
职业危机?AIGC绘画还有哪些提升空间?

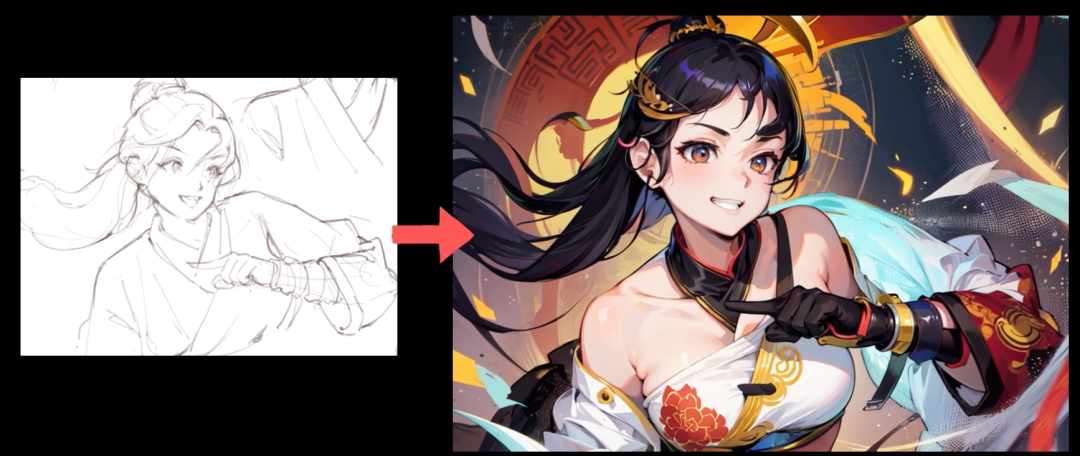




得益于ControlNet线稿功能,我认为类似iPad的Procreate产品非常适合加入AIGC技术,大家可以想象一下,用户画完线稿就能在其他图层生成多种风格的画稿,如果用户觉得不满意可以直接在线稿图层重新修改,例如修改人体的动作甚至表情,这极大提高了生产效率。 如果Stable Diffusion出现了局部微调的概念,准确性和可玩性会进一步提高。怎么理解?众所周知AI绘画最难的就是生成手部,如果我们能对手部进行局部微调,然后将这个新的模型放进整图中,那么手部问题可以被解决。除此之外,如果首饰、武器都可以像零件被微调然后合成到整图中,那么每一个元素的唯一性也能得到保障(这也是AIGC当前存在的问题)。 基于Lora及各种微调技术,我们可以保证图像中角色的脸部保持一致。在未来我们有可能通过1-3张图就能让模型记住这个角色的所有特征,如果我们能将这些角色像零件一样保存下来,配合ControlNet就能一人画漫画了!说不定以后你们也能看到我画的漫画(◔ д◔),我相信那时是漫画界百花齐放的时候~ 基于各种识别检测技术,AIGC可以自行将物体进行替换,部分工作通过AIGC自动绘画会形成主流。 基于2和3,Gif2Gif和Video2Video的质量也会提升一个档次。 个人认为Invoke AI会是Stable Diffusion的下一代交互界面,它比传统的WebUI更像一个图像编辑器,建议大家都尝试一下。当前WebUI每个插件基本都是独立运行,未来各种插件在工作流上的融合以及交互细节会是重点,例如图片拖拽使用、工具列表化等等。 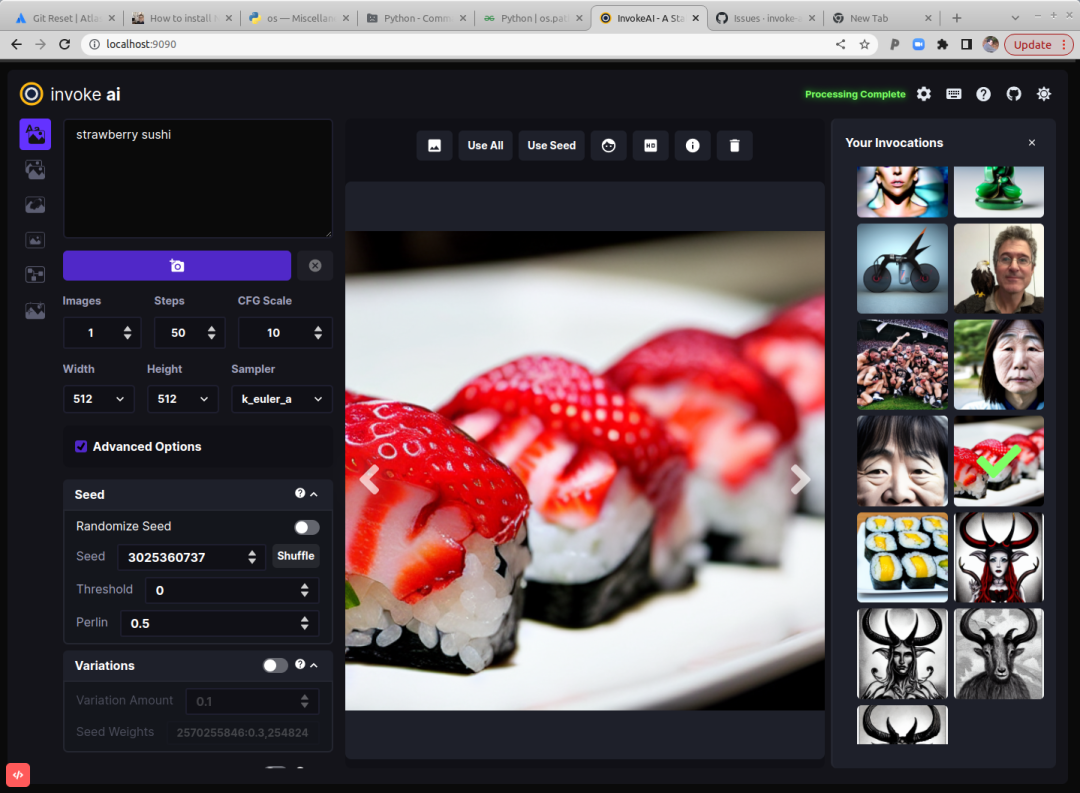
现在的Prompt对设计师来说太不友好了,这里可改进的点有很多。我觉得未来应该有这样的一个Prompt插件,它可以自行调整Prompt的位置及权重并展示相关的Demo图片(少量的Steps),以及自动搜索和索引其他人的Prompt,这能减少各位炼丹的难度。 上文提及的3D编辑器会是Stable Diffusion的下下一代交互界面,因为现在AIGC可以生成3D模型了,这时它的编辑难度会高很多。 Stable Diffusion+NERF神经渲染会让场景生成成为可能。 配合脚本,Storyboard应用会是AIGC for Video的重点应用场景,而场景设计严重依赖故事板,电影制作、基于空间交互的智能家居、XR都需要场景设计,这部分工作AIGC for Video一定比分镜稿和文字更有优势。


#推荐阅读#
评论