
第一个 C/C++ 编译器是怎样编写的?
星标/置顶 公众号👇,硬核文章第一时间送达!
不知道你有没有想过,某种编程语言的第一个编译器是怎么来的呢?这不就是“鸡生蛋,蛋生鸡”的问题吗?
先说最后的结论:任何一种语言的第一个编译器肯定是使用其他语言写出来的。

以我们嵌入式开发中经常使用的C语言为例,我们来介绍一下第一个C语言编译器的来源。
还是让我们回顾一下C语言历史:1970年Tomphson和Ritchie在BCPL(一种解释型语言)的基础上开发了B语言,1973年又在B语言的基础上成功开发出了现在的C语言。在C语言被用作系统编程语言之前,Tomphson也用过B语言编写操作系统。
可见,在C语言实现以前,B语言已经可以投入实用了。因此第一个C语言编译器的原型完全可能是用B语言或者混合B语言与PDP汇编语言编写的。但是B语言的效率比较低,如果全部用汇编语言来编写,不仅开发周期长、维护难度大,更可怕的是失去了高级程序设计语言必需的移植性。

所以,早期的C语言编译器就采取了一个取巧的办法:
先用汇编语言编写一个C语言的一个子集的编译器,再通过这个子集去递推完成完整的C语言编译器。
详细的过程如下:
先创造一个只有C语言最基本功能的子集,记作C0语言,C0语言已经足够简单了,可以直接用汇编语言编写出C0的编译器。依靠C0已有的功能,设计比C0复杂,但仍然不完整的C语言的又一个子集C1语言,其中C0属于C1,C1属于C,用C0开发出C1语言的编译器。在C1的基础上设计C语言的又一个子集C2语言,C2语言比C1复杂,但是仍然不是完整的C语言,开发出C2语言的编译器……如此直到CN,CN已经足够强大了,这时候就足够开发出完整的C语言编译器的实现了。
至于这里的N是多少,这取决于你的目标语言(这里是C语言)的复杂程度和程序员的编程能力。简单地说,如果到了某个子集阶段,可以很方便地利用现有功能实现C语言时,那么你就找到N了。
下面的图说明了这个抽象过程:
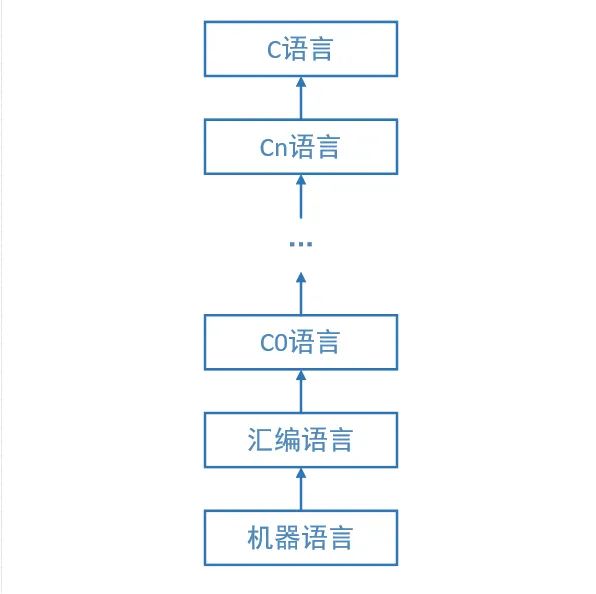
这张图是不是有点熟悉?对了就是在将虚拟机的时候见到过,不过这里是CVM(CLanguageVirtualMachine),每种语言都是在每个虚拟层上可以独立实现编译的,并且除了C语言外,每一层的输出都将作为下一层的输入(最后一层的输出就是应用程序了)。
这和滚雪球是一个道理。用手(汇编语言)把一小把雪结合在一起,一点点地滚下去就形成了一个大雪球,这大概就是所谓的0生1,1生C,C生万物吧?

那么这种大胆的子集简化的方法,是怎么实现的,又有什么理论依据呢?
先介绍一个概念,“自编译”(Self-Compile),也就是对于某些具有明显自举性质的强类型(所谓强类型就是程序中的每个变量必学声明类型后才能使用,比如C语言,相反有些脚本语言则根本没有类型这一说法)编程语言,可以借助它们的一个有限小子集,通过有限次数的递推来实现对它们自身的表述,这样的语言有C、Pascal、Ada等等,至于为什么可以自编译,可以参见清华大学出版社的《编译原理》,书中实现了一个Pascal的子集的编译器。总之,已经有CS科学家证明了,C语言理论上是可以通过上面说的CVM的方法实现完整的编译器的,那么实际上是怎样做到简化的呢?
下面是C99的关键字:
//共37个
auto enum restrict unsigned
break extern return void
case float short volatile
char for signed while
const goto sizeof _Bool
continue if static _Complex
default inline struct _Imaginary
do int switch double long typedef
else register union仔细看看,其中有很多关键字是为了帮助编译器进行优化的,还有一些是用来限定变量、函数的作用域、链接性或者生存周期(函数没有)的,这些在编译器实现的早期根本不必加上,于是可以去掉
auto,restrict,extern,volatile,const,sizeof,static,inline,register,typedef,这样就形成了C的子集,C3语言,C3语言的关键字如下:
//共27个
enum unsigned break return
void case float short char
for signed while goto _Bool
continue if _Complex default
struct _Imaginary do int switch
double long else union再想一想,发现C3中其实有很多类型和类型修饰符是没有必要一次性都加上去的,比如三种整型,只要实现int就行了,因此进一步去掉这些关键词,它们是:
unsigned,float,short,char(charisint),signed,_Bool,_Complex,_Imaginary,long,
这样就形成了我们的C2语言,C2语言关键字如下:
//共18个
enum break return void
case for while goto continue
if default struct do int
switch double else union继续思考,即使是只有18个关键字的C2语言,依然有很多,高级的地方,比如基于基本数据类型的复合数据结构,另外我们的关键字表中是没有写运算符的,在C语言中的复合赋值运算符->运算符等的++,--等过于灵活的表达方式此时也可以完全删除掉,因此可以去掉的关键字有:enum,struct,union,这样我们可以得到C1语言的关键字:
break return void case for while
goto continue if default do int
switch double else
//共15个接近完美了,不过最后一步手笔自然要大一点。这个时候数组和指针也要去掉了,另外C1语言其实仍然有很大的冗杂度,比如控制循环和分支的都有多种表述方法,其实都可简化成一种,具体的来说,循环语句有while循环,do...while循环和for循环,只需要保留while循环就够了;分支语句又有if...{},if...{}...else,if...{}...elseif...,switch,这四种形式,它们都可以通过两个以上的if...{}来实现,因此只需要保留if,...{}就够了。可是再一想,所谓的分支和循环不过是条件跳转语句罢了,函数调用语句也不过是一个压栈和跳转语句罢了,因此只需要goto(未限制的goto)。

因此大胆去掉所有结构化关键字,连函数也没有,得到的C0语言关键字如下:
//共5个
break voidgoto int double这已经是简约的极致了。
只有5个关键字,已经完全可以用汇编语言快速的实现了。通过逆向分析我们还原了第一个C语言编译器的编写过程,也感受到了前辈科学家们的智慧和勤劳!我们都不过是巨人肩膀上的灰尘罢了!
0生1,1生C,C生万物,实在巧妙!
任何一种语言的第一个编译器肯定是使用其他语言写出来的。那就有一个问题了:第一种语言的第一个编译器是怎么来的呢?哈哈!
链接 | https://www.cnblogs.com/Chaobs/p/4510768.html

关注公众号「高效程序员」👇,一起优秀!