
全新Backbone | 模拟CNN创造更具效率的Self-Attention


在本文中提出了一种新的注意力机制,称为
交叉注意力,交叉注意力通过交替应用图像Patch内部的注意力而不是整个图像来捕获局部信息,并在单通道特征图分割出来的图像Patch之间应用注意来捕获全局信息。变压器的计算量都不如标准的自注意,而不是像ViT那样通过整个图像来捕获全局信息。通过内部
Patch和Patch间的交替应用,实现了交叉注意力,以较低的计算成本保持了性能,并为其他视觉任务建立了Cross Attention Transformer(CAT)的层次网络。本文的基础模型在ImageNet-1K上取得了最先进的水平,并提高了在COCO和ADE20K上的其他方法的性能。
1CAT
1.1 CAT概览
该方法旨在将Patch内的注意力和Patch间的注意力结合起来,通过叠加基本块构建分层网络,可以简单地应用于其他视觉任务。如图2(a)所示,首先,将输入图像简化为,(实验中P=4),并参照ViT的Patch处理模式,增加到的通道数。然后,利用多个CAT层进行不同尺度下的特征提取。
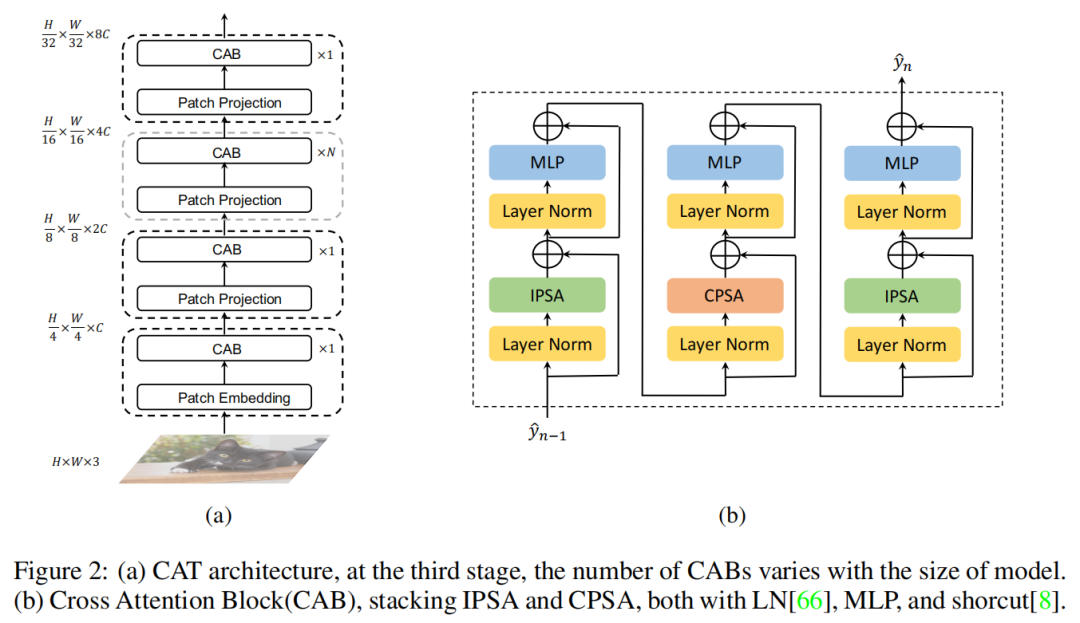
第1阶段:将Patch数为,Patch的shape为进行Patch Embedding,然后输入到几个Cross-Attention Blocks,然后得到第1个阶段输出的特征图的shape为;
第2阶段:将第1个阶段输出的特征图输入到Patch Projection 进行下采样,将2×2×C的pixel block由2×C变为1×1×4C,然后通过线性投影层投影到1×1×2C,让特征图的尺度减半通道加倍,然后输入到几个Cross-Attention Blocks,然后得到第2个阶段输出的特征图的shape为;
第3阶段:将第2个阶段输出的特征图输入到Patch Projection 进行下采样,然后输入到几个Cross-Attention Blocks,然后得到第3个阶段输出的特征图的shape为;
第4阶段:将第3个阶段输出的特征图输入到Patch Projection 进行下采样,然后输入到几个Cross-Attention Blocks,然后得到第4个阶段输出的特征图的shape为;
经过4个阶段后可以得到,4种不同尺度和维度的特征图。与典型的基于CNN的网络一样,可以为其他下游视觉任务提供不同尺度的特征图。
1.2 Inner-Patch Self-Attention Block
在计算机视觉中,每个像素都需要一个特定的通道来表示其不同的语义特征。与NLP中的单词Token类似,理想的方法是将特征映射的每个像素作为Token(例如,ViT,DeiT),但是计算成本太大了。如式1所示,计算复杂度随输入图像的分辨率呈指数级增长。
例如,在传统的RCNN系列的方法中,输入的短边至少为800像素,而YOLO系列也需要超过500像素的图像。大多数语义分割方法也需要512像素边长的图像。在训练前阶段,计算成本至少是224个像素的5倍。
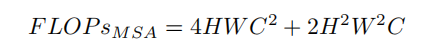
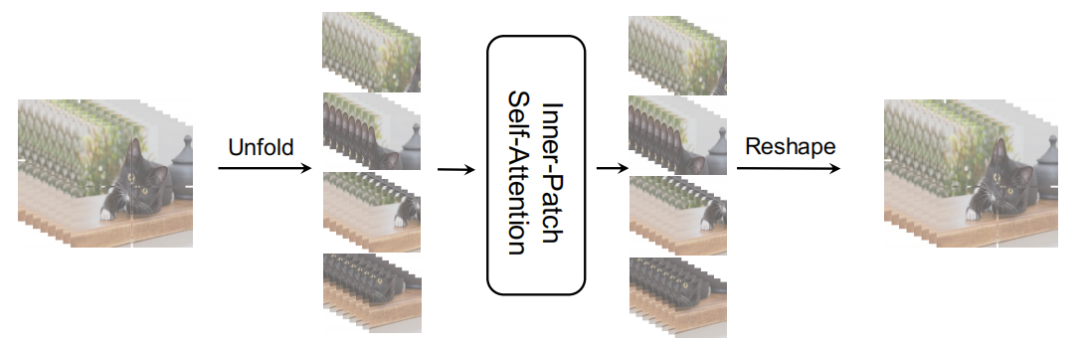
受CNN局部特征提取特征的启发,作者将CNN中的卷积局部性方法引入到Transformer中,对每个Patch进行每像素的自注意力,称为内Inner-Patch Self-Attention(IPSA),如图3(a)所示,把一个Patch视为一个注意力范围,而不是整个图像。同时,Transformer可以根据输入生成不同的注意力图,与固定参数下的CNN相比具有显著优势,与卷积法中的动态参数相似,在Conditional Convolutions中被证明是有益的。TNT也揭示了像素之间的注意力也是至关重要的。而本文的注意力方法显著减少了计算,同时考虑了Patch中像素之间的关系。计算公式如下:
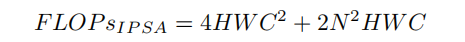
其中,N是IPSA中的Patch size。与标准Transformer中的MSA相比,计算复杂性从与H ×W二次相关变为与H ×W线性相关。
假设H,W=56 C=96 N=7 那么,根据MSA计算FLOPs MSA ≈ 2.0G,如果使用IPSA FLOPs IPSA ≈ 0.15G,这要少得多。
1.3 Cross-Patch Self-Attention Block
添加像素之间的注意力机制只能保证捕捉到一个Patch内像素之间的相互关系,但整个图像的信息交换也是相当重要的。在基于CNN的网络中,堆叠卷积核通常会扩展感受野。为了获得更大的感受野,提出了Dilated/Atrous Convolution,并在实践中获得了不错的效果。
Transformer天生便能够捕获全局信息,但像ViT和Deit这样的工作最终并不是最好的分辨率。
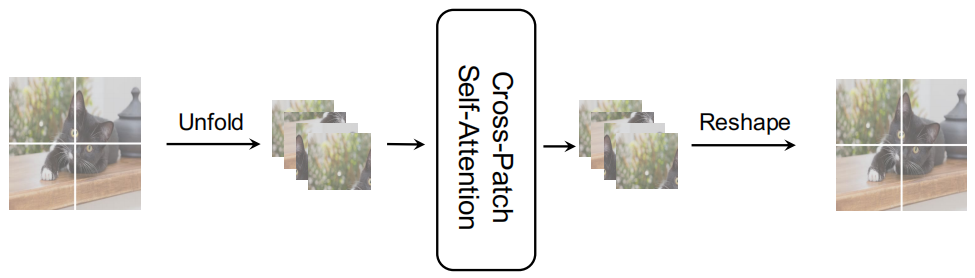
因为每个单通道特征图都具有全局空间信息,因此作者提出了Cross-Patch Self-Attention,将每个通道特征图分离,将每个通道划分为的Patch,并利用Self-Attention在整个特征图中获取全局信息。这类似于在Xception和MobileNet中使用的深度可分离卷积。Cross-Patch Self-Attention的计算方法可以计算如下:
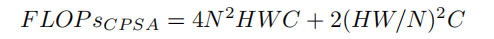
其中N为CPSA中的Patch size,H、W分别表示特征图的高度和宽度。计算成本小于ViT和其他基于全局关注的方法。同时,如图2(b)所示,结合MobileNet设计,叠加IPSA Block和CPSA Block,提取和整合一个特征块中像素之间和一个特征图中Patch之间的特征。与Swin中手动设计的Shift Window相比,不仅难以实现,而且难以捕获全局信息,本文提出的窗口是合理的,更容易理解。FLOPs CPSA约为0.1G,远小于MSA的2.0G。
在初始Transformer论文中提出了Multi-head Self-Attention机制。在NLP中,每个Head可以注意到单词之间不同的语义信息。在计算机视觉中,每个Head可以注意到图像Patch之间不同的语义信息,这与基于CNN的网络中的通道相似。
在CPSA中将Head的数量设置为Patch size,使一个Head的尺寸等于Patch size,这对性能无用处。
Position encoding
在IPSA中采用相对位置编码,而对于在完整的单通道特征图上进行Self-Attention的CPSA,在嵌入在Patch嵌入层中的特征中添加绝对位置编码,可以形成如下:

ab.pos表示绝对位置编码和Patch.Emb。绝对位置编码在CPSA中有助于提高性能。
1.4 Cross Attention based Transformer
如图2(b)所示,Cross Attention Block由2个Inner-Patch Self-Attention Block和1个Cross-Patch Self-Attention Block组成,CAT层由多个CAB组成,网络的每个阶段由不同数量的CAB层和1个Patch Embedding层组成,如图2(a)所示,CAB的Pipeline如下:
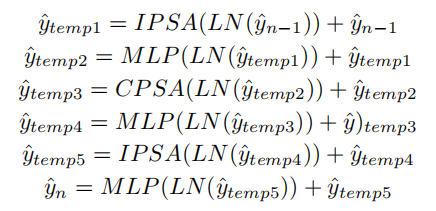
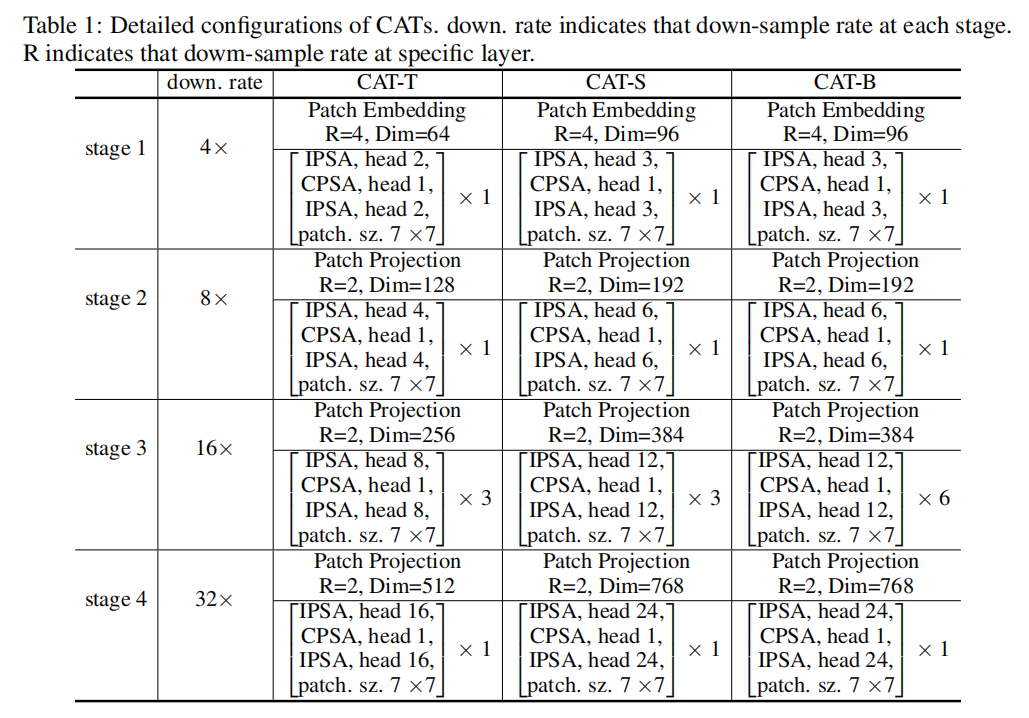
其中,是具有LN的一个Block(例如,IPSA,MLP)的输出。表1详细说明了CAT不同变体的模型配置。
2实验
3.1 消融实验
1、Patch Embedding function

作者比较了卷积和切片方法:
前者进行kernel-size为4,stride为4卷积来将图像的分辨率降低为原图的1/4,后者切片输入从H×W×H×C到H/S×W/S×SC。表5中的结果表明,这两种方法具有相同的性能。为了更好地与其他工作对比,作者选择了卷积方法作为默认配置。
2、Multi-head and shifted window
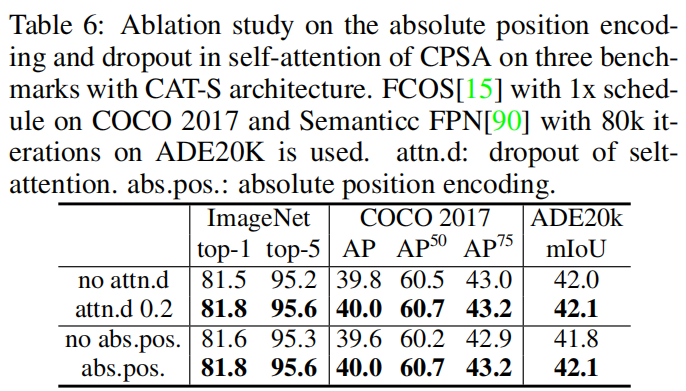
如表5所示。为了研究Swin中的shifted window,作者也进行了实验。结果表明,shifted操作在CAT架构中表现并不好。
3.2 SOTA对比
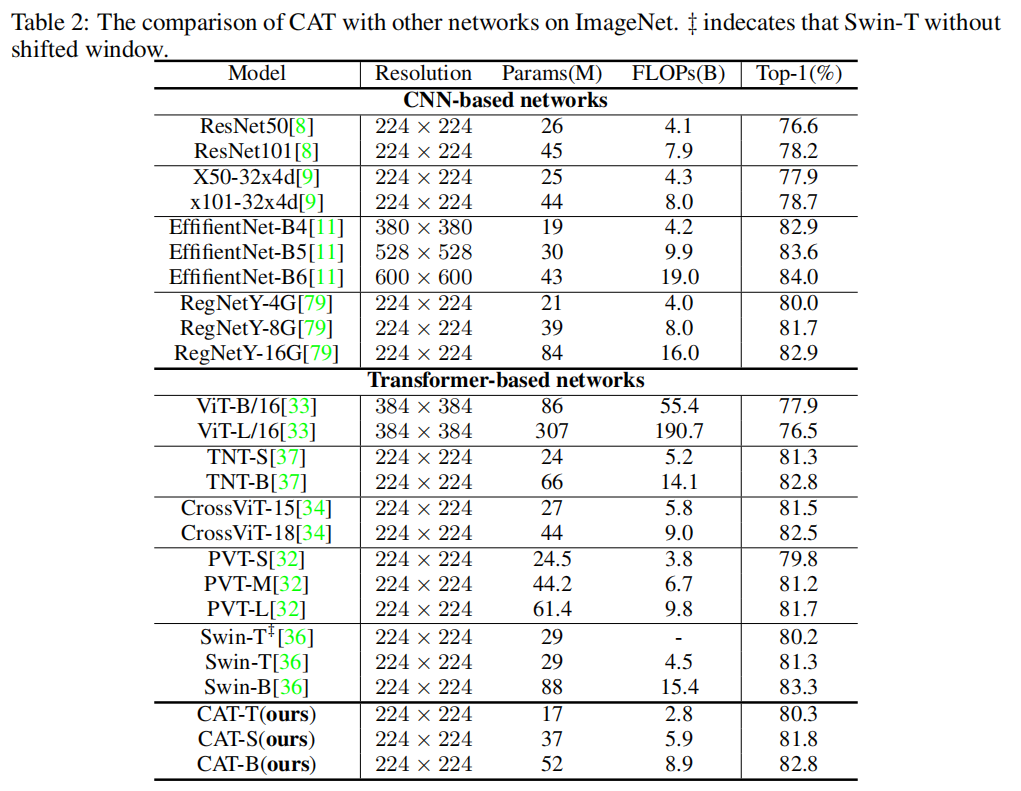
1、图像分类
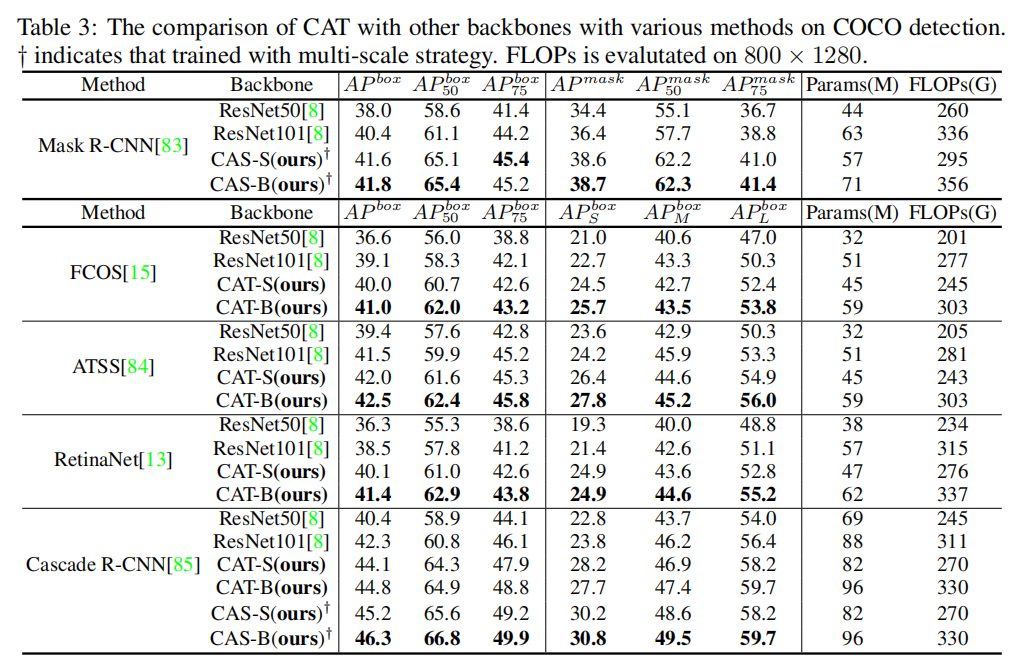
2、目标检测
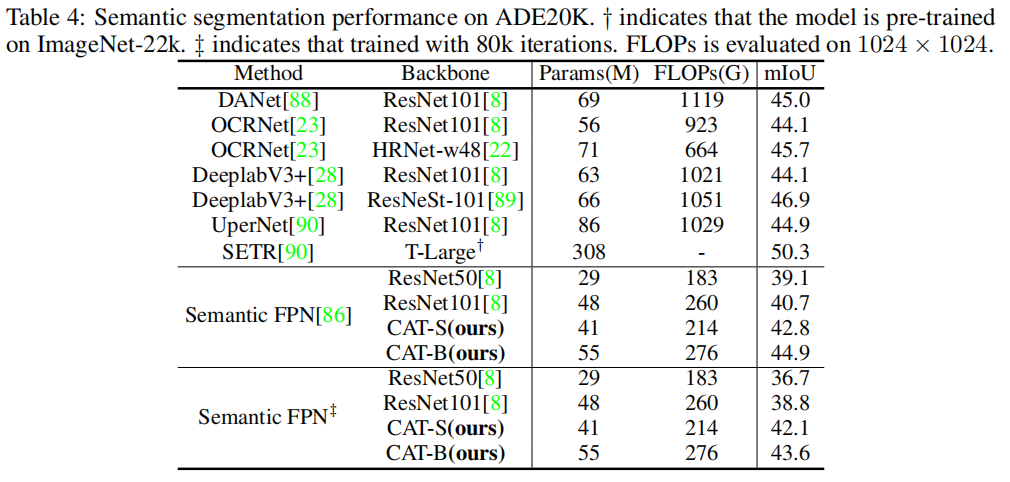
3、语义分割
3参考
[1].CAT: Cross Attention in Vision Transformer
4推荐阅读
Sparse R-CNN升级版 | Dynamic Sparse R-CNN使用ResNet50也能达到47.2AP
NAS-ViT | 超低FLOPs与Params实现50FPS的CPU推理,精度却超越ResNet50!!!
CVPR2022 Oral | CosFace、ArcFace的大统一升级,AdaFace解决低质量图像人脸识
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
