
Transformer-XL 2019.06
《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
https://arxiv.org/pdf/1901.02860.pdf
2019年6月
卡内基梅隆大学、谷歌
基础知识

1. 背景
RNNs很难优化,因为存在梯度消失和梯度爆炸问题,虽然引入了门控机制(如LSTM),和梯度裁剪技术,但依然无法从根本上解决问题
Vanilla Transformer(2018)设计了一些列辅助损失来训练64层深的Transformer字符级LM,超越了LSTMs。但是Vanilla Transformer的每条样本都是分开的、固定长度的片段,片段样本之间没有信息传递。因此产生两个问题:
无法捕捉更长程的依赖
在分割片段样本时,为了维持固定长度,没有达到固定长度的片段样本用连续符号块组成,这样就没有考虑语义边界
2. 思想
在片段样本之间构建循环连接来传播隐含信息,即不用对每个样本都从头开始去计算其隐含信息,而是利用前一个片段的隐含信息作为memory计算当前样本隐含信息,以此来解决上下文断开的问题。
使用相对位置编码,使得在重用(reuse)隐含信息时,不会产生时序困惑(temporal confusion)
3. 模型
论文在介绍模型的时候,花了一部分篇幅介绍 Vanilla Transformer(2018) 的语言模型,为了突出两个问题:
fixed-length segments will lead to the context fragmentation problem
evaluation procedure is extremely expensive
3.1 复用隐含状态的segment-level循环机制
从数学表达上看,假设两个连续的片段样本,
假设 的第 层的隐含信息为 ,其中 是隐含信息维度,
其中 表示停止梯度下降更新。
下面是训练阶段示意图,假设有3层transformer encoder,每个segment(样本片段)长度固定为4,虚线框表示上一个样本的计算结果被固定缓存起来用于当前样本计算。每个橙色(和浅橙色)小圆圈表示一个Transformer encoder层,蓝色(和浅蓝色)小圈都表示第 步token的embedding(词嵌入+位置编码)。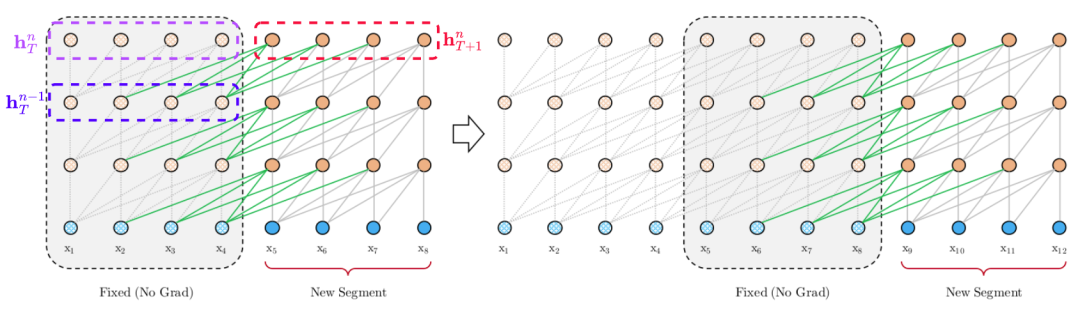
理论上,模型不仅可以用前一样本(样本之间保持时序),而且可以用前 个样本,只要有足够的的GPU计算资源,论文中只是固定缓存了前1个样本的隐含信息。但是要注意,固定前一个样本的隐含信息,是包括前一样本所有时间步的隐含信息(比如上图中红色虚线框表示 ),但不是所有时间步的隐含信息都会被当前样本用上,比如蓝色虚线框的 中,只有后面三个时间步的隐含信息才被红色虚线框的 用上。所以这里和RNN是很不一样的,RNN会用上紫色虚线框的隐含信息 来计算红色虚线框隐含信息 。那当前时间步用上历史多久之前的隐含信息呢?论文将这个长度设置为和样本长度一致,也就是 的第 层隐含信息计算最多只能回顾到 的第 层的隐含信息(得包括自身,所有是5-4+1=2,4是固定样本长度)。
PS:固定的意思是不做梯度下降,缓存的意思是用于下一步计算完毕后释放
3.2 相对位置编码
如果要reuse隐含信息(hidden state),要解决一个重要问题:
How can we keep the positional information coherent when we reuse the states?
也就是对于每个样本的绝对位置编码都是一样的,那如何区分 和 (或 和 ,...)呢?
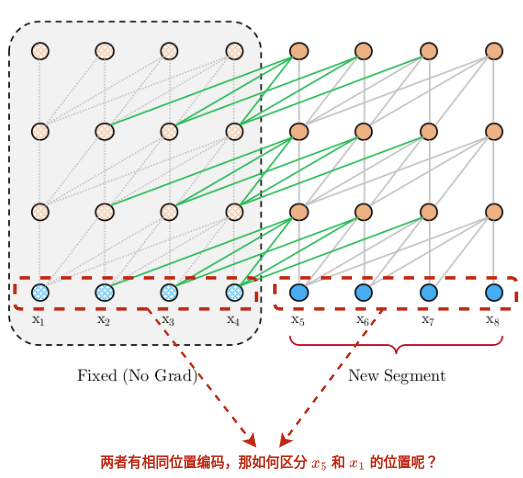
相对位置编码的思想早在2018年就提出,但是本文提供一种新的变体,思想是仅将相对位置信息编码到隐含状态。
3.2.1 回顾标准Transformer的注意力分数矩阵计算
首先回顾一下标准Transformer(2017)的attention分数矩阵计算,假设在一条样本内,表示词嵌入计算,表示位置编码计算,
其中,
因此对于矩阵 的每个元素 由4个子部分加和而来,
3.2.2 相对位置编码
将上面四个子部分替换如下,
具体替换解释:
将绝对位置编码 全部替换为相对位置编码编码 ,这本质上就是以相对距离作为先验信息,决定了 所能关注到的范围。注意:矩阵 是sinusoid(正弦)编码矩阵,且不带可学习参数。
引入可学习参数矩阵 来替代 ,因为 是元素全相等的位置向量,也就意味着所有其他tokens对于第 个token的位置关注程度是一致的,不存在bias。引入可学习参数矩阵 就是为了让模型学到位置编码的bias。同理于 的引入。
将原先 矩阵分成两种权重 和 ,来分别生成基于内容的key向量,和基于位置的key向量。
四个子部分的直观解释:
(a) 基于内容本身的处理
(b) 独立于内容本身的位置偏好信号(bias)的捕捉
(c) 管理全局内容偏好信息(bias)
(d) 编码一个全局的位置偏好信息(bias)
3.3 Transformer-XL
循环机制 + 相对位置编码 = Transformer-XL
对于 层Transformer-XL的计算步骤如下:
其中 定义为词嵌入序列。
顺便提一下 的矩阵运算,普通算法是平方复杂度,论文给出了线性复杂度的简单算法,具体看附件B。