
(附代码)CVPR 2021 | MI-AOD: 少量样本实现高检测性能
摘要:
尽管主动学习在图像识别方面取得了长足的进步,但仍然缺乏一种专门适用于目标检测的示例级的主动学习方法。在本文中,我们提出了多示例主动目标检测(MI-AOD),通过观察示例级的不确定性来选择信息量最大的图像用于检测器的训练。MI-AOD定义了示例不确定性学习模块,该模块利用在已标注集上训练的两个对抗性示例分类器的差异来预测未标注集的示例不确定性。MI-AOD将未标注的图像视为示例包,并将图像中的特征锚视为示例,并通过以多示例学习(MIL)方式对示例重加权的方法来估计图像的不确定性。反复进行示例不确定性的学习和重加权有助于抑制噪声高的示例,来缩小示例不确定性和图像级不确定性之间的差距。实验证明,MI-AOD为示例级的主动学习设置了坚实的基线。在常用的目标检测数据集上,MI-AOD和最新方法相比具有明显的优势,尤其是在已标注集很小的情况下。
论文标题
Multiple Instance Active Learning for Object Detection (用于目标检测的多示例主动学习)
关键词
主动学习(Active Learning),目标检测(Object Detection),多示例学习(Multiple Instance Learning)

源码地址:https://github.com/yuantn/MI-AOD
论文地址:https://arxiv.org/pdf/2104.02324.pdf
太长不看版
首次创造性地为【主动学习+目标检测】任务【量身定制】设计了一种方法! 在 PASCAL VOC 数据集上仅使用【20%】的数据就达到了 100% 数据性能的【93.5%】! 首次在【MS COCO】数据集上应用了主动学习,并取得了最优性能! 思路清晰简单,可推广至【任何类型】的检测模型!
1. 任务与动机(Task & Motivation)
1.1 为什么需要主动学习?
在近些年的数据集中,数据量越来越多,但在某些场景中标记数据的代价会非常大(如医学图像分割、小目标检测等),并且相比之下,获取无标注的图像要容易得多。因此,为了更好的学习特征而达到更高的性能,我们不再考虑一味的增大数据量来实现这个目的,而是通过用更少量有标注的数据,更高效的学习特征。为了选择想要学习的数据,则需要一种周期性的、阶段性的方法进行学习,此即为主动学习(Active Learning)。
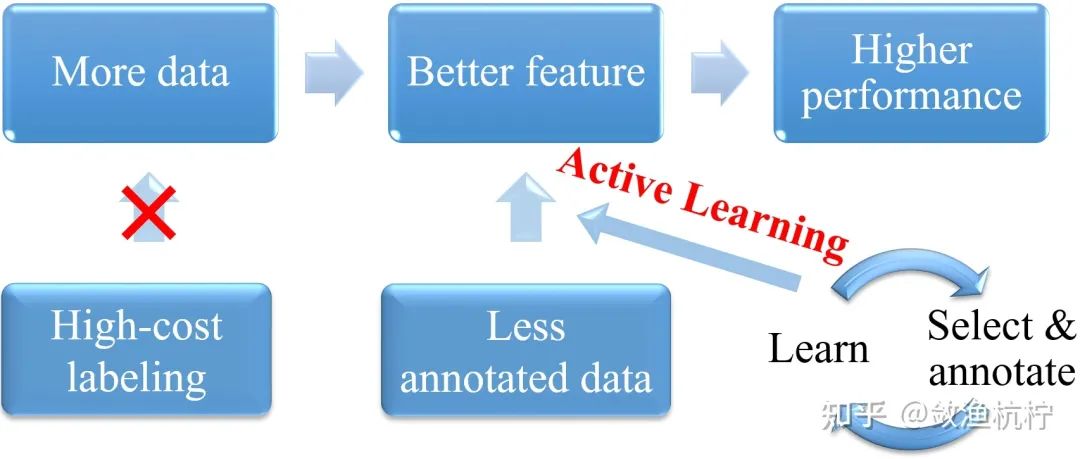
1.2 什么是主动学习?
主动学习背后的关键思想是,如果允许一个机器学习算法选择它想要学习的数据,那么它就可以通过较少的训练样本来达到更好的性能。 尽管在监督较少的情况下的机器学习方法(例如弱监督和半监督)有着迅速的发展,但主动学习仍然是许多实际应用的基础,因为它更简单,性能更高。
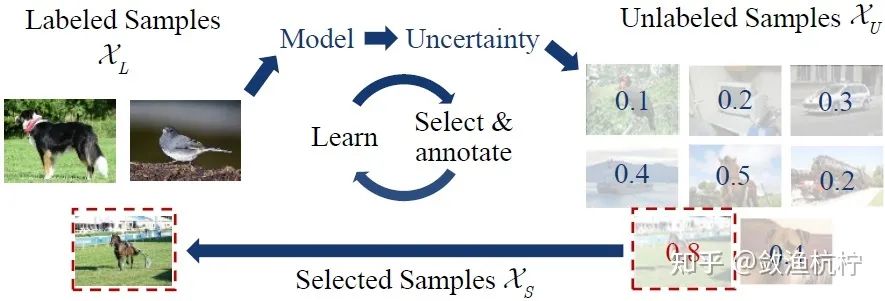
主动学习的过程在上面这幅图中很好地体现了出来。首先,我们从训练集中随机选取一部分样本,作为一个较小的图像集合 (已标注集),带有示例标注 。此外还存在一个较大的图像集合 (未标注集),其中没有任何标注。对于目标检测而言,每张图像的标签均由边界框()和感兴趣物体的类别()组成。
我们通过使用已标注集 初始化检测模型 。基于初始化过的模型 ,主动学习的目的是从 中选择要手动标注的一组图像 ,并将其与 合并形成新的已标注集,即 。所选图像集 应该是信息量最大的,即可以尽可能提高检测性能。
上图中的信息量最大由不确定性(Uncertainty)表示,即将 中的样本输入到现有模型中,如果模型对于各个类别的输出分数更均匀,则该样本不确定性更高。
在更新后的已标注集 的基础上,任务模型被重新训练并更新为 。模型训练和样本选择过程重复几个周期,直到已标注图像的数量达到标注预算。
在上图中我们还注意到,主动学习实际是由两个大的步骤组成,即学习(Learn)与挑选(Select),这就要求我们既要能够尽可能利用已有的样本,最大程度的学习(如采用半监督(Semi-supervised learning)、自监督(Self-supervised learning)等方式学习),又要能够在阶段性学习的基础上,挑选出下一阶段可供学习的样本(如选用不确定性Uncertainty、多样性(Diversity)等标准挑选)。
即,既要会上课,也要会选课。
1.3 主动学习的相关工作
在计算机视觉领域,根据以往的经验,通过将在已标注集上训练的模型推广到未标注集上,各项研究广泛地探索了主动学习,并将其用于图像分类(即主动图像分类)。
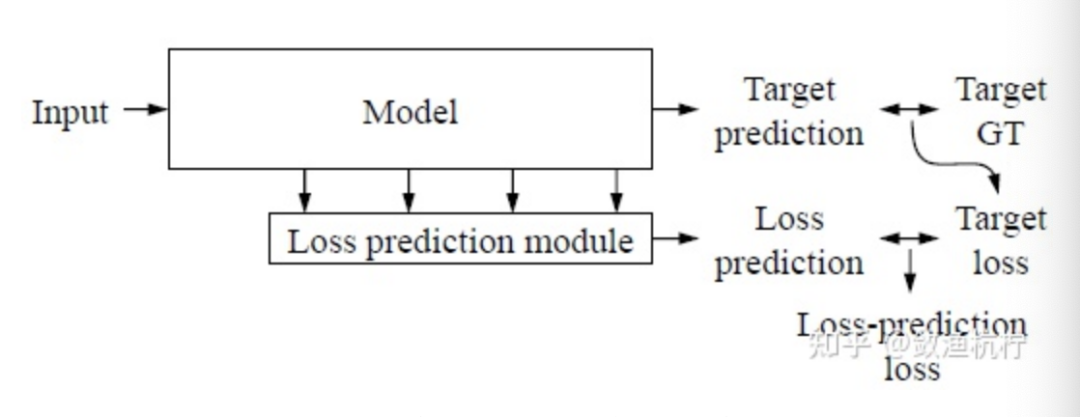
基于不确定性的方法(Uncertainty-based) 定义了各种度量标准,用于选择信息量大的图像,并使经过训练的模型能够迁移到未标注集上[4]。 基于分布的方法(Distribution-based) 旨在估计未标注图像的分布,以选择能使整体多样性更强的样本[7, 1]。 预期模型改变量的方法[3, 6](Expected model change) 是要找出能导致模型参数变化最大或训练损失最大[8]的样本。
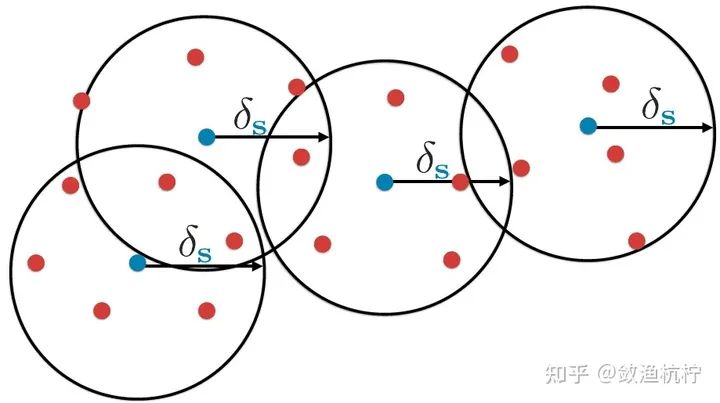
基于不确定性的方法:找模型难以判断的样本,难判断则需要进一步学习
基于分布的方法:找离已标注样本最远的样本,最远则说明目前还没有学到
预期模型改变量的方法:找能使模型改变最大的样本,改变大则更需要学
1.4. 主动目标检测(Active Object Detection)的相关工作与存在的问题
尽管已经取得了重大进展,但仍然缺少一种专门适用于目标检测(Object Detection)(即主动目标检测[8, 9, 2])的示例级主动学习方法,其中一个示例(instance)表示图像中的一个候选框(proposal)。主动目标检测的客观上目的是选择信息量最大的图像进行检测器训练。但是,他们通过简单地将示例或像素的不确定性综合或平均为图像的不确定性来解决该问题。
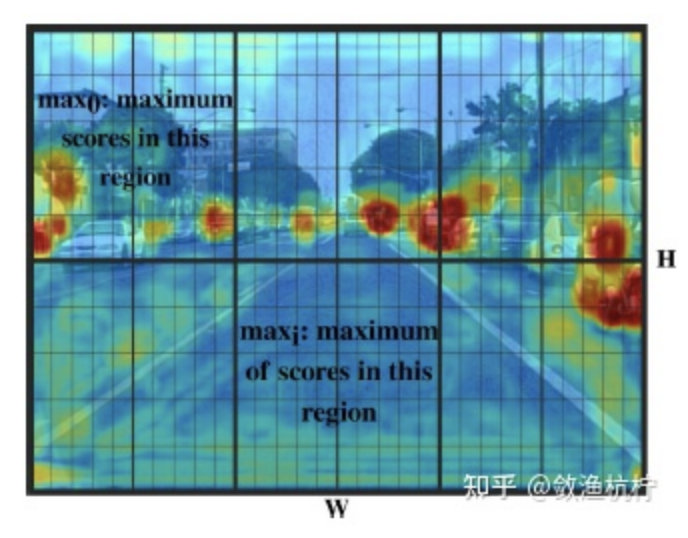
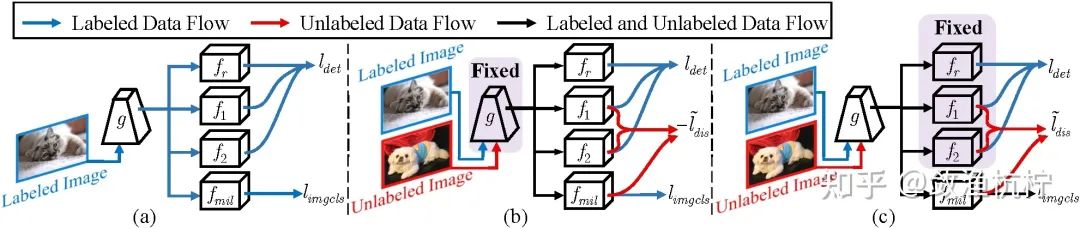
然而,这样忽略了目标检测中负示例产生的较大的不平衡,这导致了背景中存在大量噪声高的示例,并干扰了图像不确定性的学习,如图1(a)所示。
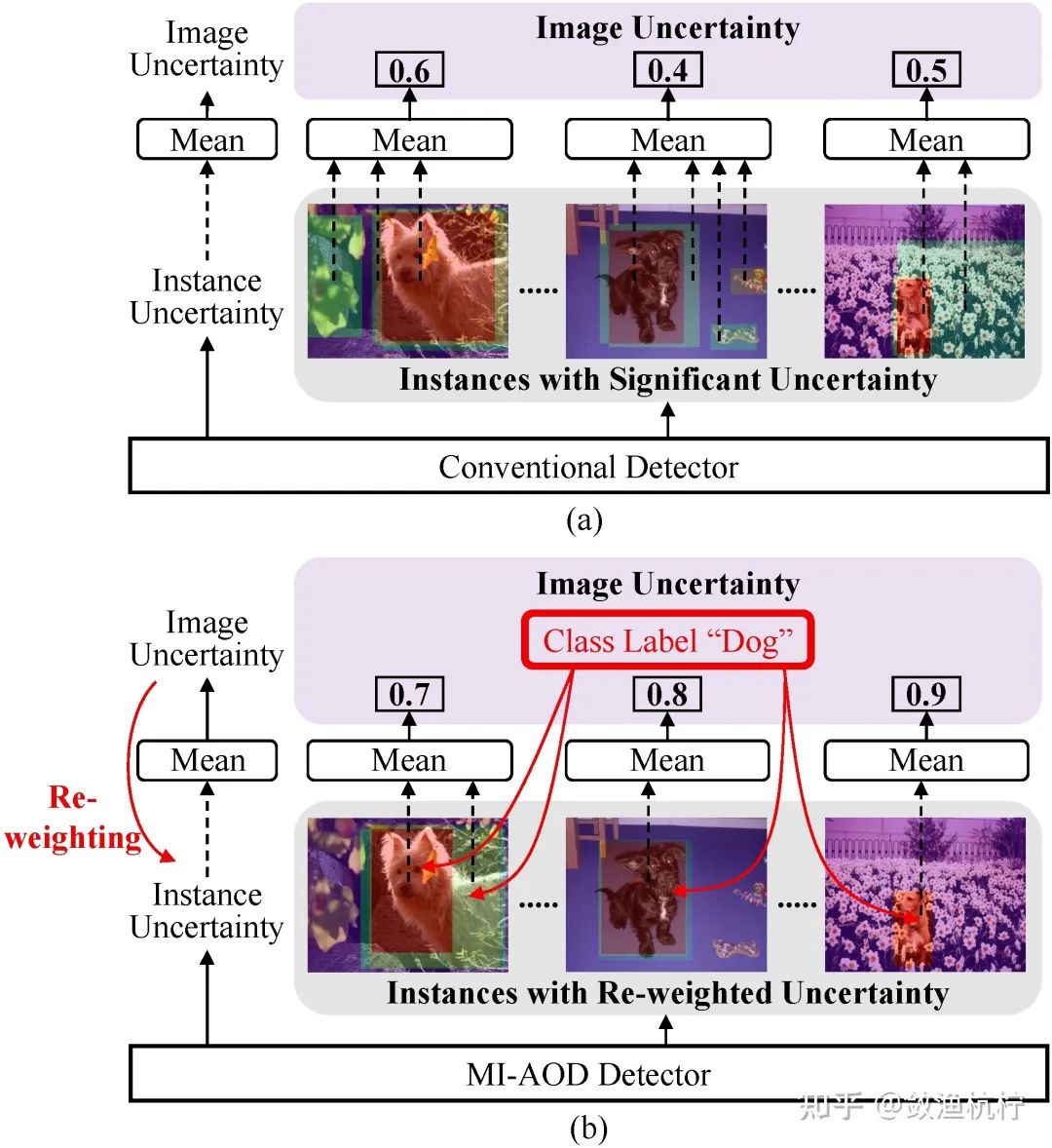
1.5. 多示例主动目标检测(Multiple Instance Active Object Detection, MI-AOD)
在本文中,我们提出了一种多示例主动目标检测方法(MI-AOD),如图1(b)所示。该方法的目的是,用差异学习(Discrepancy Learning) 和多示例学习(MIL) 的方法学习和重加权(re-weight)示例的不确定性,来从未标注集中选择信息量大的图像。
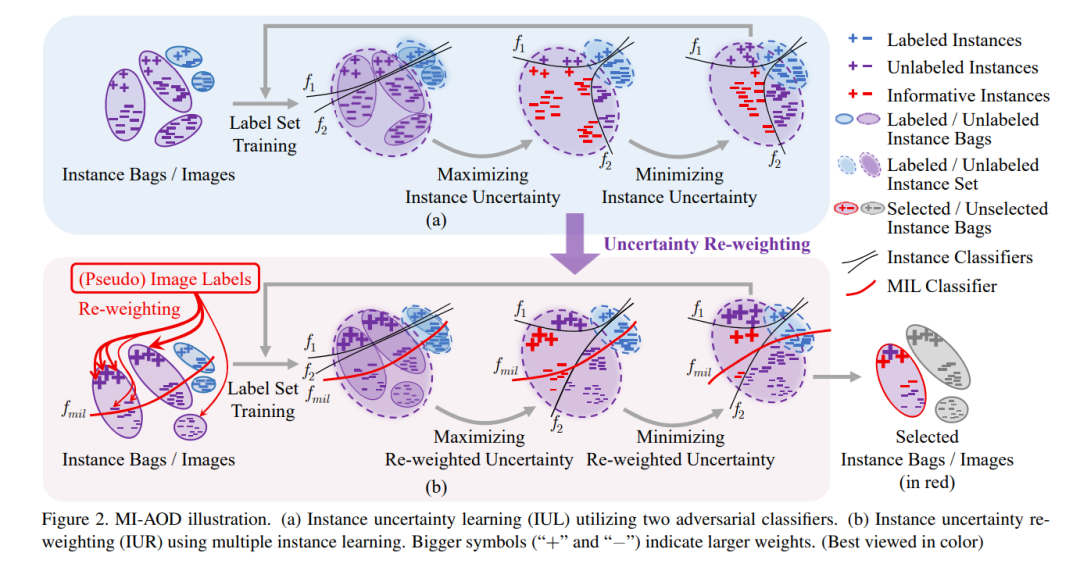
为了学习示例级的不确定性,MI-AOD首先定义了一个示例不确定性学习模块(IUL),该模块利用插入在检测网络(如特征金字塔网络(FPN))顶部的两个对抗性示例分类器来学习未标注示例的不确定性。最大化两个示例分类器的预测差异可预测示例的不确定性,而最小化分类器的差异则可学习特征,从而减少已标注和未标注示例之间的分布偏差。
为了建立示例不确定性和图像不确定性之间的关系,MI-AOD引入了一个多示例学习模块,该模块与示例分类器是并列的。多示例学习将每个未标注的图像视为一个示例包(instance bag),并通过评估各个图像之间的示例外观一致性来进行示例不确定性的重加权(IUR)。
在多示例学习中,根据图像类别标签(或伪标签)定义的分类损失,示例不确定性和图像不确定性被强制一致性地进行学习。优化图像级的分类损失有助于抑制噪声高的示例,同时突出显示真正具有代表性的示例。反复进行示例不确定性的学习和重加权缩小了示例级观察和图像级评估之间的差距,以便选择信息量最大的图像进行检测器训练。
本文的贡献包括:
我们提出了多示例主动目标检测(MI-AOD),建立了一个坚实的基线(baseline)来建模示例不确定性和图像不确定性之间的关系,以进行信息量大的图像选择。 我们设计了示例不确定性学习(IUL)和示例不确定性重加权(IUR)模块,提供了有效的方法来突出显示信息量大的示例,同时在目标检测中过滤出噪声高的示例。 我们将MI-AOD应用于常用数据集上的目标检测,相比于最新方法有着显著优势。
2. 方法(Method)
2.1. 综述(Overview)
考虑到每个图像中存在大量示例(例如,RetinaNet检测器会为每个图像生成几十万个锚(anchor)/示例(instance)),因此主动目标检测中存在两个关键问题:
如何使用在已标注集上训练的检测器来评估未标注示例的不确定性; 如何在滤除高噪声示例的同时精确地估计图像的不确定性。
MI-AOD通过分别引入两个学习模块来解决这两个问题。
对于第一个问题,MI-AOD引入了示例不确定性学习(Instance Uncertainty Learning,IUL),目的是突出未标注集中信息量大的示例,以及对齐已标注集和未标注集的分布,如图2(a)所示。这样做的动机是,大多数主动学习方法仍然只是将在已标注集上训练的模型简单地推广到未标注集上。当两个集合之间存在分布偏差时,这样做是有问题的[5]。
对于第二个问题,MI-AOD将多示例学习引入到已标注集和未标注集中,以通过对示例不确定性的重加权来估计图像的不确定性。这是通过将每个图像当作一个示例包来完成的,同时在图像分类损失的监督下重加权示例的不确定性。优化图像分类损失有利于突出显示属于同一物体类别的真正具有代表性的示例,同时抑制噪声高的示例,如图2(b)所示。
2.2. 示例不确定性学习(Instance Uncertainty Learning,IUL)

训练已标注集。 通过使用RetinaNet作为基线(baseline),我们构造了一个检测器,该检测器具有两个不同的示例分类器(和 )和一个边界框回归器(),如图3(a)所示。我们利用两个示例分类器之间的预测差异来学习未标注集上的示例不确定性。令 表示参数为 的特征提取器。差异分类器的参数为 和 ,回归器的参数为 。 表示所有参数的集合,其中 和 彼此是独立初始化的。
在目标检测中,每个图像 可以由多个示例 表示,这些示例和特征图上的特征锚(feature anchor)相对应。 是图像 中示例的数量。 表示图像中示例的标签。给定已标注集,通过优化以下检测损失来训练检测模型:
其中 是示例分类的焦点损失(Focal loss)函数,而 是边界框回归的平滑L1损失(Smooth L1 loss)函数。 , 和 表示示例的预测(分类和定位)结果。 和 分别表示真实的类别标签和边界框标签。
最大化示例不确定性。 在已标注集可以准确表示未标注集之前,通常在已标注集和未标注集之间会存在分布偏差,尤其在已标注集很小时。信息丰富的示例应位于有偏差的分布区域。
为了找出这些示例,我们设计了两个对抗性示例分类器 和 ,它们在靠近类别边界的示例上更倾向于有更大的预测差异,如图2(a)所示。我们将未标注集上和 的预测差异定义为示例不确定性。
为了找出信息量最大的示例,需要对网络进行微调,并最大化对抗性分类器的预测差异,如图3(b)所示。在最大化过程中, 是固定的,因此已标注和未标注示例的分布都是固定的。和 在未标注集上进行微调,以使所有示例的预测差异最大化。与此同时,还需要保持在已标注集上的检测性能。这可以通过优化以下损失函数来实现:
其中
表示预测差异损失。 是两个分类器对于图像 中第 个示例的示例分类预测,其中 是数据集中物体类别的数量。 是根据实验确定的正则化超参数。如图2(a)所示,对抗性分类器在信息量较大的示例上会有不同的预测结果,这些示例更倾向于具有较大的预测差异和较大的不确定性。
即找到了下一轮要学哪些知识,包括这轮没学好的,太难学的等等
最小化示例不确定性。 在最大化预测差异之后,我们进一步提出了最小化预测差异,以对齐已标注和未标注示例的分布,如图3(c)所示。在此过程中,分类器参数 和 是固定的,而特征提取器的参数 是通过最小化预测差异损失来优化的:
通过最小化预测差异,可以最小化已标注集和未标注集之间的分布偏差,并使二者特征尽可能地对齐。
在每个主动学习周期中,最大化-最小化预测差异过程会重复几次,以便学习示例不确定性,并逐步对齐已标注集和未标注集的示例分布。这实际上定义了一种无监督的学习过程,该过程利用了未标注集的信息(即预测差异)来改善检测模型。
即充分的学好了现有的知识,包括从已标注的样本中和从未标注的样本中。
2.3. 示例不确定性重加权(Instance Uncertainty Re-weighting,IUR)
通过示例不确定性的学习(IUL),我们可以突出显示信息量大的示例。但是,由于每个图像中都有大量(几十万个)示例,因此示例不确定性可能与图像不确定性不一致。某些不确定性高的示例仅仅是检测器的背景噪声或难样本。 因此,我们引入了 多示例学习的步骤,通过滤除噪声高的示例来缩小示例级不确定性和图像级不确定性之间的差距。
多示例学习。 多示例学习将每个图像视为一个示例包,并利用示例分类预测来估计包标签。反过来,它通过最小化图像分类损失来重加权示例的不确定性得分。 这实际上定义了一个 最大期望算法(Expectation-Maximum,EM算法) 来重加权包与包之间的示例不确定性,同时过滤出噪声高的示例。
具体来说,我们在示例分类器旁平行地添加了一个参数为 的多示例学习分类器 ,如图4所示。同一图像中多个示例的图像分类得分 的计算过程为:
其中 是一个 的得分矩阵,而 是 中的元素,表示第 个示例属于类别 的得分。根据公式(5),仅在 属于类别 (公式(5)中的第一项),且该示例的示例分类得分 和 远大于其他示例的得分(公式(5)中的第二项)时,图像分类得分 才会很大。
考虑到来自其他类别/背景的示例会有较小的图像分类得分,图像分类损失 的定义如下所示:
其中 表示图像类别标签,它可以从已标注集中的示例类别标签 中直接获得。对公式(6)的优化使多示例学习分类器能够激活具有较大多示例学习得分()和分类输出()的示例。分类输出大但多示例学习得分较小的示例将被作为背景。图像分类损失首先用在训练已标注集的过程中来获得初始检测器,然后用来对未标注集的示例不确定性进行重加权。
即,MIL帮助做一个学习规划,筛选掉那些没有用的知识(甚至有可能会干扰已有知识)
不确定性重加权。 为了确保示例不确定性与图像不确定性相一致,我们将所有类别的图像分类得分组合为得分矢量,然后将示例不确定性重加权为
其中 。然后,我们将公式(2)更新为
其中 。通过优化公式(8),将会优先估计具有较大图像分类得分示例的差异,而抑制具有较小图像分类得分示例的差异。类似地,公式(4)被更新为
在公式(9)中,在未标注集上用到了图像分类损失,其中的伪图像标签是使用示例分类器的输出估计的,如下所示:
其中 是一个二值化函数。当 时,返回1;否则为0。公式(10)是定义在这样的事实基础上的:示例分类器可以找到真实的示例,但是容易被复杂的背景所混淆。 因此,我们使用最大示例得分来预测图像的伪标签,然后利用多示例学习减少背景干扰。根据公式(5)和公式(6),图像分类损失可确保突出显示的示例能够代表该图像,即最小化图像分类损失,从而最小化示例不确定性和图像不确定性之间的间隔。通过反复优化公式(8)和公式(9),从统计意义上可以突出显示具有相同类别的信息量大的物体示例,而在示例不确定性学习过程中可以抑制背景示例。
这样的辅助规划在一定程度上也筛选掉了下一轮的无用知识
2.4. 信息量大的图像选择(Informative Image Selection)
在每个主动学习周期中,在示例不确定性学习(IUL)和示例不确定性重新加权(IUR)的步骤之后,我们通过观察公式(3)所定义的每个图像中前 高的示例不确定性(其中 是超参数),从未标注集内选择信息量最大的图像。这样做的事实依据是:噪声高的示例已经被抑制掉,且示例不确定性与图像不确定性相一致。 选出的图像将合并到已标注集,用于下一个学习周期。
3. 实验(Experiments)
3.1. 实验设置(Experimental Settings)
数据集。 我们将 PASCAL VOC 2007 和 2012 数据集的 trainval 集用作训练集,它们分别包含 5011 张和 11540张 图像。我们将 VOC 2007 数据集的 test 集用于评估平均精确率(mAP)。
之前在 PASCAL VOC 上的研究都是这么做的[1, 8]
MS COCO 数据集包含 80 个具有挑战性的物体类别,体现在密集物体、有遮挡的小物体等。我们使用 11.7 万张图像的 train 集进行主动学习,使用 0.5 万张图像的 val 集来评估检测性能 AP。
之前还没有主动学习在 MS COCO 上做过,所以我们制定一种规则。
主动学习设置。 我们使用基网为 ResNet-50 的 RetinaNet 神经网络和基网为 VGG-16 的 SSD 神经网络作为基础的检测器。对于 RetinaNet 神经网络,MI-AOD 使用从训练集中随机选择的 5.0% 的图像作为 PASCAL VOC 已标注集的初始化。在每个主动学习周期中,我们从其余未标注集内选择 2.5% 的图像,直到已标注的图像数量达到训练集的 20.0%。
即 5.0%,7.5%,10.0%,12.5%,15.0%,17.5%,20.0%
之前还没有主动学习用 RetinaNet 做过,所以我们制定一种规则。
对于大规模的 MS COCO 数据集,MI-AOD 仅使用训练集中随机选择的 2.0% 的图像作为已标注集的初始化。然后在每个周期中从其余未标注集内选择 2.0% 的图像,直到已标注集达到训练集的 10.0% 为止。
即 2.0%,4.0%,6.0%,8.0%,10.0%
在每个周期中,我们使用为 2 的最小批尺寸(batch size)和 0.001 的学习率(learning rate)训练模型,共训练 26 个时期(epoch)。20 个时期后,学习率降低至 0.0001。动量(momentum)和权重衰减(weight decay)分别设置为 0.9 和 0.0001。
设置为 26 个 epoch 是为了使图 2 中的三步都是整数,即 (3+1+1+3+1+1+3)*2,我们在 mmdetection 的 config 基础上做了一些微小的改动。
对于 SSD,我们遵循 LL4AL[8]和 CDAL[1]的设置,即选择 PASCAL VOC 数据集中的 1000 张图像作为已标注集的初始化,并在每个周期中各选择 1000 张图像。前 240 个时期的学习率是 0.001,后 60 个时期的学习率是 0.0001。最小批尺寸设置为 LL4AL 一文所需的 32。
也正是受限于 batch size,我们只有在 SSD + PASCAL VOC 下才可与 LL4AL 比较。
我们将 MI-AOD 与随机采样,熵采样,Core-set[7],LL4AL[8]和CDAL[1]进行比较。对于熵采样,我们使用平均示例熵作为图像不确定度。我们将所有实验重复 5 次,并使用平均性能。MI-AOD和其他方法共享相同的随机种子和初始化,以实现公平比较。公式(2)、公式(4)、公式(8)和公式(9)中定义的 设置为 0.5,在3.4节中提到的 设置为10000。
我们只与上述这几种方法比较的原因是:
LL4AL[8](CVPR 19)和 CDAL[1](ECCV 20)在进行 Active Object Detection 的实验部分时也是这么做的
SRAAL[9]和 FK-based[5]都是更新的方法(CVPR 2020),但他们都无法用于目标检测实验
Aghdam等人的方法[2]是主动目标检测的方法(ICCV 2019),但只在三个行人数据集上进行了实验(CityPersons,Caltech Ped.,BDD100K),我们的 MI-AOD 方法是通用的主动目标检测方法,应在 PASCAL VOC 或 MS COCO 这种通用目标检测的数据集上进行比较。
3.2. 性能(Performance)
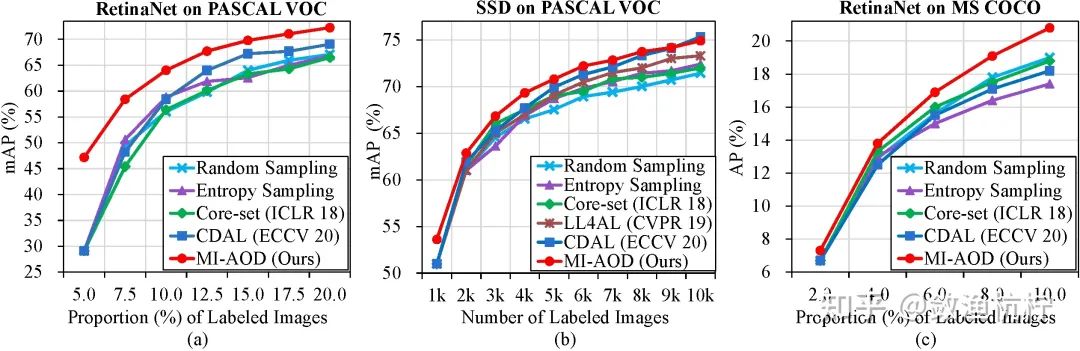
PASCAL VOC 数据集。 在图 5 中,我们报告了 MI-AOD 的性能,并将其与最新方法在TITAN V GPU 上进行了比较。无论使用 RetinaNet 还是 SSD 检测器,MI-AOD 都能以明显的优势胜过最新方法。特别是在使用 5.0%、7.5% 和 10.0% 的样本时,它的性能分别比最新方法高出 18.08、7.78 和 5.19 个百分点。在最后一个周期中,MI-AOD 使用 20.0% 的样本达到了 72.27% 的检测平均精确率_(达到了使用 100% 样本性能的 93.5%!)_,比 CDAL 显著高出 3.20 个百分点。这些提升证实了MI-AOD在选择信息量大的图像时可以精确地学习示例不确定性。
当使用 SSD 检测器时,MI-AOD 在几乎所有周期中都优于最新方法,这证明了 MI-AOD 在目标检测器上的普遍适用性。
MS COCO 数据集。 MS COCO 是具有挑战性的数据集,具有更多类别,更密集的对象和更大的尺度变化,其中 MI-AOD 的性能也优于被比较的方法,如图 5 所示。特别是当使用 2.0%、4.0% 和 10.0% 的已标注图像时,它分别比 Core-set 高出了0.6、0.5 和 2.0 个百分点,比 CDAL 高出了0.6、1.3 和 2.6 个百分点。
3.3. 消融实验 (Ablation Study)
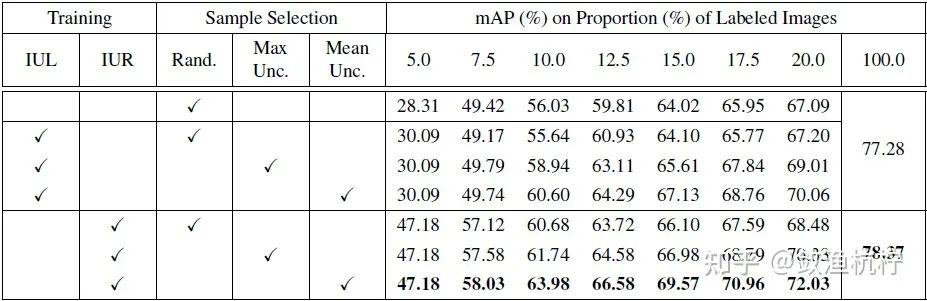
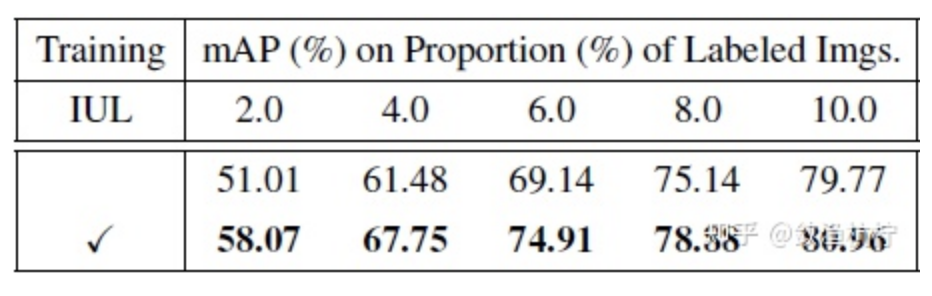
示例不确定性学习(IUL)模块。 如表 1 所示,在使用 IUL 模块的情况下,在最后一个周期中,检测性能提高到了 70.06%,比随机方法高出 2.97 个百分点(从 67.09% 到 70.06%)。在表 2 中,通过在 CIFAR-10 数据集上进行主动学习,IUL 模块还可以显著提高图像分类性能。尤其是在使用 2.0% 的样本时,它可以将分类性能提高 7.06 个百分点(从51.01% 到 58.07%),证明了差异学习模块在不确定性估计方面的有效性。
在 CIFAR-10 数据集上进行实验的目的是,IUL 模块确实有用,尽管在表 1 的检测实验中体现的不太明显。
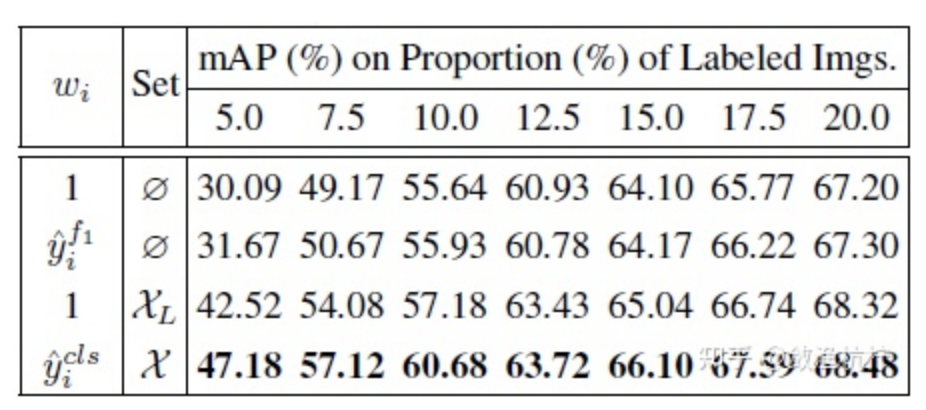
示例不确定性重加权(IUR)模块。 在表 1 中,IUL 模块在早期周期中使用随机的图像选择策略,获得了与随机方法相当的性能。这是因为存在大量噪声高的示例,这些示例导致示例不确定性与图像不确定性不一致。在使用 IUR 模块对示例不确定性重加权之后,早期周期中前三个周期的性能大大提高了 5.04 ~ 17.09 个百分点(表 3 的第 4 行与第 1 行)。在最后一个周期中,性能比IUL模块提高了 1.28 个百分点(从 67.20% 到 68.48%),与随机方法相比提高了 1.39 个百分点(从 67.09% 到 68.48%)。如表 3 所示,图像分类得分是最佳的重加权指标(第 4 行与其他行)。有趣的是,当使用 100.0% 的图像进行训练时,带有 IUR 的检测器比没有 IUR 的检测器性能高出 1.09 个百分点(从 77.28% 到 78.37%)。 这些结果清楚地证明了 IUR 模块可以抑制有干扰的示例,同时突出显示更具代表性的示例,这可以用来选出用于检测器训练的信息大的图像。
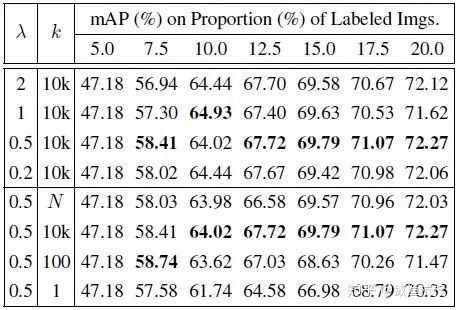
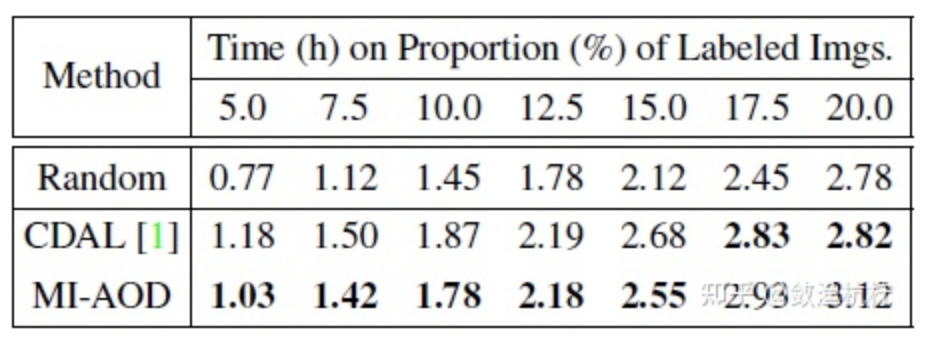
超参数和时间消耗。 表 4 展示了公式(2)、公式(4)、公式(8)、公式(9)中定义的正则化因子 和选择样本时每个图像中的有效示例数量 的影响。当 设置为 0.5 且 设置为 10000 时(因为每个图像中有约 10 万个示例/锚(anchors)),我们得到了最佳性能。表 5 显示,与 CDAL 相比,MI-AOD 在早期几个周期花费的时间更少。
3.4. 模型分析(Model Analysis)

可视化分析。 在图 6 中,我们对学习到和重加权后的示例的不确定性和图像分类分数进行了可视化。热图是通过汇总所有示例的不确定性得分计算出的。仅使用 IUL 模块时,会存在来自背景(第 1 行)或真实正示例周围(第 2 行)的干扰示例,结果往往会遗漏真实正示例(第 3 行)或示例的一部分(第 4 行)。多示例学习可以在抑制背景的同时为感兴趣的示例分配较高的图像分类分数。 结果,IUR 模块可利用图像分类分数对示例重加权,以实现准确的示例不确定性预测。
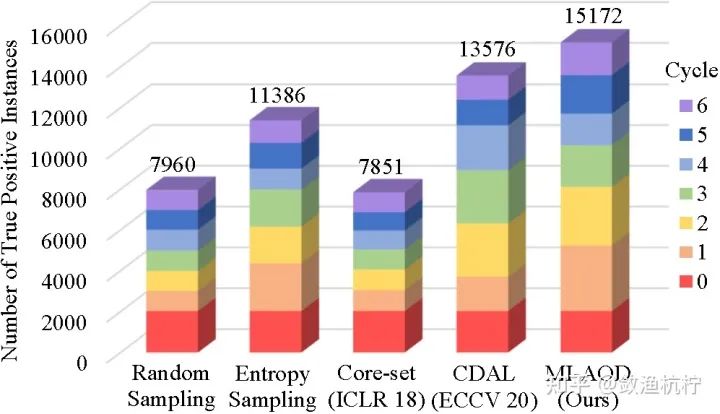
统计分析。 在图 7 中,我们计算了在每个主动学习周期中选择的真实正示例的数量。可以看出,在所有学习周期中,MI-AOD 选用了明显更多的真实正样本。这表明,所提出的 MI-AOD 方法可以在滤除干扰示例的同时更好地激活真实正目标,从而为选择信息量大的图像以供检测器训练提供了便利。
4. 结论(Conclusion)
我们提出了多示例主动目标检测(MI-AOD),通过观察示例不确定性来选择信息量大的图像,以供检测器训练。MI-AOD 包含一个差异学习模块,该模块利用对抗性示例分类器来学习未标注示例的不确定性。MI-AOD 将未标注的图像视为示例包,并通过以多示例学习(MIL)的方式对示例进行重加权来估计图像不确定性。反复的示例不确定性学习和示例不确定性重加权有助于抑制噪声高的实例,以选择用于检测器训练的信息量大图像。大规模数据集上的实验已经验证了 MI-AOD 的优越性,与最新方法形成了鲜明对比。MI-AOD 为主动目标检测设定了坚实的基线。
参考文献(References)
[1] Sharat Agarwal, Himanshu Arora, Saket Anand, and Chetan Arora. Contextual diversity for active learning. ECCV, 2020.
[2] Hamed Habibi Aghdam, Abel Gonzalez-Garcia, Antonio M. L´opez, and Joost van de Weijer. Active learning for deep detection neural networks. ICCV, 2019.
[3] Alexander Freytag, Erik Rodner, and Joachim Denzler. Selecting influential examples: Active learning with expected model output changes. ECCV, 2014.
[4] Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. ICML, 2017.
[5] Denis A. Gudovskiy, Alec Hodgkinson, Takuya Yamaguchi, and Sotaro Tsukizawa. Deep active learning for biased datasets via fisher kernel self-supervision. CVPR, 2020.
[6] Christoph K¨ading, Erik Rodner, Alexander Freytag, and Joachim Denzler. Active and continuous exploration with deep neural networks and expected model output changes. arXiv, 2016.
[7] Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. ICLR, 2018.
[8] Donggeun Yoo and In So Kweon. Learning loss for active learning. CVPR, 2019.
[9] Beichen Zhang, Liang Li, Shijie Yang, ShuhuiWang, Zheng-Jun Zha, and Qingming Huang. State-relabeling adversarial active learning. CVPR, 2020.
双一流高校研究生团队创建 ↓
专注于目标检测原创并分享相关知识 ☞
整理不易,点赞三连!