
用隧道协议实现不同dubbo集群间的透明通信
用隧道协议实现不同dubbo集群间的透明通信
前言
笔者最近完成了一个非常有意思的隧道机制(已在产线运行),可以让注册到不同zookeeper之间的dubbo集群之间能够正常进行通信。如下图所示: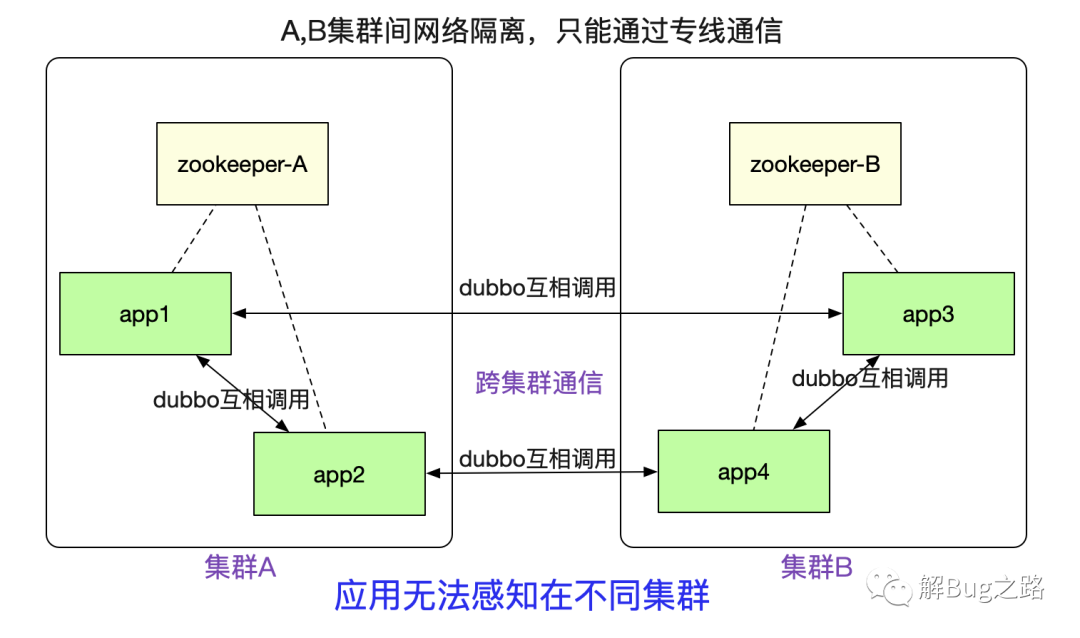
例如图中A/B两个网络隔离的集群,两者只能通过专线进行通信。但是对于在里面的应用来说,调用另外一个集群的dubbo服务(例如app1调用app3)依旧和原来的方式一模一样,无需做任何修改。这个特性对于新建单元(机房),业务网络隔离等场景非常有用。
本文就稍稍聊一下这个机制。
场景
这个dubbo集群通信机制,可被用在下面的场景中。
新建机房
在我们新建一个机房的过程中。正常情况下,需要将一整条链路的所有应用以及相关设施全部部署到新的机房中。如下图所示: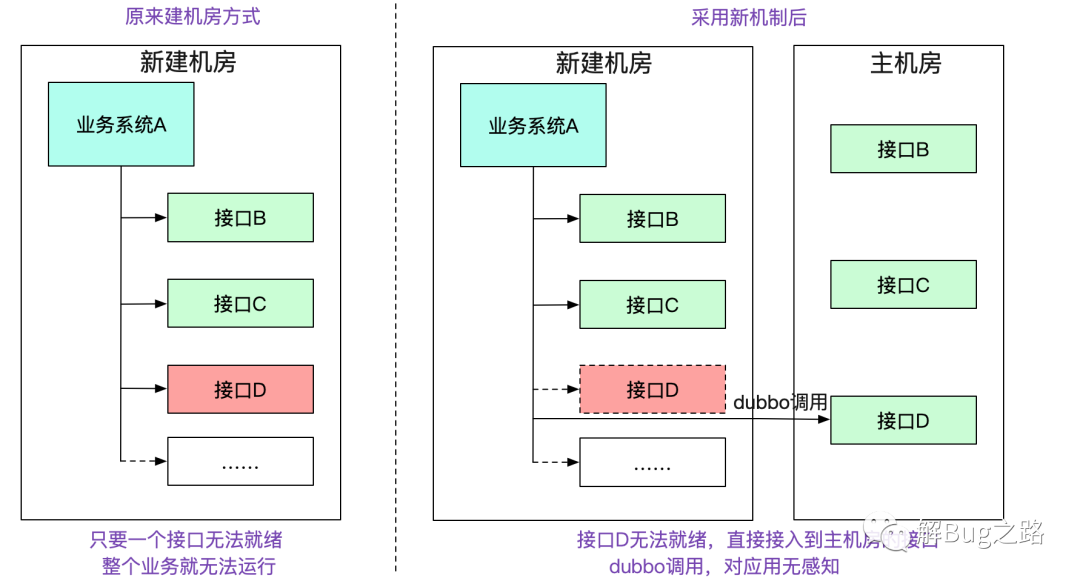
而在笔者新的机制中,如果本集群没有对应的接口,会去寻找有对应接口的集群,就算其中缺失了一些系统,整个机房依旧能够work,将新建机房变为可迭代式的。大幅度减少了新建机房的复杂性。
新建业务单元
由于单机房机架位的限制或者一些其它原因,有一些业务希望剥离到一个单独的单元(机房里面)。但是业务确需要一大堆原来单元的基础服务。而不同单元之间的网络又无法打通(安全性要求)。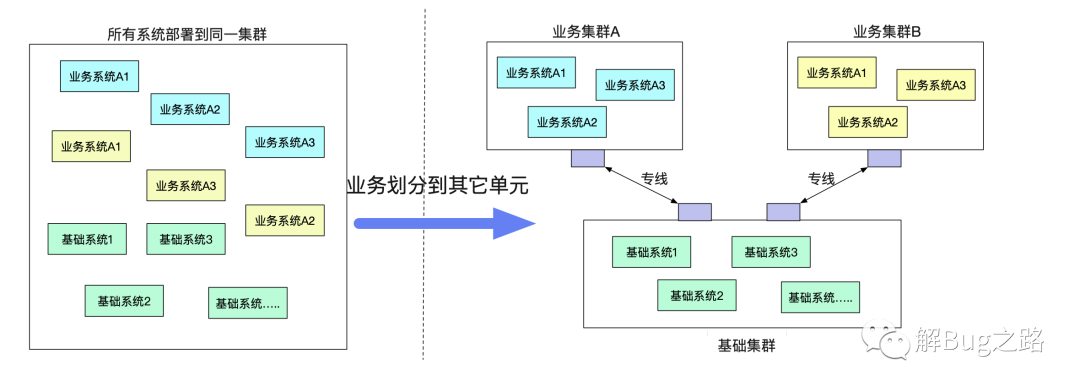
如果按照传统的模式,势必要对业务系统做改造,例如建立一个业务网关来负责和基础系统的通信,这个网关明显费时费力而且没什么技术含量,例如在业务代码中将dubbo调用强行转换为对业务网关的http调用,如下图所示: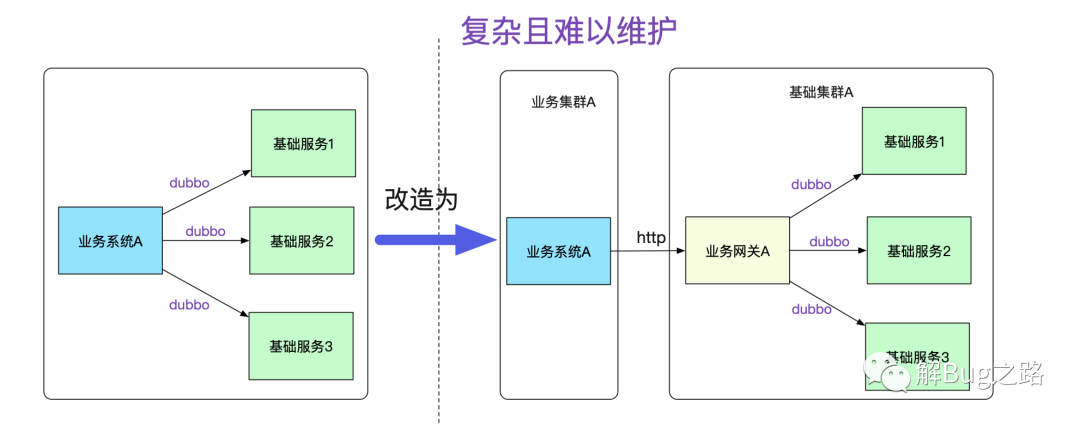
而且,每增加一个接口调用,都得在业务网关中转换一把,添加对应的接口包,然后发布。这样的网关维护起来肯定是个天坑!随着日益严格的安全性要求,不同业务间的网络隔离要求会与日俱增。
笔者是搞中间件的,坚信做的基础服务能够对业务透明,让其感知不到才是一个好的设计。一旦需要业务大量配合这种由基础架构变更而引起的改造,无疑是非常的不友好,甚至是个失败的设计。
故障隔离
事实上,笔者搞这一套隧道机制的初衷还有很大一部分原因是故障隔离。例如,笔者遇到数次由于业务系统使用zookeeper不当,往zookeeper写了一大堆数据,从而让整个集群陷入不可用的风险。而新的机制,可以让不同的业务注册到不同的zookeeper,zookeeper挂了,也只是这个业务宕了,其它业务则不受影响。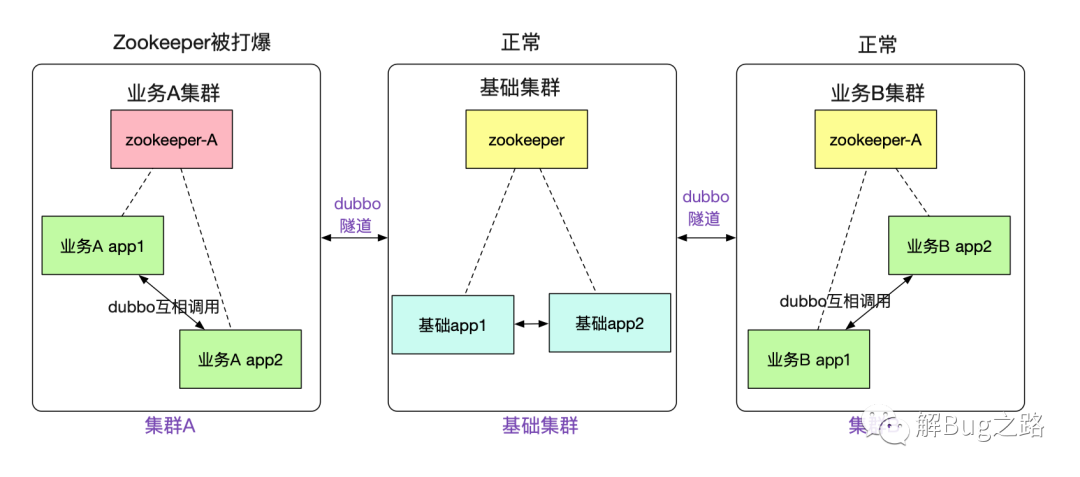
事实上不仅为zookeeper,由于笔者对消息(例如activemq)也做了这一套类似的隧道机制。使得我们的整个业务能够更好的进行故障隔离!
隧道机制
笔者这个机制的最大便利性在于对业务的侵入性很少。对于基础集群的应用甚至完全不需要做修改。为了达成这个需求,笔者引入了在网络上非常常用的隧道概念(Tunnel),这个大家可能平时都接触过,VPN/Vxlan这些网络协议都用了隧道。
隧道穿透
我们先来看一下最基本的原理,在系统A通过Dubbo调用系统B的时候,在同一个集群中走的是dubbo协议。而跨集群的时候,笔者将dubbo原始比特流承载在http协议上,在专线上发出去。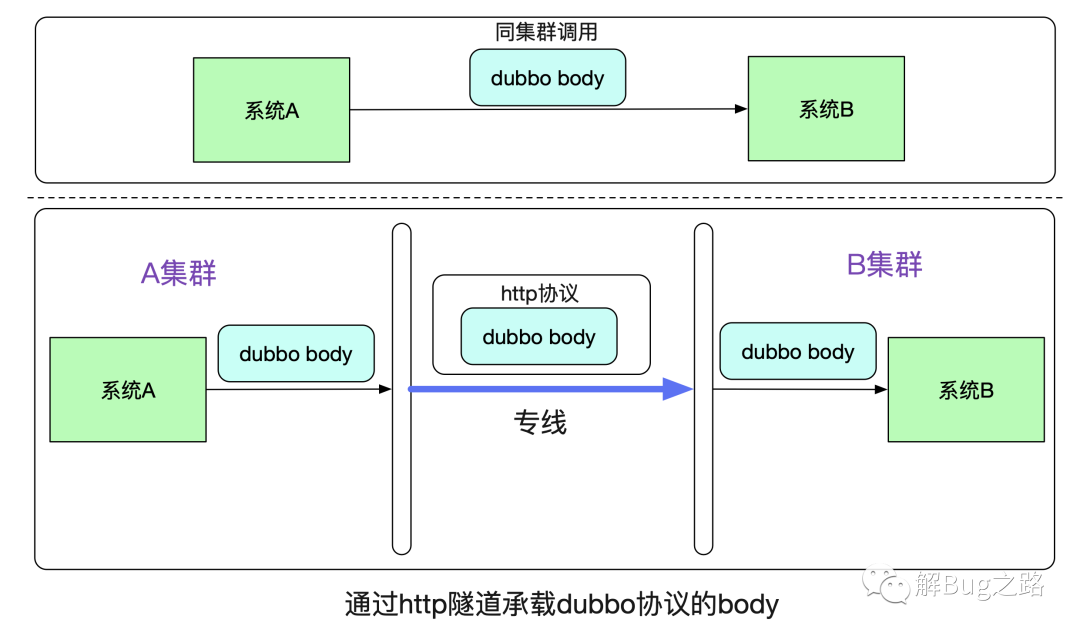
由于在B系统看来,接收到的都是相同的byte流,其无法(也不用)区分到底是走了一层专线还是直接调用。所以B系统无需更改任何代码。
隧道实现
那么,这个隧道具体是如何实现,系统A又是如何知道需要本集群没有对应的接口,需要通过http隧道调用到另一个集群的呢?这就引入了我们的隧道网关。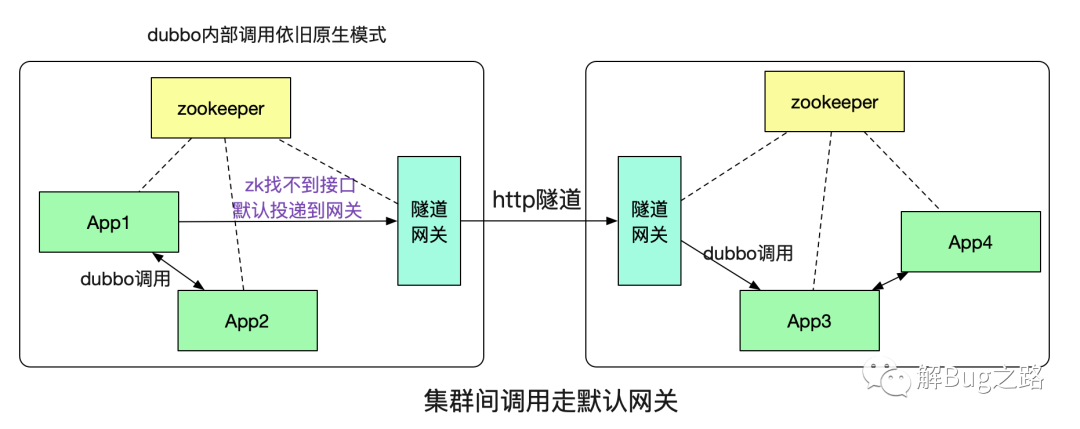
这里的概念也是和网络上的默认网关类似,如果本集群内找不到对应的接受者就投递到一个默认的网关,由这个隧道网关来替我们传递调用。
如何发现这个网关
为了充分利用dubbo接口的注册发现机制,笔者将隧道网关也暴露为一个dubbo接口,其输入和输出分别如下所示:
// 隧道网关接口请求体
class TunnelInterfaceReq {
// dubbo元信息,例如具体调用接口信息
MetaData dubbo
// 原始请求A调用序列化后的比特流
byte[] body;
}
// 隧道网关接口返回体
class TunnelInterfaceResp{
// dubbo元信息
MetaData dubbo
// 返回值调用序列化后的比特流,由另一个集群的对应系统返回
byte[] resp;
}
有了这个dubbo接口,我们就可以很容易的将数据传送给默认网关了。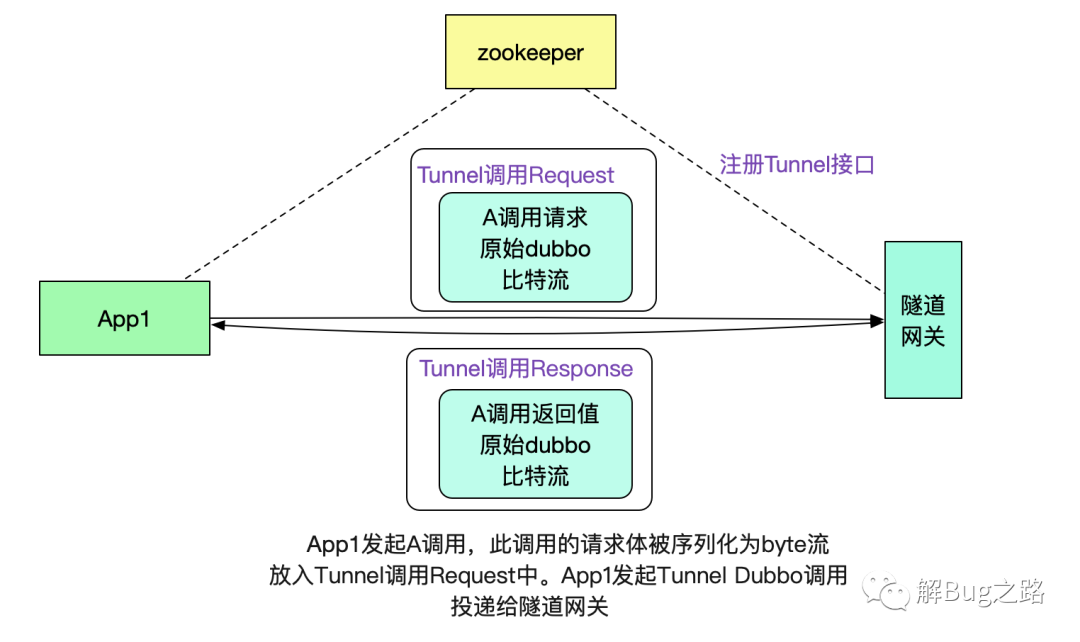
注意,这里其实也是做了一层隧道协议,即用dubbo协议承载dubbo协议,用这种类似套娃的方法有效的利用了dubbo本身的注册发现机制。
网关和网关之间通过http通信
由于不同集群之间通过专线进行通信,所以笔者采用了http通信来进行。在App1的请求到达隧道网关后,网关会将原始body比特流从TunnelInterfaceRequest中取出。然后放到一个http的请求中进行传递。如下图所示: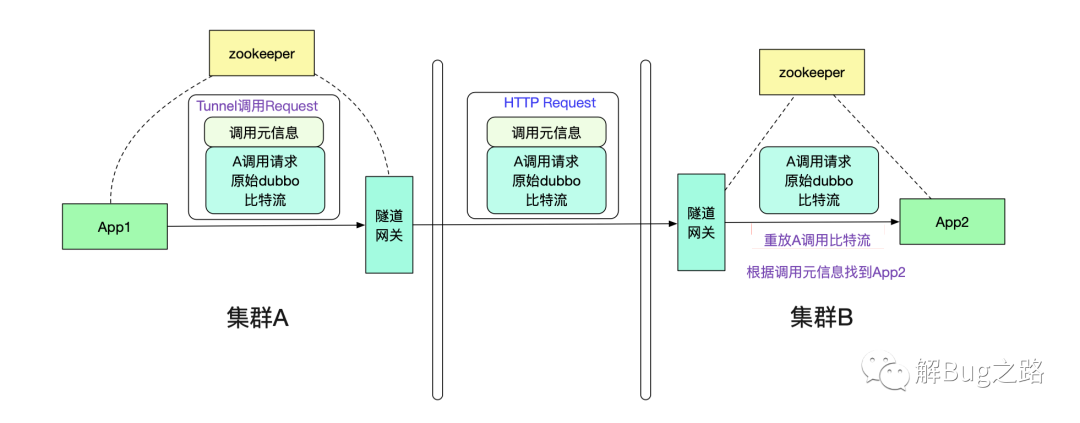
值得注意的是,由于传递的是byte流,没有携带任何业务信息(例如类型信息等),所以我们的隧道网关可以对任意dubbo请求进行隧道传输,而不像传统的网关那样需要添加各种业务对应的jar包并不停发布-_-!
在图中,投递到另一端的隧道网关后,其从http协议中取出调用元信息和原始调用byte流,通过调用元信息找到App2。然后给App2重放byte流,这样就可以进行dubbo调用了。事实上,App2从隧道网关看到的byte流和从集群内其它机器调用的byte流完全一致。如下图所示: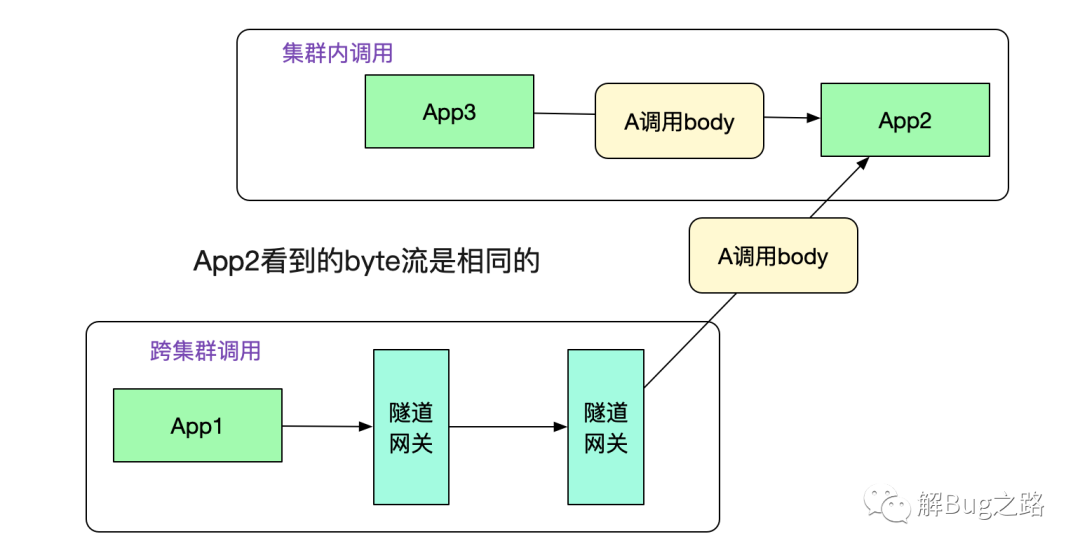
返回值也通过隧道机制
很明显的,我们的返回值也需要通过隧道机制。和Request一样,其也会走两次隧道协议,如下图所示: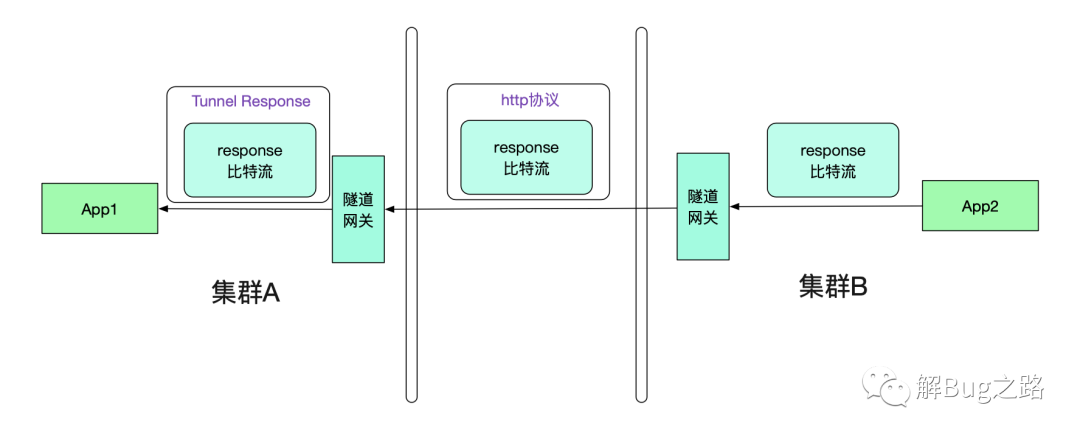
那么App1真正接收到的其实是Tunnel Response,怎么让其透明的接收原始response比特流呢?这就需要调用方接入笔者研发的轻量级jar包(其实,一开始的request的隧道也需要这样的jar包)
对dubbo进行扩展
由于dubbo有非常优秀的filter机制,可以在各种地方可以扩展。为了这个隧道机制,笔者就扩展了其中的invoke调用逻辑。如下图所示: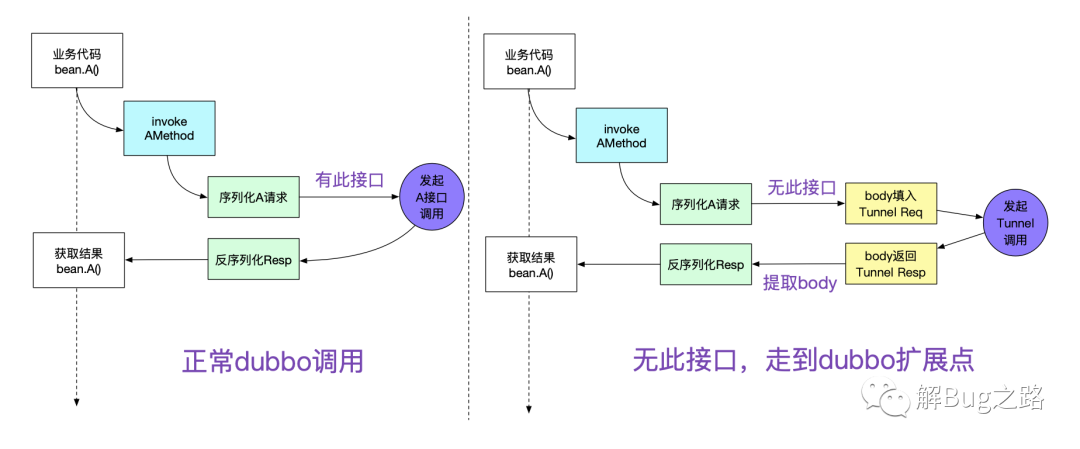
只要引入笔者写的jar包,就能够非常轻松的进行自动扩展,除了pom.xml加两行,其它业务代码完全无需修改。
隧道网关的接口发现
那么隧道网关A是怎么知道接口在集群B,从而投递给隧道网关B的呢?很明显的,我们需要隧道网关间的集群通信机制。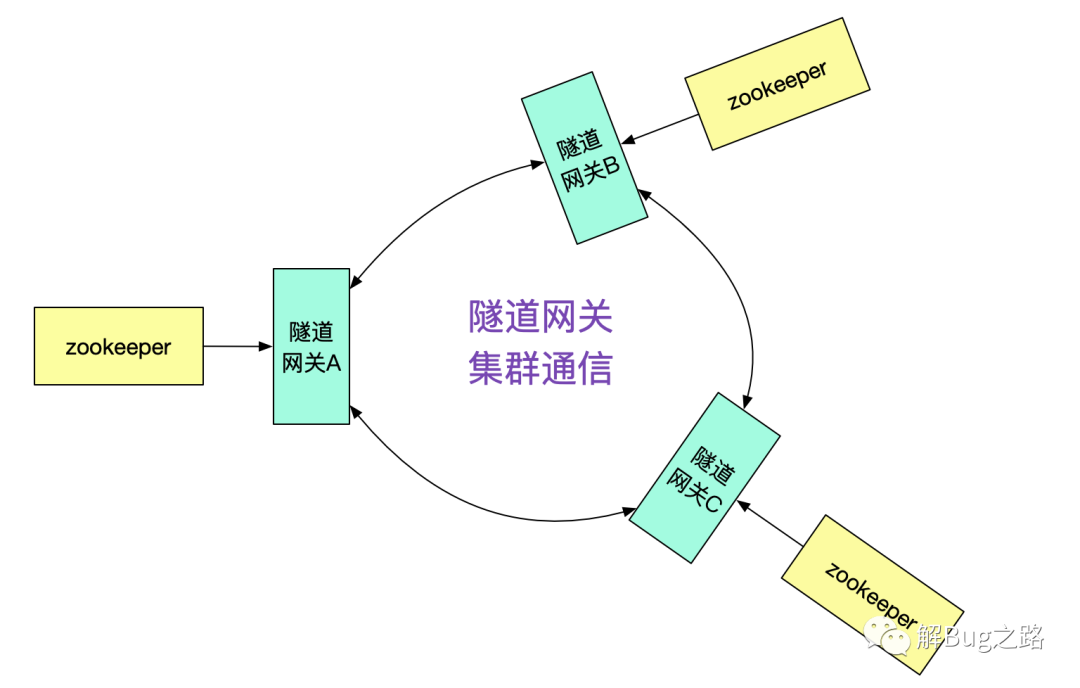
例如,由隧道网关向其它不同的隧道网关询问是否有此接口,并按一定策略做缓存即可。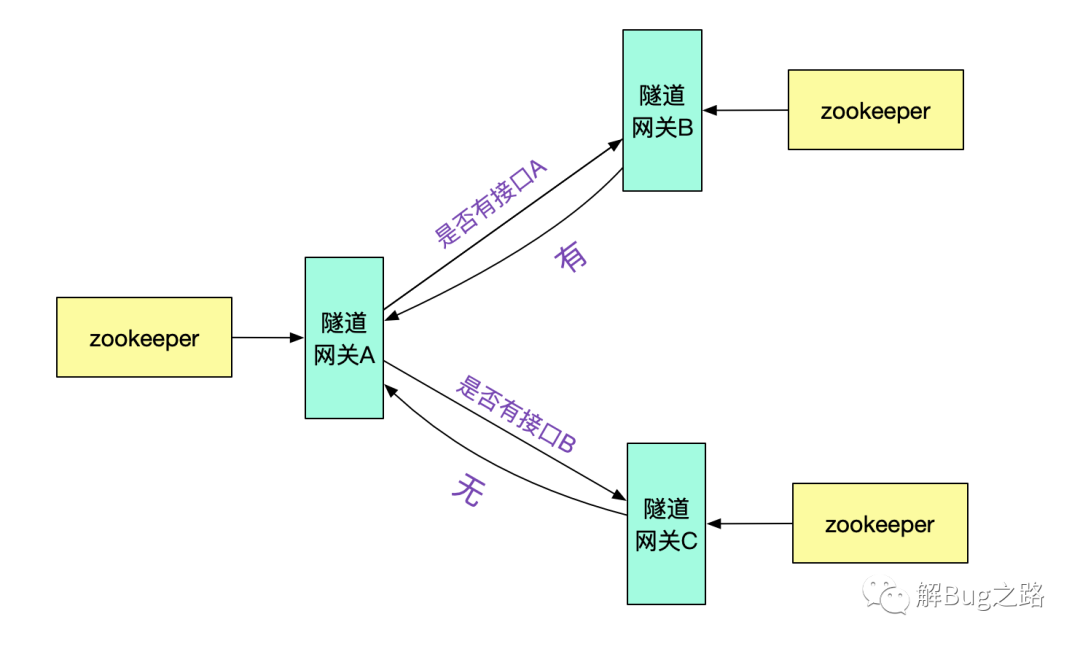
dubbo集群的发现
最后的问题就是隧道网关怎么知道其它的dubbo集群的了,由于相对于dubbo接口数量,集群的数量是很少且不经常改变。我们只需要找个地方简单的记录下即可,例如放到数据库里面。然后由于是http调用,直接通过DNS解析域名即可做负载均衡。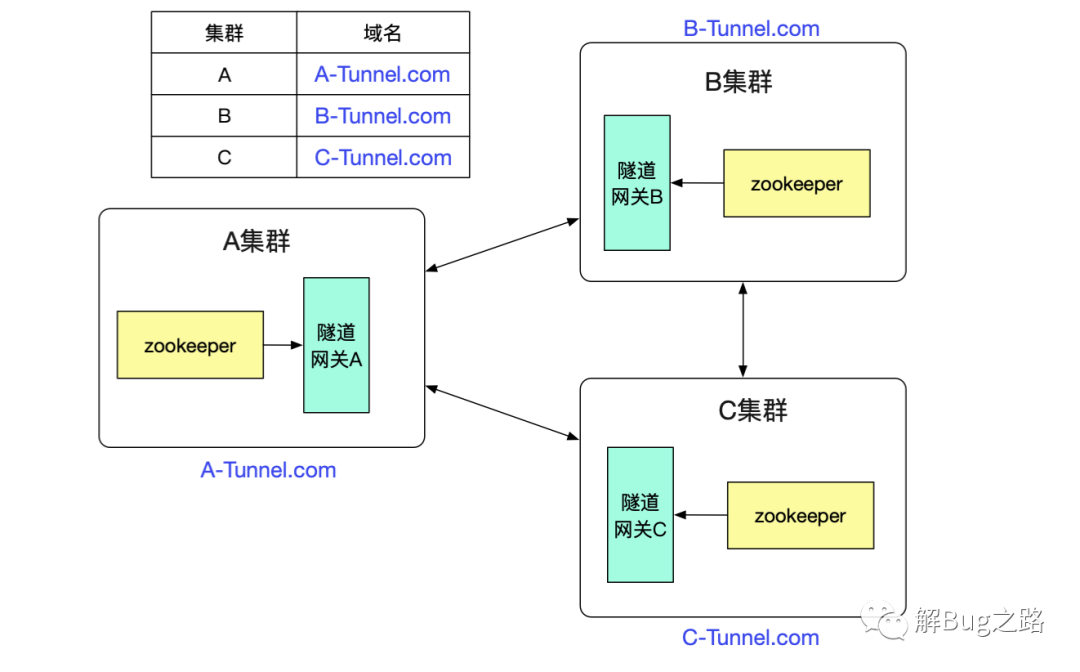
性能
由于笔者的这套机制序列化和反序列化完全在Provider/Consumer端,完全没有对网关形成任何压力,所以网关的CPU消耗很低。在单个调用延迟上,由于多了两跳,不可避免的有所损耗,大概每个接口多了2ms左右。
总结
这套机制从一开始构想,到完全能够在产线运行,并且性能损耗还很小,笔者还是花费了不少的精力。看到这样的结果,还是非常有成就感的。事实上,这套隧道机制在非常多的地方借鉴了网络上的概念。可谓它山之石可以攻玉!不同技术之间确实可以相互迁移,他们只是在不同的层级上解决了本质相通的问题!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!