
数据科学中的 10 个重要概念和图表的含义
来源:DeepHub IMBA
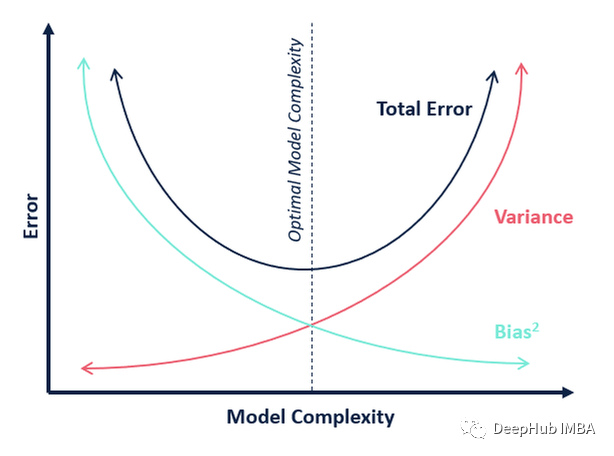
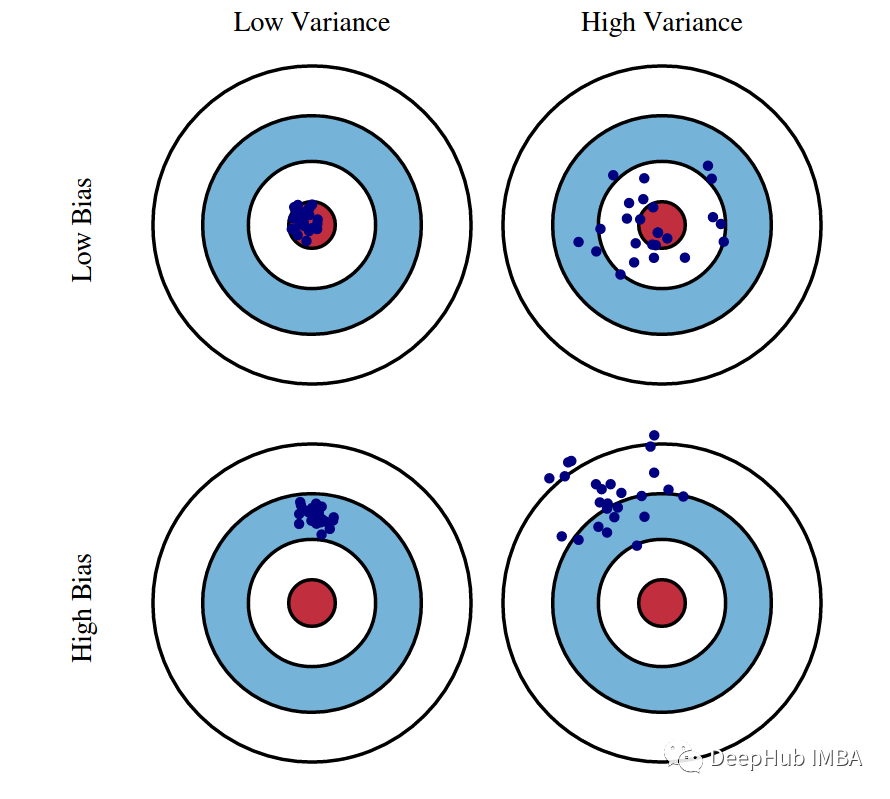
1、偏差-方差权衡
2、基尼不纯度与熵



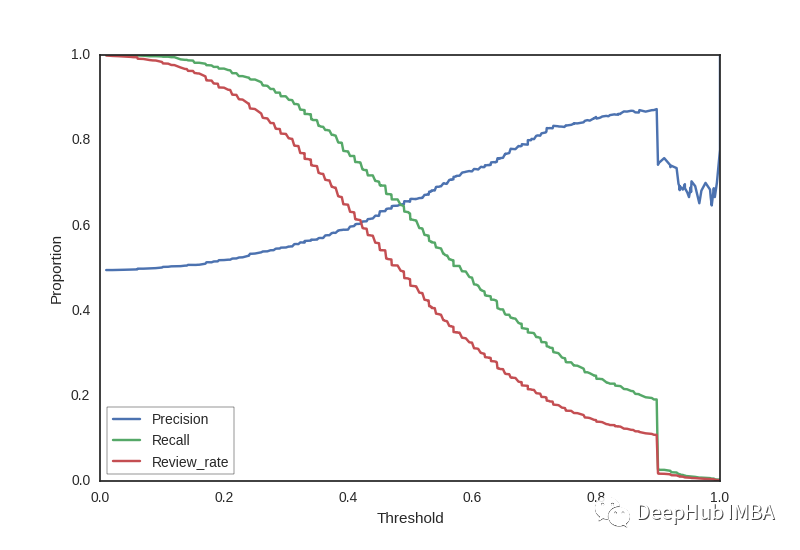
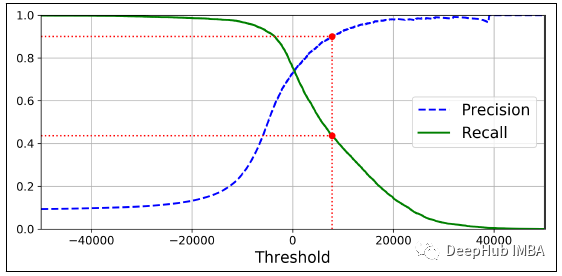
3、精度与召回曲线
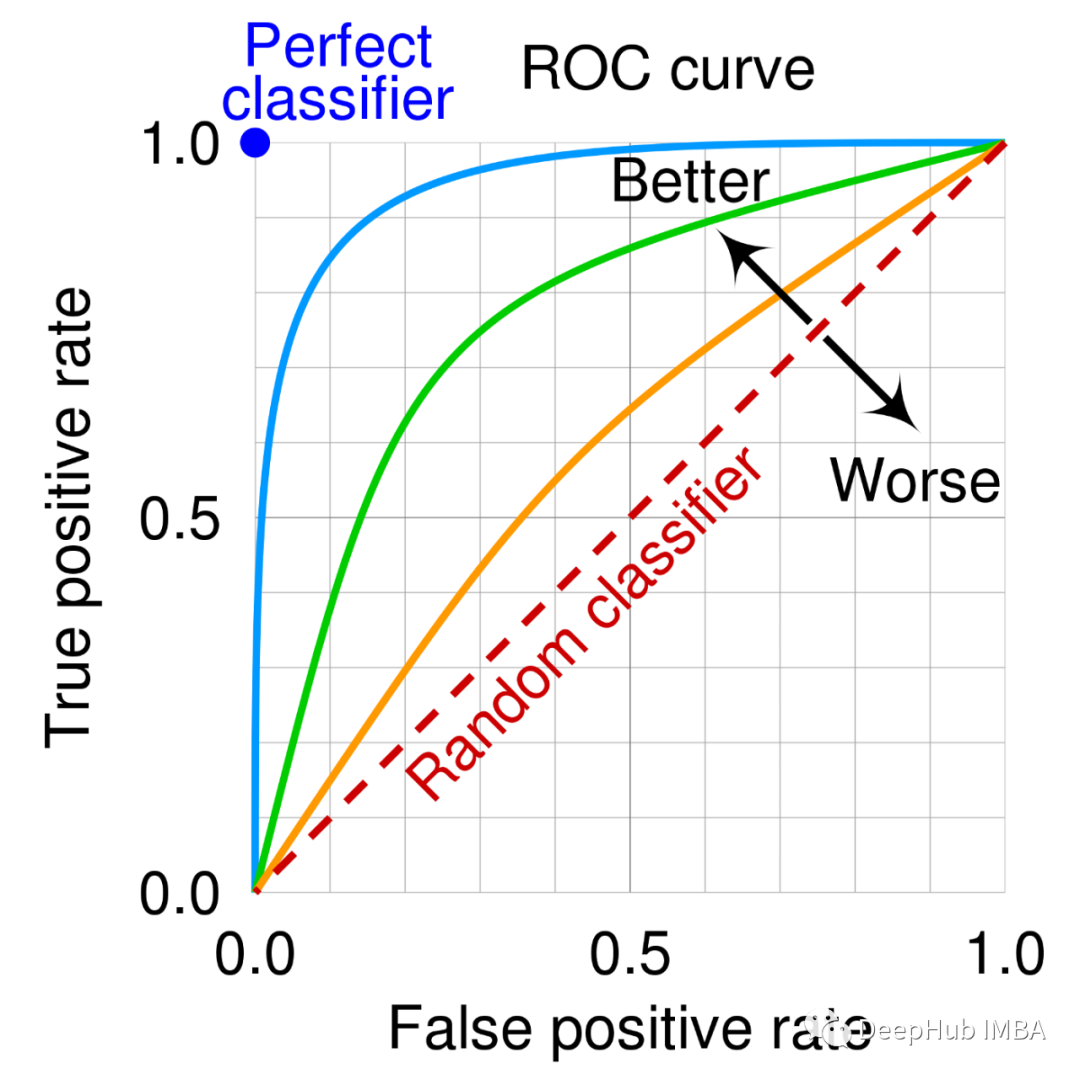
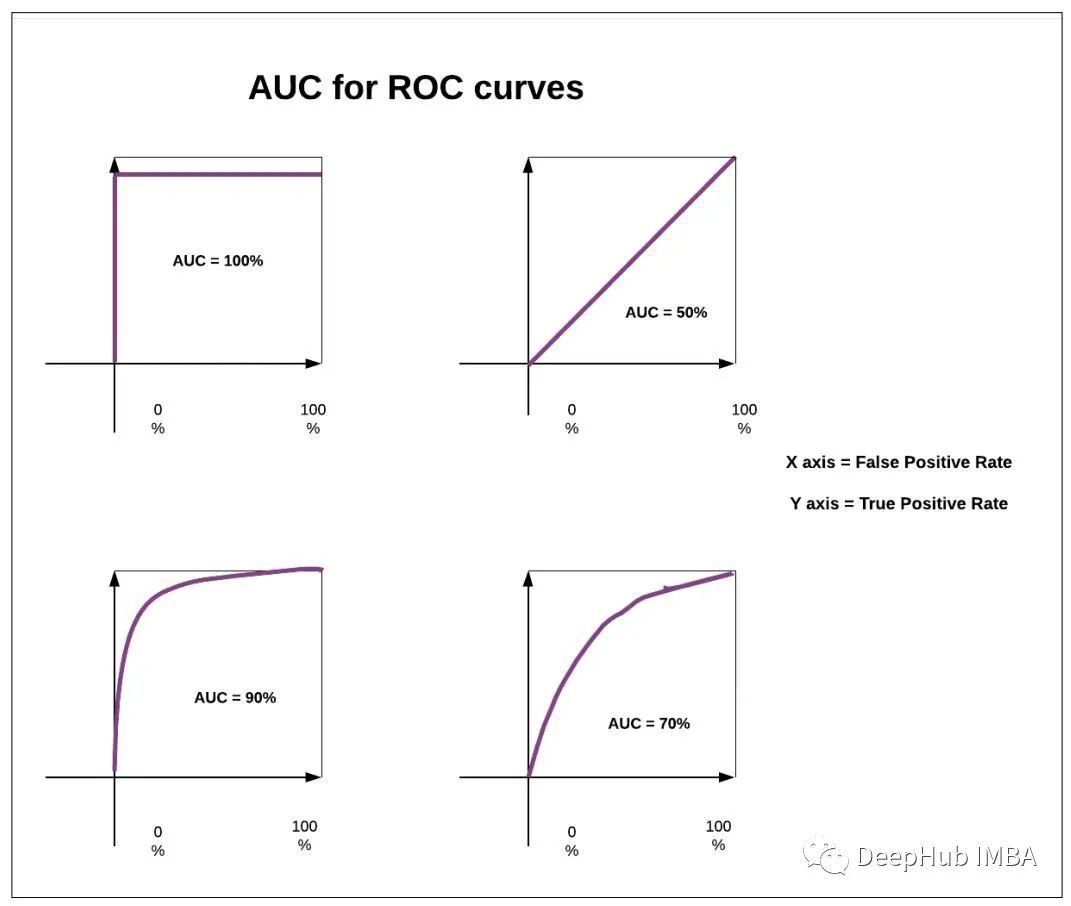
4、ROC曲线
真阳性率误报率
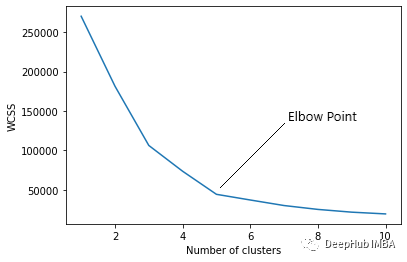
5、弯头曲线(K-Means)
随着聚类数量的增加,WCSS 值将开始下降。K = 1时WCSS值最大
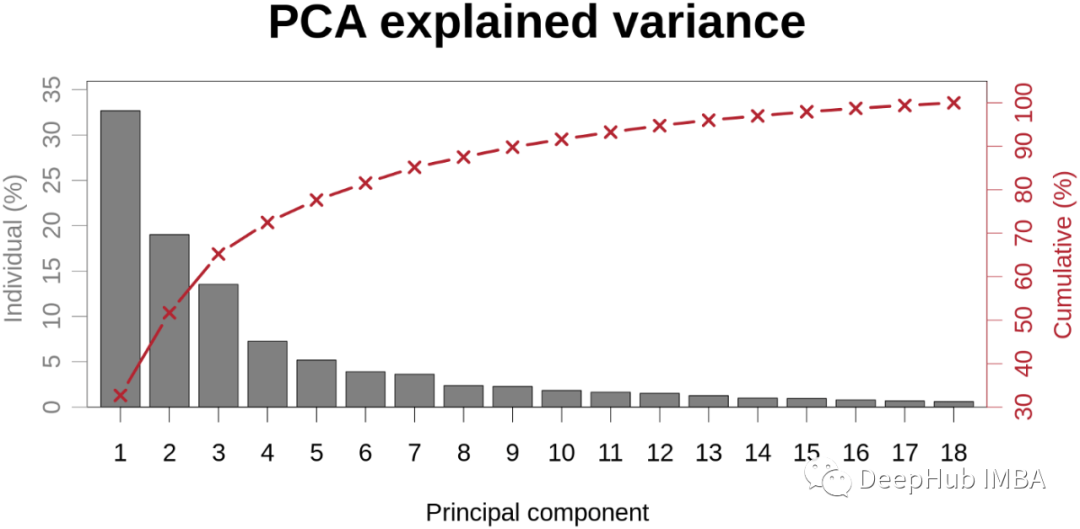
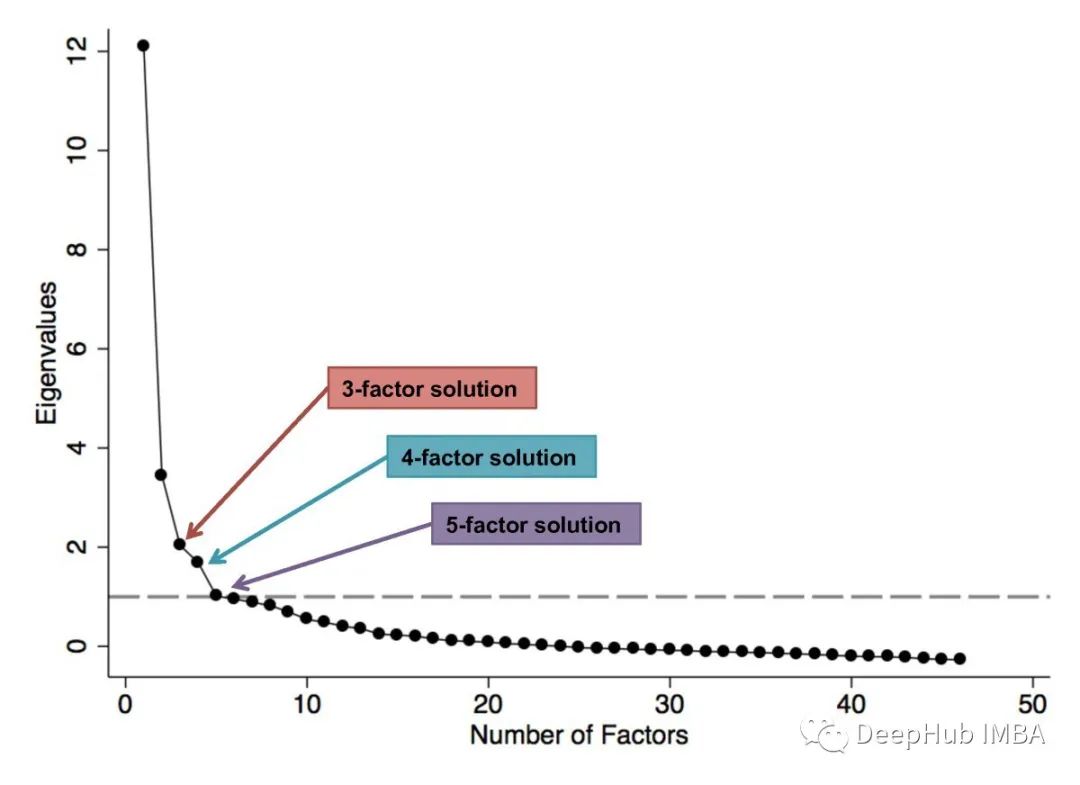
6、Scree Plot (PCA)

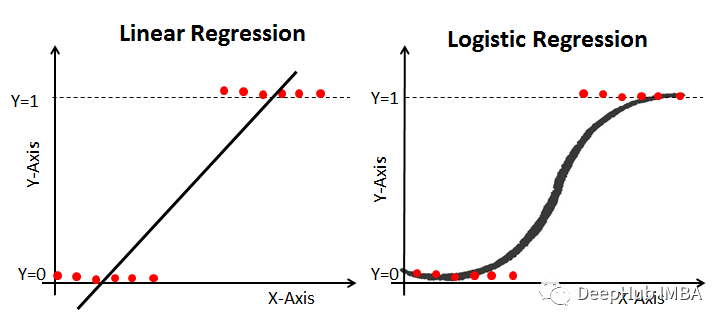
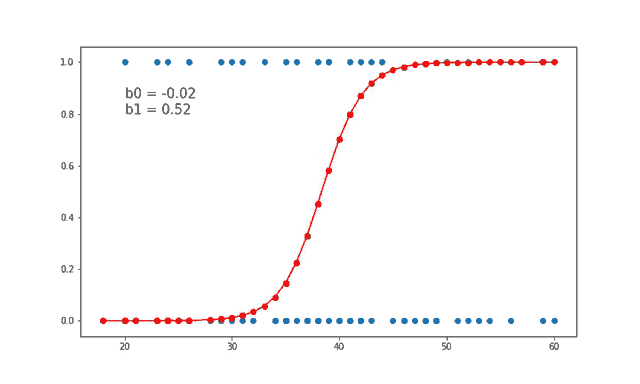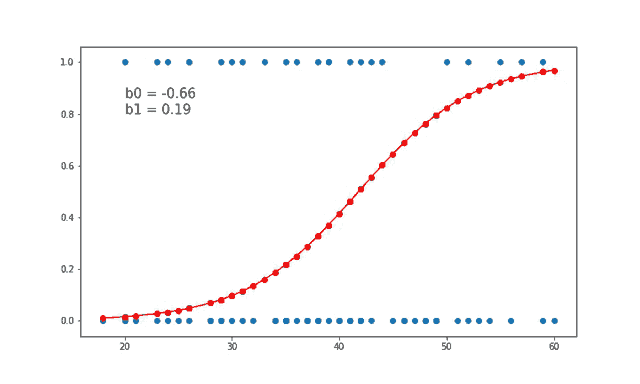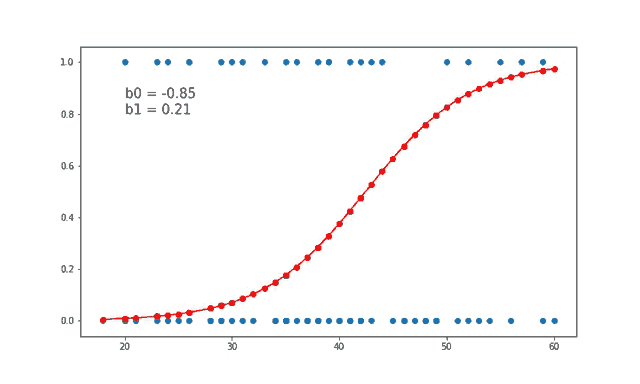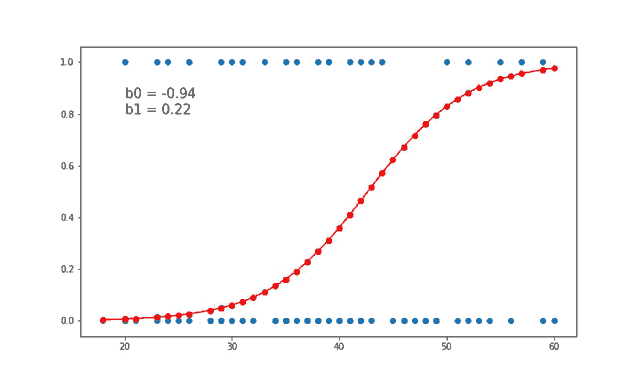
7、线性和逻辑回归曲线

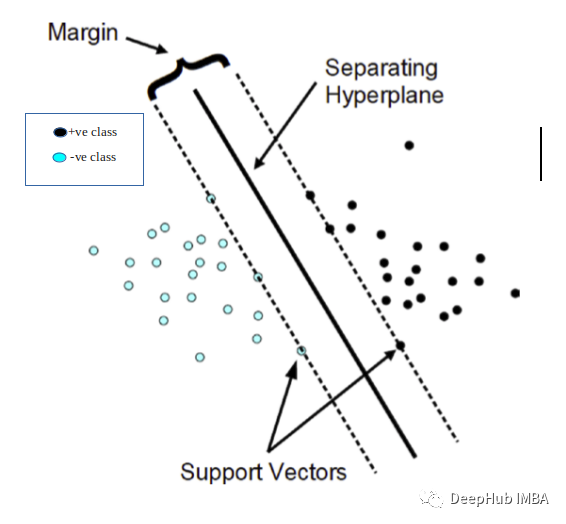
8、支持向量机(几何理解)
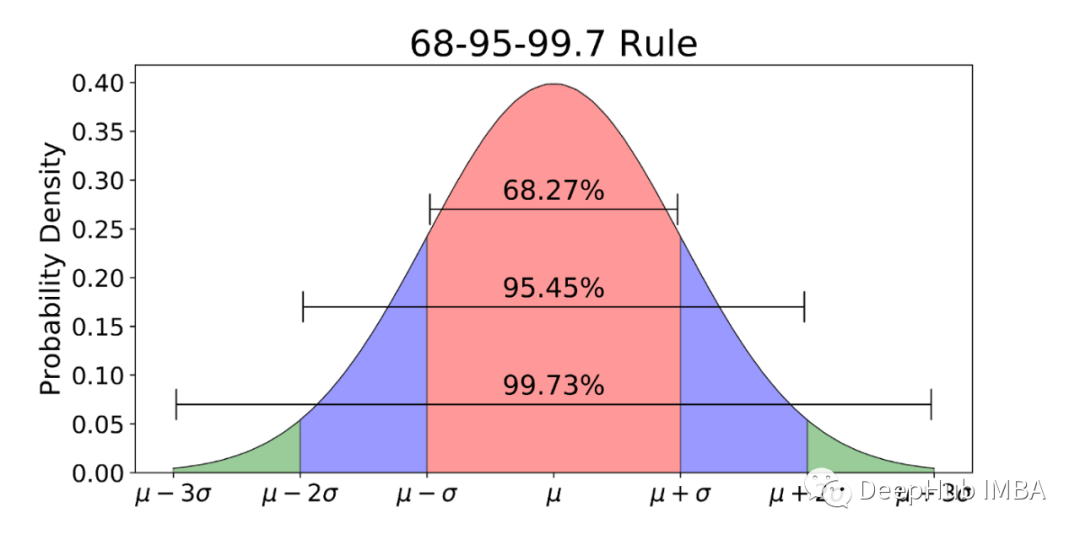
9、标准正态分布规则(z -分布)
10、学生 T 分布

最后总结
谢谢大家观看,如有帮助,来个喜欢或者关注吧!
本文仅供学习参考,有任何疑问及建议,扫描以下公众号二维码添加交流:
更多学习内容,仅在知识星球发布:
评论