实时数仓不保障时效还玩个毛?
❝我要更快、更快更快!!!
❞
通过本文你可以 get 到:
起因篇-为什么要做数据时效保障 定义篇-数据时效保障包含哪些内容 目标篇-时效性监控以及保障的目标 机制篇-怎么去做数据时效监控以及保障 效果篇-上述机制帮助用户暴露出过什么问题 现状以及展望篇
1.序篇
所有的数据建设都是为了用户更快、更方便、更放心的使用数据。
在用户使用实时数据的过程中,最影响用户体感的指标有两个:
数据质量:实时数据产出的准确性。举个例子:实时数据在某些场景下不能保障端到端 exactly-once,因此实时与离线相同口径的数据会有 diff。而 1% 和 0.01% 的 diff 给用户的体验是完全不同的。 数据时效:实时数据产出的及时性。举个例子:延迟 1min 和 延迟 1ms 的用户体验也是完全不同的。
而本文主要对数据时效保障进行解读。
懒癌患者福利,先说本文结论,通过以下两个指标就已经能监控和判定 90% 数据延迟、乱序问题了。
「数据延迟监控:flink 消费上游的 lag(比如看消费 kafka lag 情况)」 「数据乱序监控:Task/Operator numLateRecordsDropped[1] 可以得到由于乱序导致窗口的丢数情况。」
2.起因篇-为什么要做数据时效保障
要做一个东西时,我们首要分析的就是用户的痛点是什么,用户想要什么。从以下两个方面的分析入手。
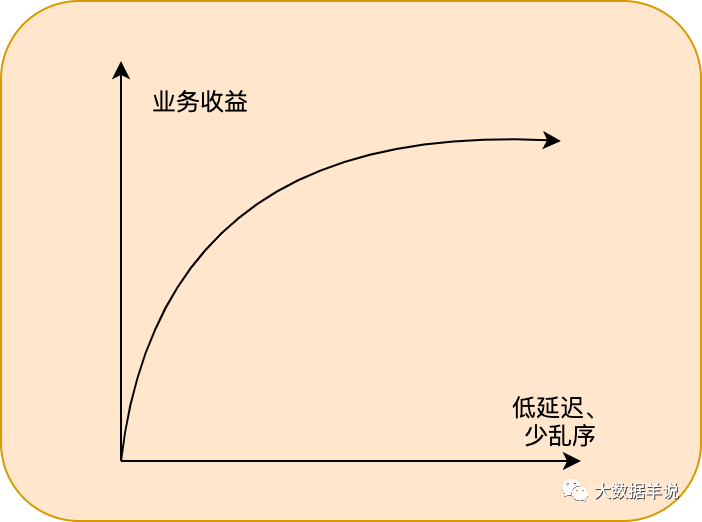
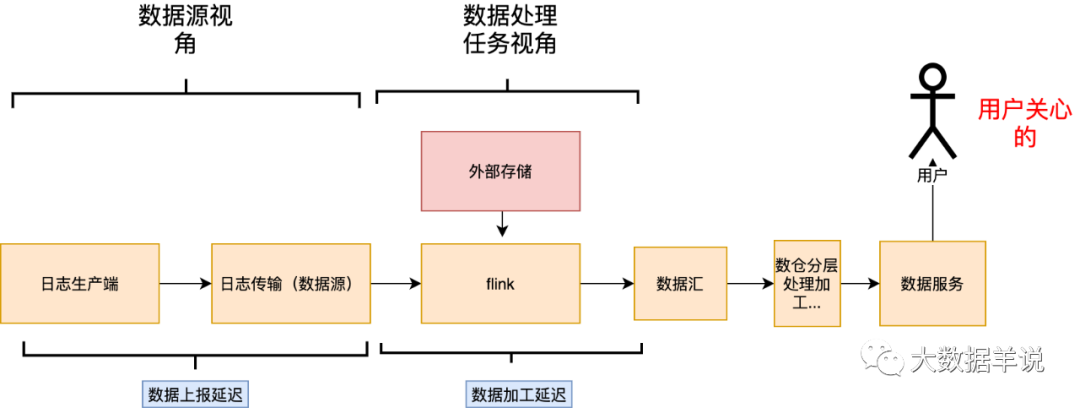
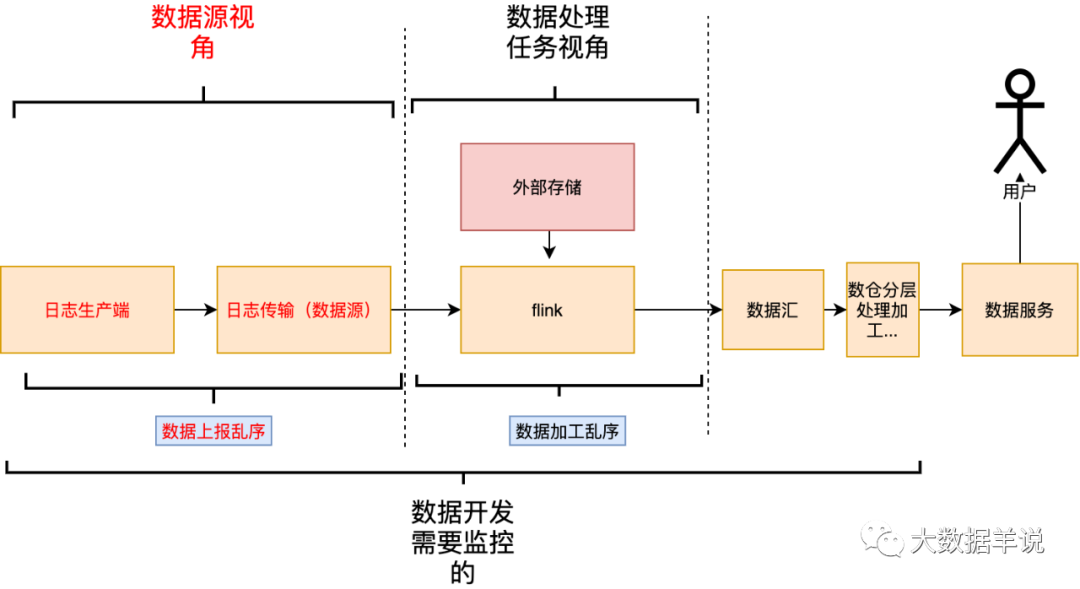
业务侧:首先从正向结果来看,业务侧能拿到第一手准确的实时数据,就能根据准确,快速的数据做出业务策略调整,扩大收益。但是正向结果是我们预期的目标,开发所要做的就是解决达成预期目标过程中的各种不稳定因素,这些不稳定因素就是负向结果。从负向结果看,一旦出现数据产出延迟,数据不准,就有可能让业务错失一个热点,产生巨大损失,两者之间的关系如下图;因此从保障层面出发,这就要求更低的数据延迟、更小的数据乱序(某些对于数据乱序敏感的任务,产出的数据质量强依赖数据乱序情况)
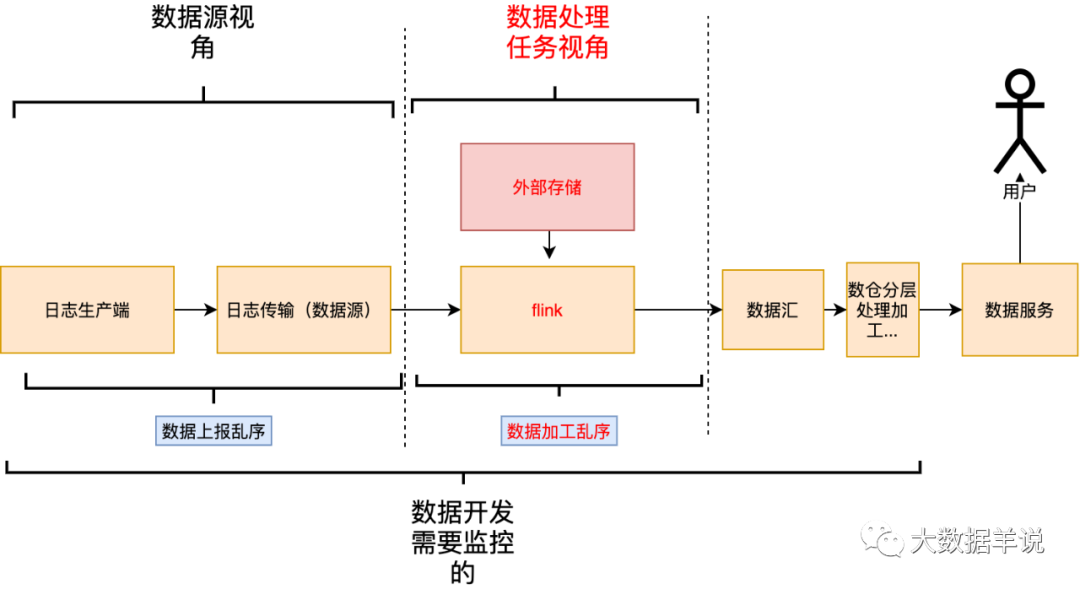
数据加工链路侧:从调研数据源阶段角度出发,DE 需要确定某些原始数据的延迟和乱序情况,确定数据源可用性,从而进行定制化的处理和优化;从保障数据汇结果时效性出发,某些实时数据加工链路是很长的,ods -> dwd -> dws -> ads,当数据产出延迟时,DE 需要快速定位到问题任务进行处理,如下图。数据加工时延越小,数据的乱序情况越小,说明整条处理链路的稳定性也越好,也就有能力提供更高的 SLA 保障;从以上角度出发,也需要我们对整个生产链路的数据延迟、乱序情况有一个全局视角的掌握。
「结论:数据时效保障就是对数据产出延迟、数据乱序的监控报警能力的构建、保障方案规范化的建设。」
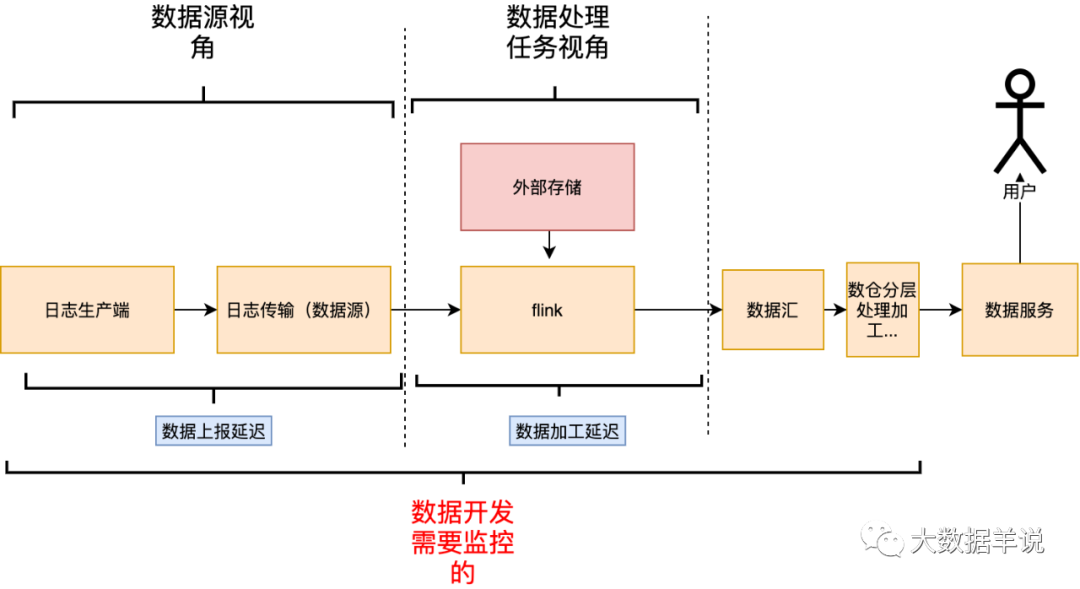
3.定义篇-数据时效保障包含哪些内容
如上节场景分析,实时数据时效保障可分为两部分:
数据时延监控、报警、保障:衡量实时数据产出的延迟情况,设定报警阈值,超过阈值触发报警。并且需要对数据产出延迟有一个全链路的视角,保障数据产出延迟在预期范围内; 数据乱序监控、报警、保障:乱序是实时任务处理中要关注的一个重要指标,如果数据源乱序非常严重的话,会影响窗口类任务产出的实时数据质量,所以我们也需要对齐进行监控以及保障。
❝Notes:
❞
乱序的本质其实就是数据的延迟。乱序是一种特殊的延迟,数据延迟导致的一种结果。
4.目标篇-时效性监控以及保障的目标
探查:了解数据源的延迟、乱序情况。针对数据源的延迟、乱序情况可以针对性优化。也对此能提出合理的 SLA 保障; 监控:针对具体延迟、乱序严重程度设定报警阈值,让开发可以快速感知问题; 定位:根据延迟、乱序报警快速定位数据延迟、乱序导致的质量问题; 恢复:问题解决完成之后,可以根据监控查看到实际的效果;
5.机制篇-怎么去做数据时效监控以及保障
接下来我们「对症(延迟、乱序情况)下药(监控、报警、保障措施)」,先分析在数据生产、传输、加工的过程中哪些环节会导致数据的延迟以及乱序。
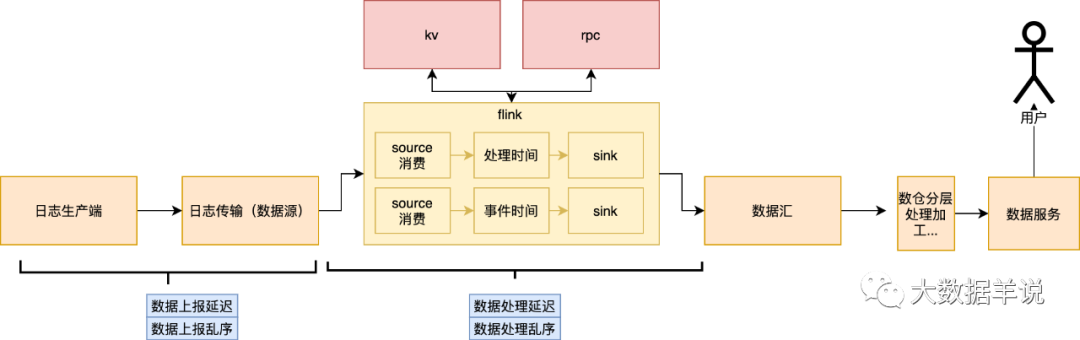
通过分析上述数据生产、传输、加工链路之后,我们可以发现能从「数据源、数据处理任务」两个不同的维度去分析会导致延迟、乱序的原因。
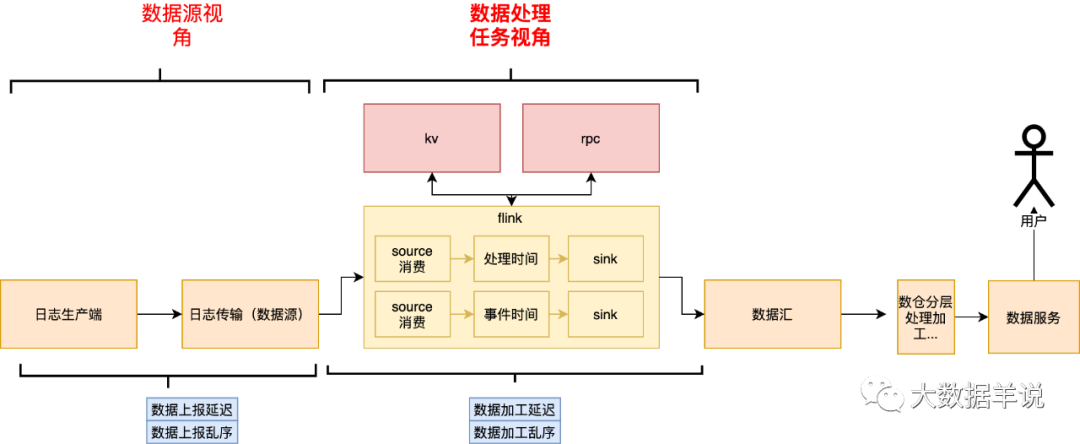
「数据源延迟乱序」:属于数据源本身的属性,和下游消费的任务无关。
「数据加工延迟乱序」:这是和具体的任务绑定。
其对应关系如下。
| 维度 | 数据源视角(与具体任务无关) | 数据处理任务视角(与具体任务绑定) |
|---|---|---|
| 延迟 | 源日志上报的延迟 | 数据加工过程导致的延迟 |
| 乱序 | 源日志上报的乱序 | 数据加工过程中 shuffle 导致的乱序 |
5.1.数据时延监控
5.1.1.整体时延
整体时延可以从以下两个角度出发进行计算。
用户视角:只关心最终产出结果时延 开发视角:需要关心整个链路处理时延
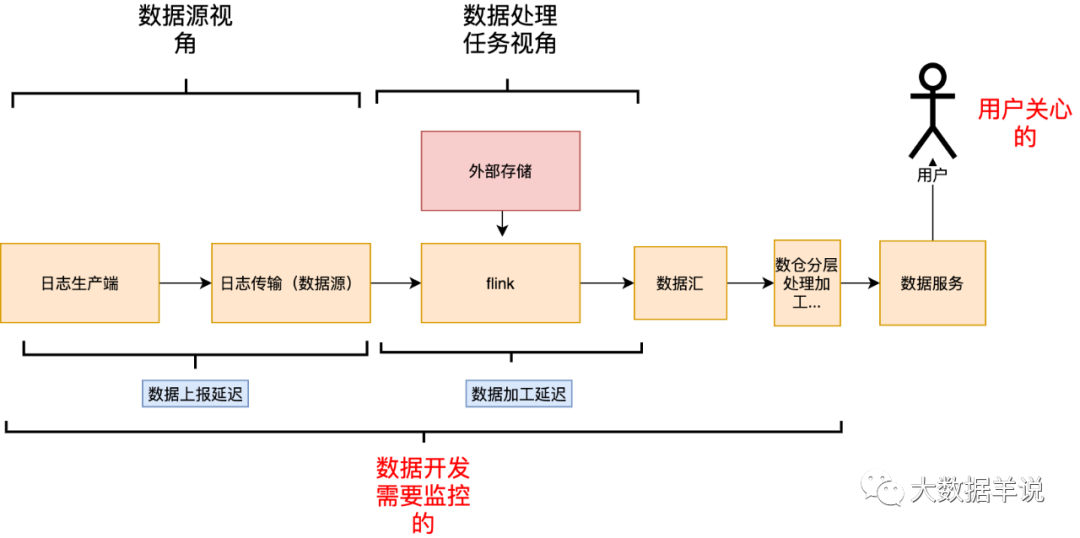
5.1.2.结果时延监控
5.1.2.1.监控指标以及报警机制
从用户体验角度直观的反映出数据的整体时延情况。
「监控方式」:有数据时效监控中心提供延迟监控 sdk。在看板的 web server 侧将数据时延上报到延迟监控 sdk 中。
「监控指标」:计算 web-server-system-current-timestamp - message-event-timestamp 计算 P99 等指标。
「监控方式优点」:能从用户体感角度出发,准确的刻画时延情况。
「监控方式缺点」:对 web server 有埋点侵入性。
「报警机制」:定时(比如 1min/次) check 监控指标的 P99 指标。
「报警阈值」:判断监控指标的 P99 指标是否超过某个阈值(比如 5 min)。
「报警接收人」:报警反馈给任务链路负责人。
5.1.3.链路时延监控
5.1.3.1.数据源时延
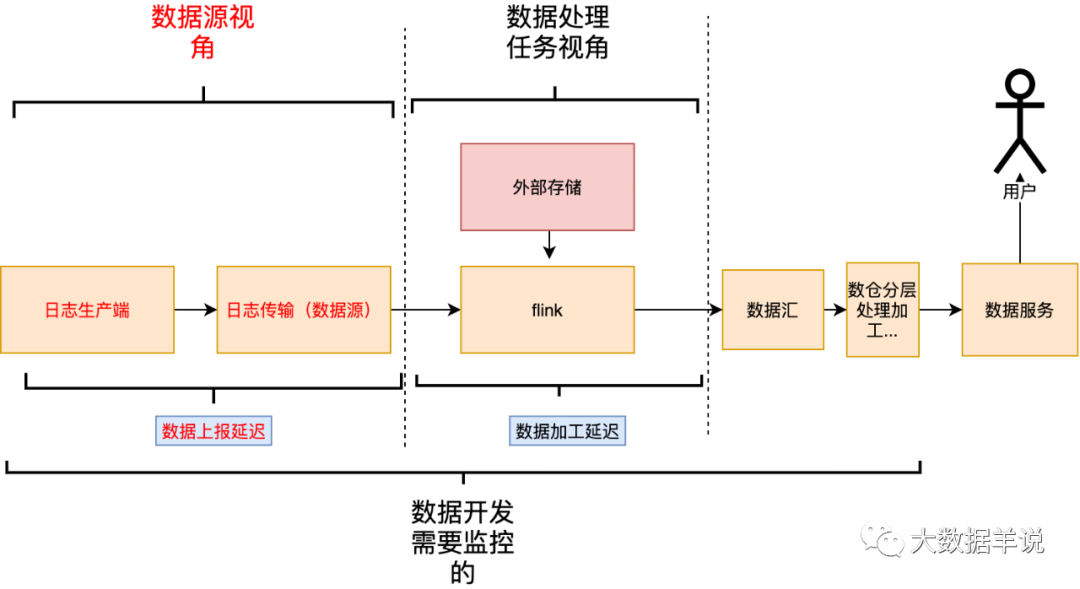
❝这个时延和处理任务无关,单纯从指数据本身的属性,数据本身上报就存在的时延。
❞
举例:从用户发生消费事件一直到日志进入数据源存储引擎中(比如 kafka),这期间存在的时延。
5.1.3.1.1.监控指标以及报警机制
「监控方式」:单独有一个任务消费并处理数据源。需要保障这个任务任何时刻都不能有 lag,才能刻画出一个准确的数据源时延情况。
「监控指标」:使用 system-current-timestamp - message-event-timestamp P99 等指标。
「监控方式优点」:「在数据源角度」能准确的刻画出数据源事件时间时延情况。
「监控方式缺点」:为了监控数据源乱序情况,需要单独启动一个任务耗费资源。不建议这种方式进行,如果要做,可以进行采样。而且会侵入用户代码,需要用户指定时间戳。
「报警机制」:定时(比如 1min/次) check 监控指标的 P99 指标。
「报警阈值」:判断监控指标的 P99 指标是否超过某个阈值(比如 5 min)。
「报警接收人」:报警反馈给任务链路负责人。
上面这种方式是站在数据源视角去精准的衡量出数据延迟情况的,但是很多时候我们只需要在下游任务视角去做这件事会更方便。比如:
「监控方式」:在下游任务处处理数据源时记录数据延迟情况。
「监控指标」:使用任务本地 system-current-timestamp - message-event-timestamp P99 等指标。
「监控方式优点」:节约资源。
「监控方式缺点」:一旦下游任务消费有延迟,我们就不能准确的衡量出数据源的延迟情况了。而且会侵入用户代码,需要用户指定时间戳。
「报警机制」:定时(比如 1min/次) check 监控指标的 P99 指标。
「报警阈值」:判断监控指标的 P99 指标是否超过某个阈值(比如 180s)。
「报警接收人」:报警反馈给任务链路负责人。
❝Notes:这里衍生出一个问题,客户端日志数据一般会有以下两种时间戳:
客户端时间戳:用户在客户端操作时的时间戳 服务端时间戳:客户端日志上报到服务端时,日志 server 打上的本地时间戳 因为客户端的软件版本、网络环境、机型、地区的不同,会导致上报的日志「客户端时间戳」(用户操作时间戳)的准确性参差不齐(你可能会发现有历史、未来的时间戳)。因此事件时间都采用服务端时间戳(日志上报到服务端时,服务端的本地时间戳)来避免这种问题。
当我们采用服务端时间戳时,就基本会发现数据源的时延几乎为 0,因为数据处理链路和日志 server 都是 server 端,因此其之间的数据时延是非常小的,几乎可以忽略不计。
❞
5.1.3.2.数据加工时延
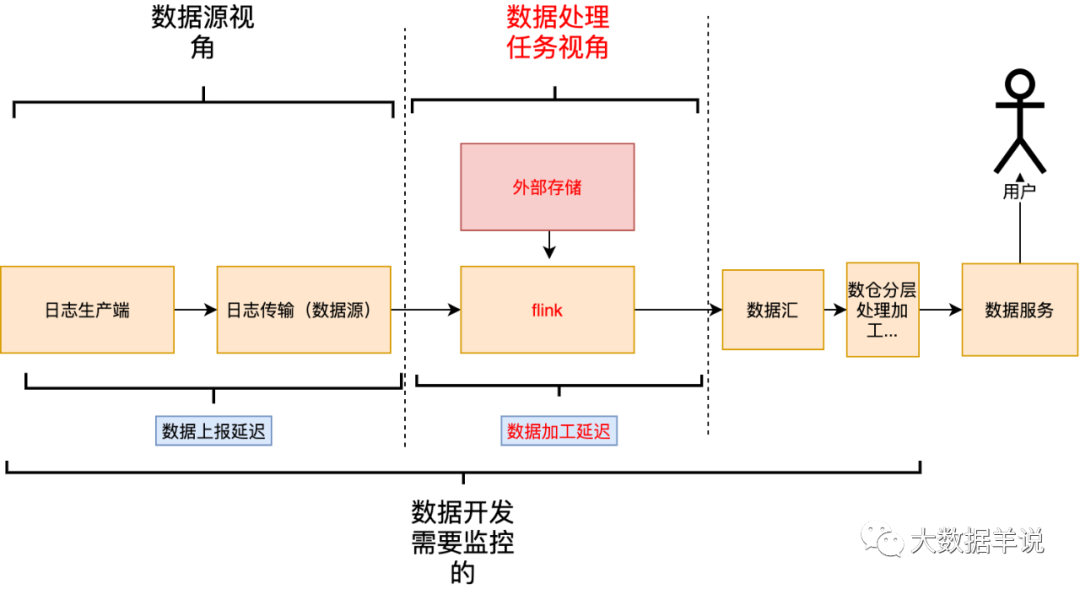
用于衡量实时任务处理链路的时延。定位链路瓶颈问题。
5.1.3.2.1.监控指标以及报警机制
第一个就是 flink 消费数据源的延迟。比如 flink 任务性能不足,产生反压就会有大量 lag。
「监控方式」:在下游任务处处理数据源时记录数据延迟情况。
「监控指标」:使用任务本地 system-current-timestamp - kafka-timestamp P99 等指标。
「监控方式优点」:不侵入用户代码。
「监控方式缺点」:可以衡量出任务消费时延情况。
「报警机制」:定时(比如 1min/次) check 监控指标的 P99 指标。
「报警阈值」:判断监控指标的 P99 指标是否超过某个阈值(常用 180s)。
「报警接收人」:报警反馈给任务链路负责人。
第二部分就是 flink 整个处理过程中的延迟情况。
「监控方式」:flink 本身自带有 latency marker 机制(详见 flink latency marker)。 「监控指标」:flink latency marker 官方文档。 「监控方式优点」:「在下游消费任务的角度」准确的刻画出整个 flink 任务加工时延。 「监控方式缺点」:这个机制会有性能损耗,官方建议只在测试阶段进行使用。这其实已经足够,因为我们在测试阶段就可以基本测试出,flink 任务处理计算的耗时情况。
5.2.数据乱序监控
数据乱序监控主要是用来监控数据源、处理任务过程中操作的乱序对产出数据的影响。
5.2.1.数据源乱序
指数据本身就存在的乱序,比如客户端网络上报存在的乱序,有的用户在偏远网络较差的地区,所以上报可能就会比很多用户延迟很多,这就造成了数据的乱序。
5.2.1.1.监控指标以及报警机制
「监控方式」:单独有一个任务消费并处理数据源。需要保障这个任务任何时刻都不能有 lag,才能刻画出一个准确的数据源时延情况。
「监控指标」:具体衡量乱序的指标类似于 watermark 分配方式。即为每一个 source consumer 维护一个 max(timestamp),记为 max_ts,后续来的数据的时间戳记为 cur_tx,如果 cur_tx > max_ts,则说明没有乱序,设置 max_tx = cur_ts,如果出现 cur_ts < max_ts,则说明这条数据发生了乱序,计算出 abs(cur_ts - max_ts) 为具体乱序时长,最终计算乱序时长的 P99 等值。
「监控方式优点」:「在数据源角度」能准确的刻画出数据源事件时间乱序情况。
「监控方式缺点」:为了监控数据源乱序情况,需要单独启动一个任务耗费资源。不建议这种方式进行,如果要做,可以进行采样。
「报警机制」:定时(比如 1min/次) check 监控指标的 P99 指标。
「报警阈值」:判断监控指标的 P99 指标是否超过某个阈值(常用 180s)。
「报警接收人」:报警反馈给任务负责人。
上面这种方式是站在「数据源视」角去精准的衡量出数据乱序情况的,但是很多时候我们只需要在「下游任务视角」去做这件事会更方便。比如:
「监控方式」:在下游任务处处理数据源时记录数据乱序情况。 「监控指标」:衡量指标同上。
❝Notes:虽然数据源可能有乱序,但是这个乱序经过 flink 的一些策略处理后,乱序对计算数据的影响就会被消除。比如用户设置 watermark 时调大 max-out-of-orderness 以及设置 allow-lateness 的处理之后就会解决。
❞
5.2.2.数据加工乱序
单个任务消费上游数据后,内部做一些 rebalance shuffle 操作导致或者加剧数据乱序的情况。从而会导致一些开窗类的任务出现丢数的情况,导致最后数据计算出现误差。
举例:
DataStream<Model> eventTimeResult = SourceFactory
.getSourceDataStream(xxx)
.uid("source")
.rebalance() // 这里 rebalance 之后会加剧数据乱序,从而可能会导致后续事件时间窗口丢数
.flatMap(xxx)
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Model>(Time.minutes(1L)) {
@Override
public long extractTimestamp(Model model) {
return model.getServerTimestamp();
}
})
.keyBy(KeySelectorFactory.getRemainderKeySelector(xxx))
.timeWindow(Time.seconds(xxx))
.process(xxx)
.uid("process-event-time");
5.2.2.1.监控指标以及报警机制
「监控方式」:我们关心的是乱序最终导致的丢数情况,所以监控丢数条目数即可。
「监控指标」:Task/Operator numLateRecordsDropped[2] 可以得到由于乱序导致窗口的丢数情况。
「监控方式优点」:flink 自带此指标。
「报警机制」:定时(比如 1min/次) check 监控指标的条目数。
「报警阈值」:判断监控指标的条目数是否超过某个阈值(比如 5w 条)。
「报警接收人」:报警反馈给任务负责人。
6.效果篇-上述机制帮助用户暴露出过什么问题
6.1.数据源探查阶段
在数据源探查阶段,通过快速启动数据源消费任务去探查数据源的延迟、乱序程度,确定数据源的可用性。比如发现数据源延迟常年在 5min 以上,那么我们向用户所能保障的数据时延也不会小于 5min。
6.2.暴露延迟、乱序问题
「通过我们的实践测试之后,我们发现报警和问题原因是符合 2-8 定律的,甚至比例达到了 2 - 9。即 90% 的问题都可以由 20% 的报警发现。」
6.2.1.90% 的时延问题是由于 flink 任务性能不足导致
报警项:flink 消费 kafka lag 延迟超过 180s 其他监控项辅助定位:flink 任务 cpu 使用率超过 100%;flink 任务 ygc 每分钟超过 20s
6.2.2.10% 的时延问题是由于数据源延迟导致
报警项:flink 消费 kafka lag 延迟超过 180s;数据源时延超过 180s 其他监控项辅助定位:flink 任务 cpu 使用率正常,每分钟 ygc 时长正常
6.2.3.90% 的乱序问题是由于数据源乱序导致
报警项:flink 任务窗口算子丢数超过 xx 条;数据源乱序 P99 超过 180s(指 99% 的数据乱序情况不超过 180s)
6.2.4.10% 的乱序问题是由于 flink 任务加工乱序导致
报警项:flink 任务窗口算子丢数超过 xx 条 他监控项辅助定位:数据源乱序 P99 处于合理范围;并且代码中有 rebalance 操作之后分配 watermark
6.3.确定延迟、乱序问题恢复情况
当我们修复数据延迟、乱序问题之后,我们也需要观察任务的回复情况。上述监控也可以帮助观察问题的恢复情况。比如:延迟、乱序时长变小就说明用户的修复是有效的。
7.现状以及展望篇
7.1.现状
其实目前很多公司有 「flink 消费 kafka lag 时延」,「Task/Operator numLateRecordsDropped」 就已经足够用了。全方位建设上述整个时延监控的成本还是很高的。
7.2.展望
7.2.1.实时数据、任务血缘 + 时效性全景图
需求:数仓的上下游链路是很长的,如果想更快快速定位整个数据链路中的时效性问题,就需要一个可视化整体链路时延全局图。 基础能力:需要实时数据、任务血缘(目前想要做到这一点,都已经比较难了,很多大厂的机制都不完善,甚至说没有)
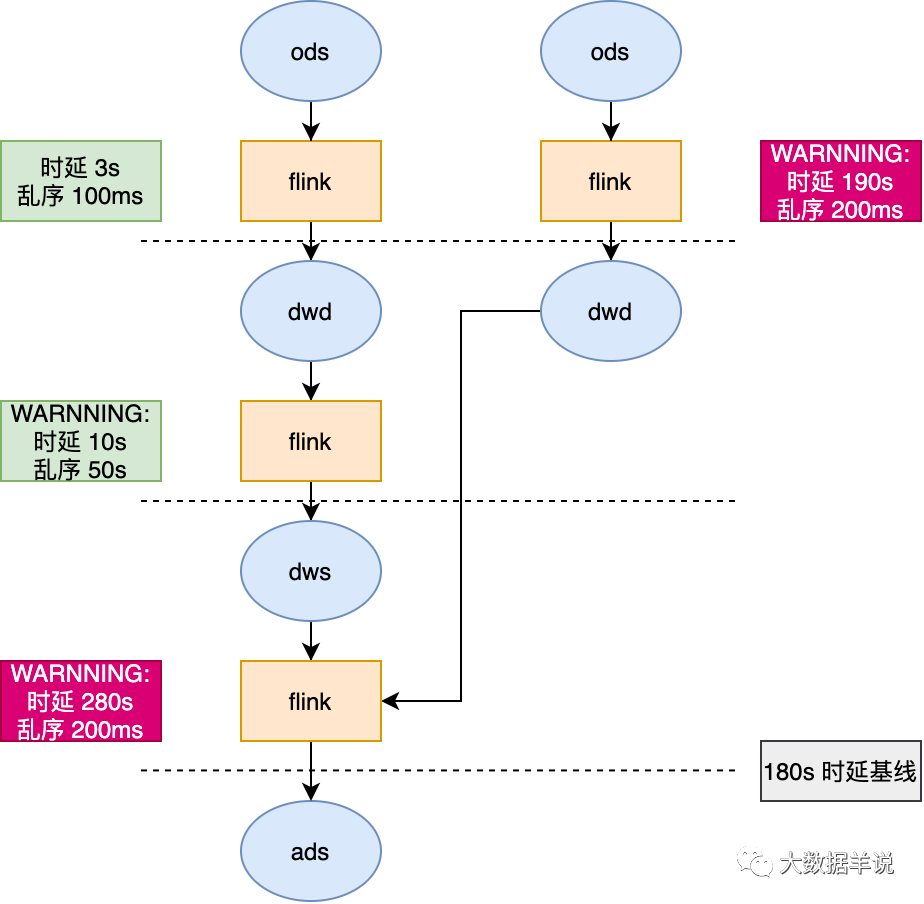
举例:从最终产出的一个 ads 层指标出发,逆推血缘,并展示出时效情况。
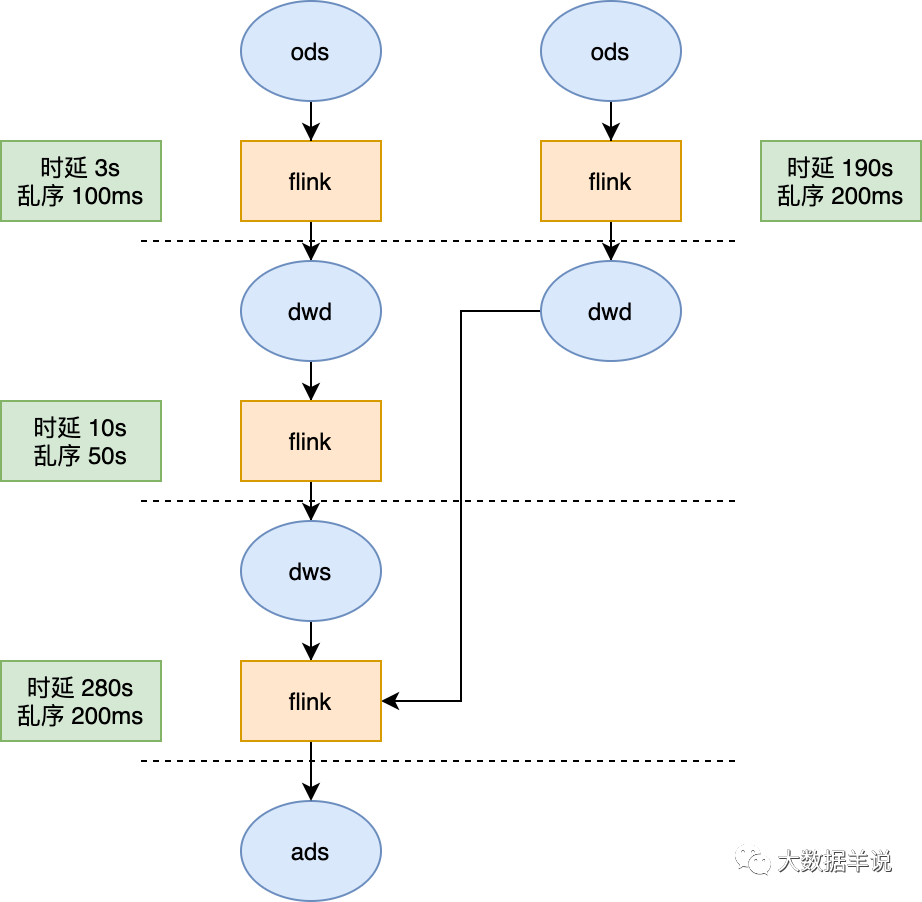
7.2.2.实时时效性基线
7.2.2.1.基线
并且将时延超过阈值的链路使用醒目的颜色标注
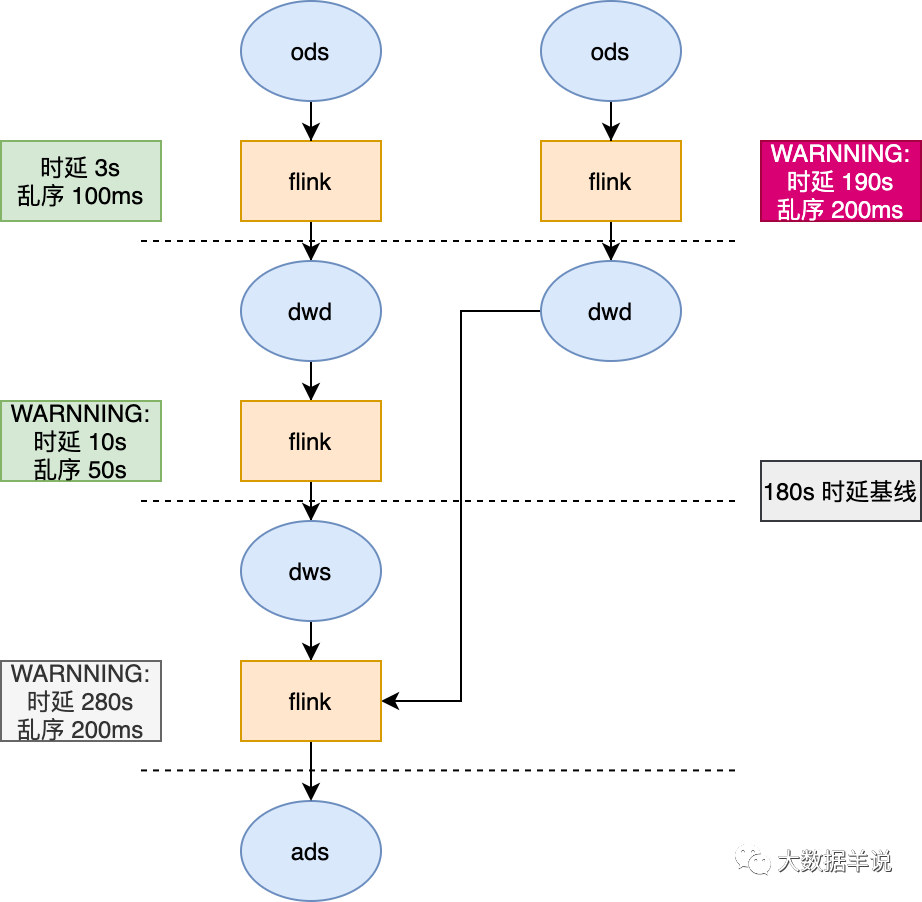
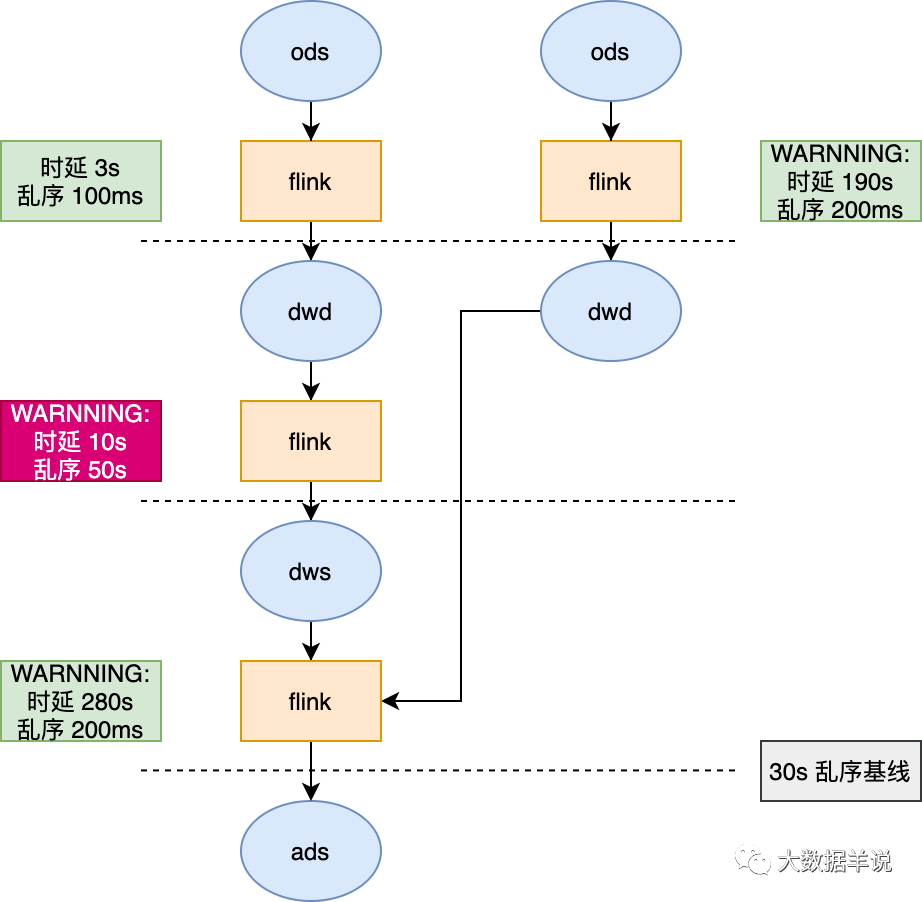
需求:不同的指标有不同的产出时延标准,有了 6.2.1 的基础能力之后,我们就可以根据具体时延要求设置时效性基线。比如设置最终指标产出时延不能超过 180s。那么基线就是 180s。只要整个链路的产出时延超过 180s 就报警。也可以对某一层的加工链路设置基线。
举例:从最终产出的一个 ads 层指标出发,设置基线 180s,那么下图的任务就可以根据基线设定的任务,逆推计算出链路中时延过长的任务,直接报警。