GPT-3泄露了我的真实姓名

大数据文摘授权转载自夕小瑶的卖萌屋
作者:天于刀刀
世界上总有这么一群人,他们是高智商科技狂,是新时代技术热点的弄潮儿,更是充满神秘感潜藏在里世界默默注视着时代发展的极客。
而 Hacker News 这一网站致力于提供最新国际威胁情报、黑客动向以及维基解密资讯,让我们得以一窥这个灰色区域。
最近,有关 GPT-3 的消息再次引发 Hacker News 的热议。
而这一次,GPT-3 并不是通过撰写一篇鸡汤文 证明自己在 AIGC 赛道的能力而闻名[1],而是成为了模型数据泄露的“犯罪嫌疑人”。

用户 BoppreH 发帖称,尽管他是一个非常注重保护个人隐私的用户,但是当他向 GPT-3 输入他的网名时,输出结果中意外地包含了他的真实姓名![2]
该用户还提到,之所以能够认定这确实是他的真实姓名,是因为他的真名非常罕见,同时也从来没有主动在网络上以任何方式将他的网名和真名联系在一起。
有的黑客朋友提出,帖主疏忽了一种可能性,其实能够通过 Google 搜索他用户名的方式,能追踪到他同昵称的 Github 中的某一个项目 repo 中 licence 的签名,这恰巧也就是他的真名。(好复杂)
但是这样的信息检索和关联能力已经远远地超出普通搜索引擎和机器人爬虫的能力范围,莫非 LM 语言大模型就是下一代智能搜索的雏形?如果 GPT-3 真的拥有着如此的信息关联能力,这简直和童话故事中的魔镜一样,堪称魔法智能了。
毫无疑问的, GPT-3 训练数据的构建方式非常值得引起大家思考,同时也让不少人再一次对大模型“黑箱推理导致的信息泄露”产生了激烈的讨论。
黑客社区的讨论主要聚焦在于隐私保护问题上,通过引用大量法律(主要是诽谤法相关法规)以及各个 Lincence 开源协议,最终明确了两个概念:
“被遗忘权”( right to be forgotten )和“铭记权”( right to remember )。
If I had found my personal information on Google search results, or Facebook, I could ask the information to be removed, but GPT-3 seems to have no such support. [2]
这两个概念均来自或扩展于欧洲联盟《通用数据保护条例》( General Data Protection Regulation,简称 GDPR ),前身是欧盟在1995年制定的《计算机数据保护法》。其中重点规定了:
对违法企业的罚金最高可达2000万欧元(约合1.5亿元人民币)或者其全球营业额的4%,以高者为准。
网站经营者必须事先向客户说明会自动记录客户的搜索和购物记录,并获得用户的同意,否则按“未告知记录用户行为”作违法处理。
企业不能再使用模糊、难以理解的语言,或冗长的隐私政策来从用户处获取数据使用许可。
明文规定了用户的“被遗忘权”,即用户个人可以要求责任方删除关于自己的数据记录。
举个例子,今年著名的“女子取快递被造谣出轨”案件中,受害人完全能够基于“被遗忘权”,要求各大搜索引擎和网站下架相关搜查结果和词条,否则企业将面临高额罚款。
因此“被遗忘权”主要是针对公司组织的规定。
而“铭记权”则与之相对应,来源于古早时期互联网开放透明的基石思想,中心理念是让互联网见证一切,不容历史被篡改。
维基百科就是一个最典型的代表,每一个人都有权利去记录去修改一些不精准的词条,并且最终的结果一定是非常客观公正的。
例如在之前的例子中,行使“铭记权”的个体需要公允地记录“女子取快递被造谣出轨”案件的前因后果,不能断章取义。
因此“铭记权”是每一个网络公民都应该自觉遵守的道德规范,这是一个针对个人的限制。
随着国内信息技术的不断发展,我国法律也逐渐填补减少了这一块灰色地带的判定。
我们可以欣慰地看到法院最终在“女子取快递被造谣出轨”案中判处被告方诽谤罪,且有期徒刑1年,缓刑2年,因此我们也有足够的理由相信随着社会的进步,相关合规性文件会越来越规范。

如果说在信息世界中黑客们是锋利的矛,那我们算法工程师就是一个坚固的盾。
当今业界几乎公认的一个共识在于,数据才是最宝贵的资产,而算法工程师的工作就是在这个宝贵资产中挖掘更多的变现渠道。
而现在,万一让合规部门的法务小姐姐知道你的模型可能涉嫌泄露公司数据,或者侵犯用户隐私,最终让公司承担预期之外的风险,给你一个核善的眼神自我体会一下。
其实,通过他人模型挖掘数据不是一个新鲜的课题。
尤其是在数据冷启动的业务中,花费高昂成本去专门建立一个标注任务简直是天方夜谈,剩下的除了使用无监督模型,只有使用开源模型进行一波数据增强了。
最经典的操作莫过于机器翻译任务中摸着谷歌和百度翻译引擎进行小语种翻译、回译等方式扩充数据集的操作了。
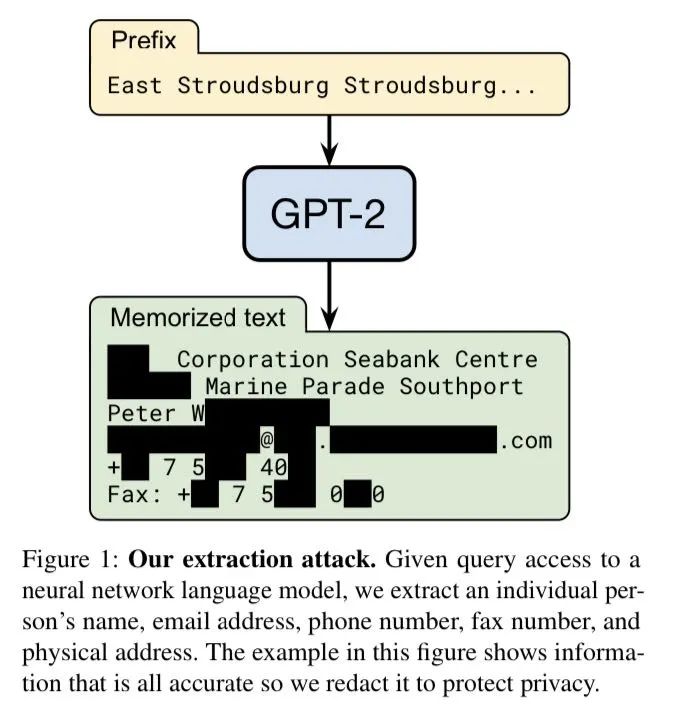
此外,甚至专门还有文章研究如何通过攻击大模型来挖掘训练数据(惊了,感觉第一个想到这个发文方向的人绝对脑子很活),它的名字起的非常直白,就叫做 Extracting Training Data from Large Language Models [3],研究人员来自谷歌、斯坦福、伯克利、东北、 OpenAI、哈佛和苹果,甚至还有配套开源代码哦 [4]。
在这篇文章中,作者主要做出了以下几个贡献:
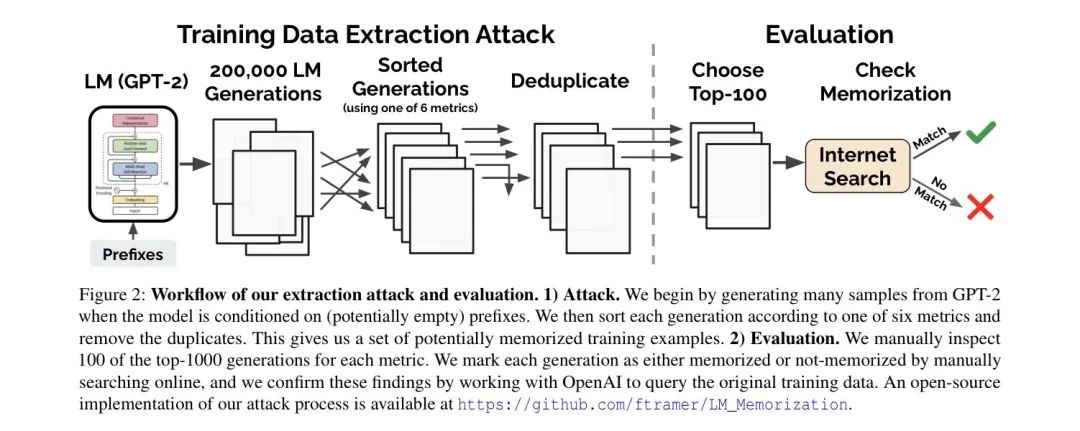
提出了一种简单有效的从大模型中获取序列数据的方式;
探究了模型会造成隐私泄露的原因——过拟合( overfitting );
量化地定义了大模型的“记忆力”( k-Edietic Memorization );
探讨了如何避免泄露的几种方式。
首先让我们跟随作者脚步,两步走套取 GPT-2 大模型中的数据:第一步,使用 prompt 技巧构建合理的前缀,并输入大模型,获得结果;第二步,针对获得结果进行排序,同时使用搜索引擎确认哪些信息是完全检索自互联网,哪些是模型自我生成的。
在文中作者为了确认这套工作流的可行性特意联系了 OpenAI 访问了他们的原始训练集,最终他们确认了这套流程的有效性。
看完这套动作小编只想说,prompt 工程师永远滴神,大佬扎堆的项目最终竟然也是在第二步中靠人工手动搜索打标(捂脸)。
好在后续工作中大佬的不少讨论还是非常高大上洋气的。
例如作者认为模型泄露训练数据的本质是因为在关系推理的过程中,对训练集发生了过拟合的现象。
虽然随着模型参数规模和训练规模的不断增大,train loss 的平均值只是比 valid loss 的平均值稍微小一些,不存在传统意义上的过拟合现象,但是他在一些训练样本上依旧有着非常反常的非常低的 loss。这可能也是一种过拟合的形式。
同时为了量化解释大模型对于每个样本的记忆能力,结合 prompt 前缀,作者还定义了大模型的记忆力。
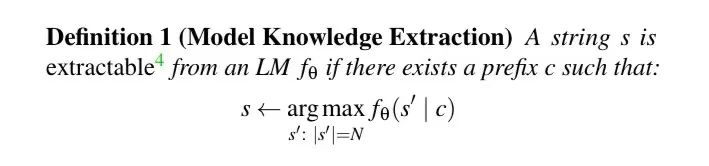

例如,假设我们给大模型输入“我的算法女神是______”,然后输出结果为“夕小瑶”!那么我们就称“夕小瑶”这个信息是已经被模型抓取到的知识。
再假设“夕小瑶”在训练集中最多出现了 k 次,那么我们就称“夕小瑶”这个字段是被模型 k 次异常清晰地记忆的。
在后续的实验中作者发现,k 越低的字符串在面临攻击时会泄露更多的数据,无论是从句子长度还是数量上。这也意味着,潜在的更私密的信息越有可能被泄露。这是否无意中解释了之前 GPT-3 泄露老哥真名的原因:同时满足了语料的稀缺性和稀疏性。
最后作者也针对了可能的一些减少模型数据泄露的方式进行了探究和畅想,例如使用差分隐私法( Differential Privacy )训练模型,限制敏感数据在训练集中的出现,在下游任务的 finetuning 中让模型“忘记”一些隐私,或是专门开发审计模型对模型输出进行审查。
但是可以确定的是,无论哪一种方案都或多或少地会影响到模型在线的业务性能,这一切都是 tradeoff。
可以预见的将来,或许会有越来越多有关 AI 侵犯用户隐私的问题出现,随着相关法规发条的逐步完善,说不定有朝一日算法工程师中也会有一个类似于数据安全“白手套”的合规测试岗位,专门为公司测试避免深度学习模型导致的重要信息的外泄问题。
算法专家和数据专家们,你,做好业务信息泄露的准备了吗。
参考文献:
[1] Feeling unproductive? Maybe you should stop overthinking, https://news.ycombinator.com/item?id=23893817
[2] Ask HN: GPT-3 reveals my full name - can I do anything?,https://news.ycombinator.com/item?id=31883373
[3] Extracting Training Data from Large Language Models, https://arxiv.org/abs/2012.07805
[4] Training data extraction from GPT-2, https://github.com/ftramer/LM_Memorization