
解剖屎山,寻觅黄金之第二弹
大家好,我3y啊。由于去重逻辑重构了几次,好多股东直呼看不懂,于是我今天再安排一波对代码的解析吧。austin支持两种去重的类型:N分钟相同内容达到N次去重和一天内N次相同渠道频次去重。
在最开始,我的第一版实现是这样的:
public void duplication(TaskInfo taskInfo) {
// 配置示例:{"contentDeduplication":{"num":1,"time":300},"frequencyDeduplication":{"num":5}}
JSONObject property = JSON.parseObject(config.getProperty(DEDUPLICATION_RULE_KEY, AustinConstant.APOLLO_DEFAULT_VALUE_JSON_OBJECT));
JSONObject contentDeduplication = property.getJSONObject(CONTENT_DEDUPLICATION);
JSONObject frequencyDeduplication = property.getJSONObject(FREQUENCY_DEDUPLICATION);
// 文案去重
DeduplicationParam contentParams = DeduplicationParam.builder()
.deduplicationTime(contentDeduplication.getLong(TIME))
.countNum(contentDeduplication.getInteger(NUM)).taskInfo(taskInfo)
.anchorState(AnchorState.CONTENT_DEDUPLICATION)
.build();
contentDeduplicationService.deduplication(contentParams);
// 运营总规则去重(一天内用户收到最多同一个渠道的消息次数)
Long seconds = (DateUtil.endOfDay(new Date()).getTime() - DateUtil.current()) / 1000;
DeduplicationParam businessParams = DeduplicationParam.builder()
.deduplicationTime(seconds)
.countNum(frequencyDeduplication.getInteger(NUM)).taskInfo(taskInfo)
.anchorState(AnchorState.RULE_DEDUPLICATION)
.build();
frequencyDeduplicationService.deduplication(businessParams);
}
那时候很简单,基本主体逻辑都写在这个入口上了,应该都能看得懂。后来,群里滴滴哥表示这种代码不行,不能一眼看出来它干了什么。于是怒提了一波pull request重构了一版,入口是这样的:
public void duplication(TaskInfo taskInfo) {
// 配置样例:{"contentDeduplication":{"num":1,"time":300},"frequencyDeduplication":{"num":5}}
String deduplication = config.getProperty(DeduplicationConstants.DEDUPLICATION_RULE_KEY, AustinConstant.APOLLO_DEFAULT_VALUE_JSON_OBJECT);
//去重
DEDUPLICATION_LIST.forEach(
key -> {
DeduplicationParam deduplicationParam = builderFactory.select(key).build(deduplication, key);
if (deduplicationParam != null) {
deduplicationParam.setTaskInfo(taskInfo);
DeduplicationService deduplicationService = findService(key + SERVICE);
deduplicationService.deduplication(deduplicationParam);
}
}
);
}
我猜想他的思路就是把构建去重参数和选择具体的去重服务给封装起来了,在最外层的代码看起来就很简洁了。后来又跟他聊了下,他的设计思路是这样的:考虑到以后会有其他规则的去重就把去重逻辑单独封装起来了,之后用策略模版的设计模式进行了重构,重构后的代码 模版不变,支持各种不同策略的去重,扩展性更高更强更简洁
确实牛逼。
我基于上面的思路微改了下入口,代码最终演变成这样:
public void duplication(TaskInfo taskInfo) {
// 配置样例:{"deduplication_10":{"num":1,"time":300},"deduplication_20":{"num":5}}
String deduplicationConfig = config.getProperty(DEDUPLICATION_RULE_KEY, CommonConstant.EMPTY_JSON_OBJECT);
// 去重
List<Integer> deduplicationList = DeduplicationType.getDeduplicationList();
for (Integer deduplicationType : deduplicationList) {
DeduplicationParam deduplicationParam = deduplicationHolder.selectBuilder(deduplicationType).build(deduplicationConfig, taskInfo);
if (Objects.nonNull(deduplicationParam)) {
deduplicationHolder.selectService(deduplicationType).deduplication(deduplicationParam);
}
}
}
到这,应该大多数人还能跟上吧?在讲具体的代码之前,我们先来简单看看去重功能的代码结构(这会对后面看代码有帮助)
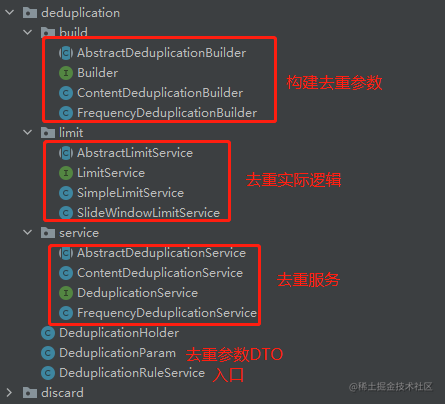
去重的逻辑可以统一抽象为:在X时间段内达到了Y阈值,还记得我曾经说过:「去重」的本质:「业务Key」+「存储」。那么去重实现的步骤可以简单分为(我这边存储就用的Redis):
通过 Key从Redis获取记录判断该 Key在Redis的记录是否符合条件符合条件的则去重,不符合条件的则重新塞进 Redis更新记录
为了方便调整去重的参数,我把X时间段和Y阈值都放到了配置里{"deduplication_10":{"num":1,"time":300},"deduplication_20":{"num":5}}。目前有两种去重的具体实现:
1、5分钟内相同用户如果收到相同的内容,则应该被过滤掉
2、一天内相同的用户如果已经收到某渠道内容5次,则应该被过滤掉
从配置中心拿到配置信息了以后,Builder就是根据这两种类型去构建出DeduplicationParam,就是以下代码:
DeduplicationParam deduplicationParam = deduplicationHolder.selectBuilder(deduplicationType).build(deduplicationConfig, taskInfo);
Builder和DeduplicationService都用了类似的写法(在子类初始化的时候指定类型,在父类统一接收,放到Map里管理)
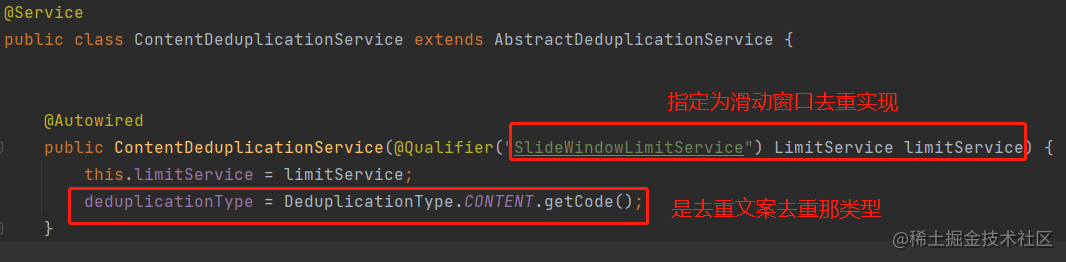
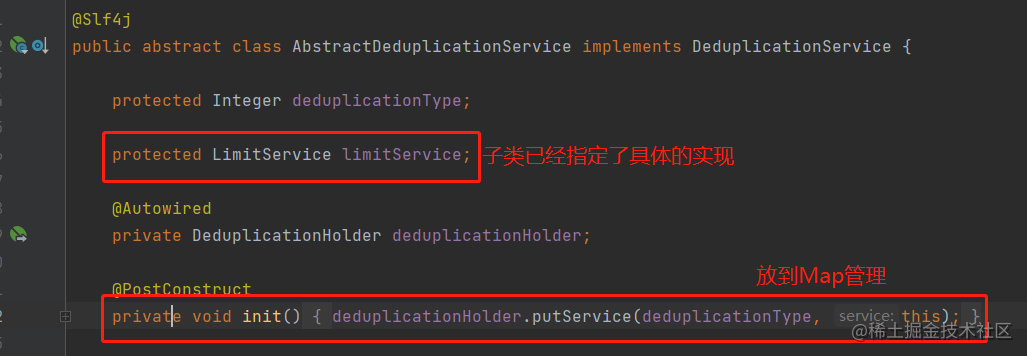
而统一管理着这些服务有个中心的地方,我把这取名为DeduplicationHolder
/**
* @author huskey
* @date 2022/1/18
*/
@Service
public class DeduplicationHolder {
private final Map<Integer, Builder> builderHolder = new HashMap<>(4);
private final Map<Integer, DeduplicationService> serviceHolder = new HashMap<>(4);
public Builder selectBuilder(Integer key) {
return builderHolder.get(key);
}
public DeduplicationService selectService(Integer key) {
return serviceHolder.get(key);
}
public void putBuilder(Integer key, Builder builder) {
builderHolder.put(key, builder);
}
public void putService(Integer key, DeduplicationService service) {
serviceHolder.put(key, service);
}
}
前面提到的业务Key,是在AbstractDeduplicationService的子类下构建的:
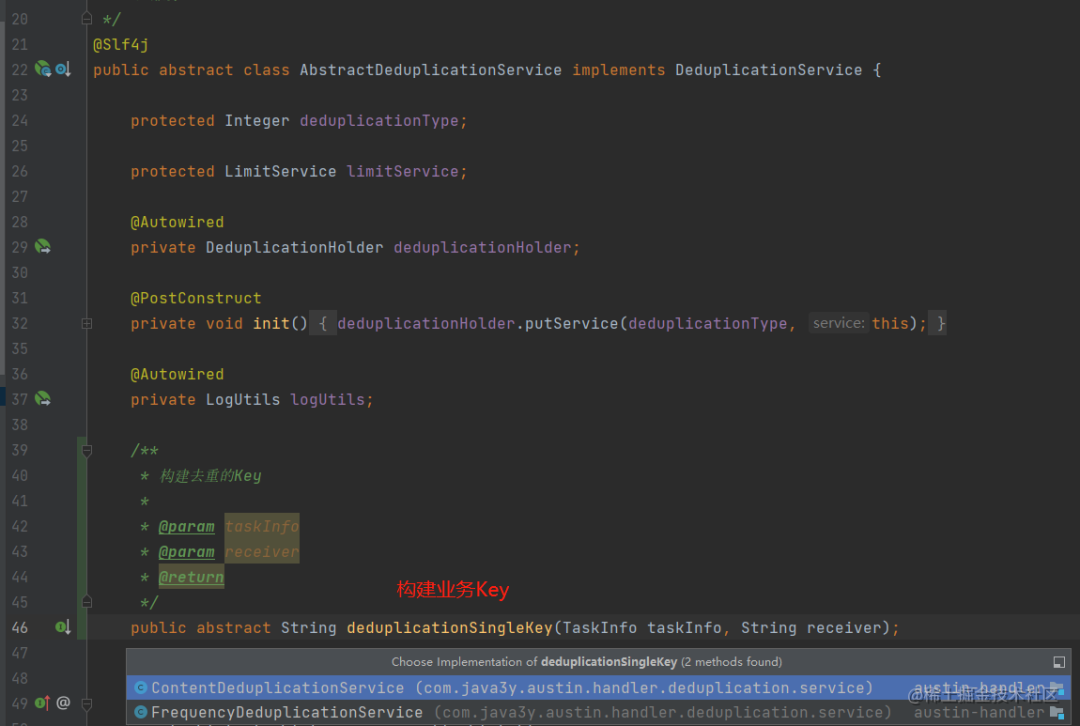
而具体的去重逻辑实现则都在LimitService下,{一天内相同的用户如果已经收到某渠道内容5次}是在SimpleLimitService中处理使用mget和pipelineSetEX就完成了实现。而{5分钟内相同用户如果收到相同的内容}是在SlideWindowLimitService中处理,使用了lua脚本完成了实现。
LimitService的代码都来源于@caolongxiu的pull request,建议大家可以对比commit再学习一番:https://gitee.com/zhongfucheng/austin/pulls/19
1、频次去重采用普通的计数去重方法,限制的是每天发送的条数。
2、内容去重采用的是新开发的基于
redis中zset的滑动窗口去重,可以做到严格控制单位时间内的频次。3、
redis使用lua脚本来保证原子性和减少网络io的损耗4、
redis的key增加前缀做到数据隔离(后期可能有动态更换去重方法的需求)5、把具体限流去重方法从
DeduplicationService抽取出来,DeduplicationService只需设置构造器注入时注入的AbstractLimitService(具体限流去重服务)类型即可动态更换去重的方法 6、使用雪花算法生成zset的唯一value,score使用的是当前的时间戳
针对滑动窗口去重,有会引申出新的问题:limit.lua的逻辑?为什么要移除时间窗口的之前的数据?为什么ARGV[4]参数要唯一?为什么要expire?
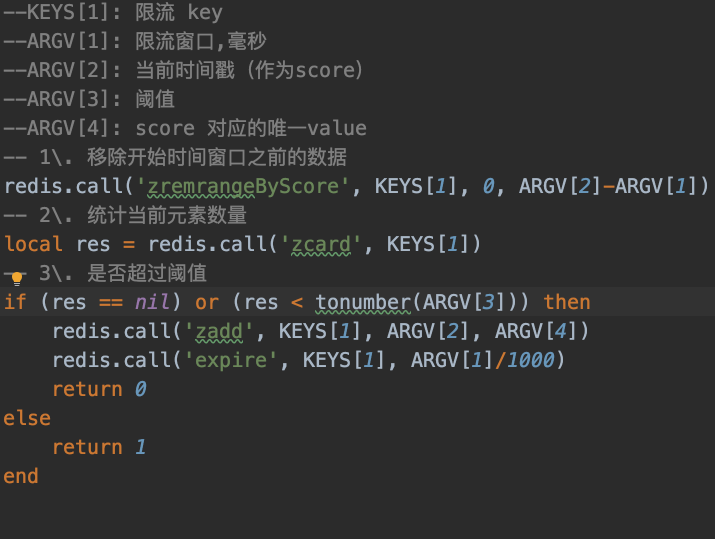
A: 使用滑动窗口可以保证N分钟达到N次进行去重。滑动窗口可以回顾下TCP的,也可以回顾下刷LeetCode时的一些题,那这为什么要移除,就不陌生了。
为什么ARGV[4]要唯一,具体可以看看zadd这条命令,我们只需要保证每次add进窗口内的成员是唯一的,那么就不会触发有更新的操作(我认为这样设计会更加简单些),而唯一Key用雪花算法比较方便。
为什么expire?,如果这个key只被调用一次。那就很有可能在redis内存常驻了,expire能避免这种情况。
推荐项目
最后再叨叨吧,很多人可能会发一段截图,跑来问我为什么要这样写,为什么要以这种方式实现,能不能以这种方式实现。这时候,我更想看到的是:你已经实现了第二种方式了,然后探讨你写的这种方案好不好,现有的代码差在哪里。
毕竟问问题很简单,我又不是客服,总不能没诚意的问题我都得一一回答吧。
如果想学Java项目的,我还是强烈推荐我的开源项目消息推送平台Austin,可以用作毕业设计,可以用作校招,可以看看生产环境是怎么推送消息的。
仓库地址(可点击阅读原文跳转):https://gitee.com/zhongfucheng/austin
我开通了股东服务内容,感兴趣可以点击下方看看,主要针对的是项目哟