2(1+1)
6 short c; // 2 2
7 };
8
9
10 struct mystruct21
11 { // 1字节对齐 4字节对齐
12 char a; // 1 4(1+3)
13 int b; // 4 4
14 short c; // 2 4(2+2)
15 };
16 typedef struct myStruct5
17 { // 1字节对齐 4字节对齐
18 int a; // 4 4
19 struct mystruct1 s1; // 7 8
20 double b; // 8 8
21 int c; // 4 4
22 }MyS5;
23
24 struct stu
25 { // 1字节对齐 4字节对齐
26 char sex; // 1 4(1+3)
27 int length; // 4 4
28 char name[10]; // 10 12(10+2)
29 };
30
31 int main(void)
32 {
33 printf("the struct mystruct1 is %d\n",sizeof( struct mystruct1 ));
34 printf("the struct mystruct21 is %d\n",sizeof( struct mystruct21));
35
36 printf("the MyS5 is %d\n",sizeof(struct myStruct5));
37 printf("struct stu is %d\n",sizeof( struct stu));
38
39
40 return 0;
41 }
演示输出结果:

(1)#pragma是用来指挥编译器,或者说设置编译器的对齐方式的。编译器的默认对齐方式是4,但是有时候我不希望对齐方式是4,而希望是别的(譬如希望1字节对齐,也可能希望是8,甚至可能希望128字节对齐)。
(2)常用的设置编译器编译器对齐命令有2种:第一种是#pragma pack(),这种就是设置编译器1字节对齐(有些人喜欢讲:设置编译器不对齐访问,还有些讲:取消编译器对齐访问);第二种是#pragma pack(4),这个括号中的数字就表示我们希望多少字节对齐。
(3)我们需要#prgama pack(n)开头,以#pragma pack()结尾,定义一个区间,这个区间内的对齐参数就是n。
(4)#prgma pack的方式在很多C环境下都是支持的,但是gcc虽然也可以,不过不建议使用。
1 #include
2 #pragma pack(1)
3 struct mystruct1
4 { // 1字节对齐 4字节对齐
5 int a; // 4 4
6 char b; // 1 2(1+1)
7 short c; // 2 2
8 };
9
10
11 struct mystruct21
12 { // 1字节对齐 4字节对齐
13 char a; // 1 4(1+3)
14 int b; // 4 4
15 short c; // 2 4(2+2)
16 };
17 struct myStruct5
18 { // 1字节对齐 4字节对齐
19 int a; // 4 4
20 struct mystruct1 s1; // 7 8
21 double b; // 8 8
22int c; // 4 4
23 }MyS5;
24
25 struct stu
26 { // 1字节对齐 4字节对齐
27 char sex; // 1 4(1+3)
28 int length; // 4 4
29 char name[8]; // 8 12(10+2)
30 };
31 #pragma pack()
32 int main(void)
33 {
34 printf("the struct mystruct1 is %d\n",sizeof( struct mystruct1 ));
35 printf("the struct mystruct21 is %d\n",sizeof( struct mystruct21));
36
37 printf("the MyS5 is %d\n",sizeof(struct myStruct5));
38 printf("struct stu is %d\n",sizeof( struct stu));
39
40 printf("%d",sizeof(struct mystruct1));
41 return 0;
42 }
输出演示结果:

说明:
通过实验现象,可以看到我设置了1字节(读者也可以尝试设置一下其他字节对齐,看看结果如何)。
5、gcc推荐的对齐指令__attribute__((packed)) __attribute__((aligned(n))):
(1)__attribute__((packed))使用时直接放在要进行内存对齐的类型定义的后面,然后它起作用的范围只有加了这个东西的这一个类型。packed的作用就是取消对齐访问。
1 #include
2
3 struct mystruct1
4 { // 1字节对齐 4字节对齐
5 int a; // 4 4
6 char b; // 1 2(1+1)
7 short c; // 2 2
8 }__attribute__((packed));
9
10 int main(void)
11 {
12
13 struct mystruct1 s2;
14
15 printf("s2 is %d\n",sizeof( s2));
16 return 0;
17 }
演示结果:

(2)__attribute__((aligned(n)))使用时直接放在要进行内存对齐的类型定义的后面,然后它起作用的范围只有加了这个东西的这一个类型。它的作用是让整个结构体变量整体进行n字节对齐(注意是结构体变量整体n字节对齐,而不是结构体内各元素也要n字节对齐)。
1 #include
2
3 typedef struct mystruct111
4 { // 1字节对齐 4字节对齐 2字节对齐
5 int a; // 4 4 4
6 char b; // 1 2(1+1) 2
7 short c; // 2 2 2
8 short d; // 2 4(2+2) 2
9 }__attribute__((aligned(32))) My111;
10
11int main(void)
12{
13 printf("My111 is %d\n",sizeof(My111 ));
14 return 0;
15 }
演示输出结果:

四、.offsetof宏与container_of宏:
1、通过结构体整体变量来访问其中各个元素,本质上是通过指针方式来访问的,形式上是通过.的方式来访问的(这时候其实是编译器帮我们自动计算了偏移量)。
1 #include
2
3 struct mystruct
4 {
5 char a;
6 int b;
7 short c;
8 };
9 int main(void)
10 {
11 struct mystruct s1;
12 s1.b = 12;
13
14 int *p = (int *)((char *)&s1 + 4);
15 printf("*p = %d.\n", *p);
16
17 printf("整个结构体变量的首地址:%p.\n", &s1);
18 printf("s1.b的首地址:%p.\n", &(s1.b));
19 printf("偏移量是:%d.\n", (char *)&(s1.b) - (char *)&s1);
20
21 return 0;
22 }
演示结果:

2、offsetof宏:
(1)offsetof宏的作用是:用宏来计算结构体中某个元素和结构体首地址的偏移量(其实质是通过编译器来帮我们计算)。
(2)offsetof宏的原理:我们虚拟一个type类型结构体变量,然后用type.member的方式来访问那个member元素,继而得到member相对于整个变量首地址的偏移量。
1#include
2
3 struct mystruct
4 {
5 char a;
6 int b;
7 short c;
8 };
9// TYPE是结构体类型,MEMBER是结构体中一个元素的元素名
10// 这个宏返回的是member元素相对于整个结构体变量的首地址的偏移量,类型是int
11 #define offsetof(TYPE, MEMBER) ((int) &((TYPE *)0)->MEMBER)
12 int main(void)
13 {
14 struct mystruct s1;
15 s1.b = 12;
16
17 int *p = (int *)((char *)&s1 + 4);
18 printf("*p = %d.\n", *p);
19
20
21 int offsetofa = offsetof(struct mystruct, a);
22 printf("offsetofa = %d.\n", offsetofa);
23
24 int offsetofb = offsetof(struct mystruct, b);
25 printf("offsetofb = %d.\n", offsetofb);
26
27 int offsetofc = offsetof(struct mystruct, c);
28 printf("offsetofc = %d.\n", offsetofc);
29
30
31
32
33 printf("整个结构体变量的首地址:%p.\n", &s1);
34 printf("s1.b的首地址:%p.\n", &(s1.b));
35 printf("偏移量是:%d.\n", (char *)&(s1.b) - (char *)&s1);
36
37 return 0;
38 }
演示结果:
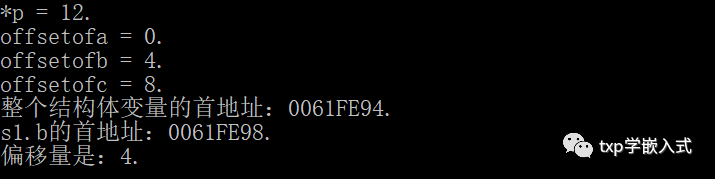
(TYPE *)0 这是一个强制类型转换,把0地址强制类型转换成一个指针, 这个指针指向一个TYPE类型的结构体变量。(实际上这个结构体变量可能不存在,但是只要我们不去解引用这个指针就不会出错)。((TYPE *)0)->MEMBER (TYPE *)0是一个TYPE类型结构体变量的指针,通过指针来访问这个结构体变量的member元素,&((TYPE *)0)->MEMBER 等效于&(((TYPE *)0)->MEMBER),意义就是得到member元素的地址。但是因为整个结构体变量的首地址是0,所以就可以计算出它的偏移量来。
3、container_of宏:
(1)作用:知道一个结构体中某个元素的指针,反推这个结构体变量的指针。有了container_of宏,我们可以从一个元素的指针得到整个结构体变量的指针,继而得到结构体中其他元素的指针。
(2)typeof关键字的作用是:typepef(a)时由变量a得到a的类型,typeof就是由变量名得到变量数据类型的。
(3)这个宏的工作原理:先用typeof得到member元素的类型定义成一个指针,然后用这个指针减去该元素相对于整个结构体变量的偏移量(偏移量用offsetof宏得到的),减去之后得到的就是整个结构体变量的首地址了,再把这个地址强制类型转换为type *即可。
1 #include
2
3 struct mystruct
4 {
5 char a;
6 int b;
7 short c;
8 };
9
10 // TYPE是结构体类型,MEMBER是结构体中一个元素的元素名
11 // 这个宏返回的是member元素相对于整个结构体变量的首地址的偏移量,类型是int
12 #define offsetof(TYPE, MEMBER) ((int) &((TYPE *)0)->MEMBER)
13
14 // ptr是指向结构体元素member的指针,type是结构体类型,member 是结构体中一个元素的元素名
15 // 这个宏返回的就是指向整个结构体变量的指针,类型是(type *)
16 #define container_of(ptr, type, member) ({ \
17const typeof(((type *)0)->member) * __mptr = (ptr); \
18(type *)((char *)__mptr - offsetof(type, member)); })
19
20 int main(void)
21 {
22 struct mystruct s1;
23 struct mystruct *pS = NULL;
24
25 short *p = &(s1.c); // p就是指向结构体中某个member的指针
26
27 printf("s1的指针等于:%p.\n", &s1);
28
29 // 问题是要通过p来计算得到s1的指针
30 pS = container_of(p, struct mystruct, c);
31 printf("pS等于:%p.\n", pS);
32
33
34 return 0;
35 }
演示结果:

说明:
其中代码难以理解的地方就是它灵活地运用了0地址(这个零地址可以看c专题之指针---野指针和空指针解析,还有const的位置运用,可以看超实用的const用法)。如果觉得&( (struct mystruct *)0 )->member这样的代码不好理解,那么我们可以假设在0地址分配了一个结构体变量struct mystruct a,然后定义结构体指针变量p并指向a(struct mystruct*p = &s1),如此我们就可以通过&p->c获得成员地址的地址。由于a的首地址为0x0,所以成员c的地址就如上图所以。
五、总结 :
上面的那个空结构体的问题,在实际中作用不大,了解即可!今天的分享就到这里了,晚安!(有关柔性数组的问题暂时先不讲),这里也可以看这边博客关于结构体对齐讲的比较细:https://www.cnblogs.com/dolphin0520/archive/2011/09/17/2179466.html。
---欢迎关注公众号,可以查看往期的文章,可以得到三本经典的c语言进阶电子书:
 推荐阅读:
推荐阅读:嵌入式编程专辑 Linux 学习专辑 C/C++编程专辑 关注微信公众号『技术让梦想更伟大』,后台回复“m”查看更多内容,回复“加群”加入技术交流群。 长按前往图中包含的公众号关注