
自己动手实现一个malloc内存分配器 | 30图
对内存分配器透彻理解是编程高手的标志之一。
如果你不能理解malloc之类内存分配器实现原理的话,那你可能写不出高性能程序,写不出高性能程序就很难参与核心项目,参与不了核心项目那么很难升职加薪,很难升级加薪就无法走向人生巅峰,没想到内存分配竟如此关键,为了走上人生巅峰你也要势必读完本文 。
。
现在我们知道了,对内存分配器透彻的理解是写出高性能程序的关键所在,那么我们该怎样透彻理解内存分配器呢?
还有什么能比你自己动手实现一个理解的更透彻吗?

内存申请与释放
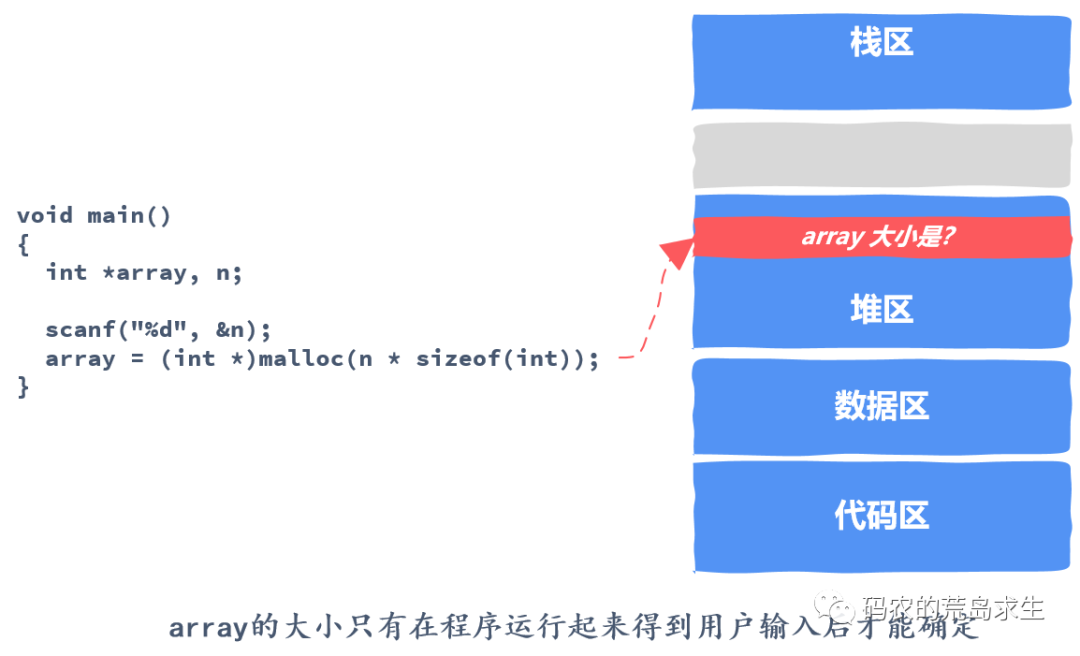
程序员应如何看待内存
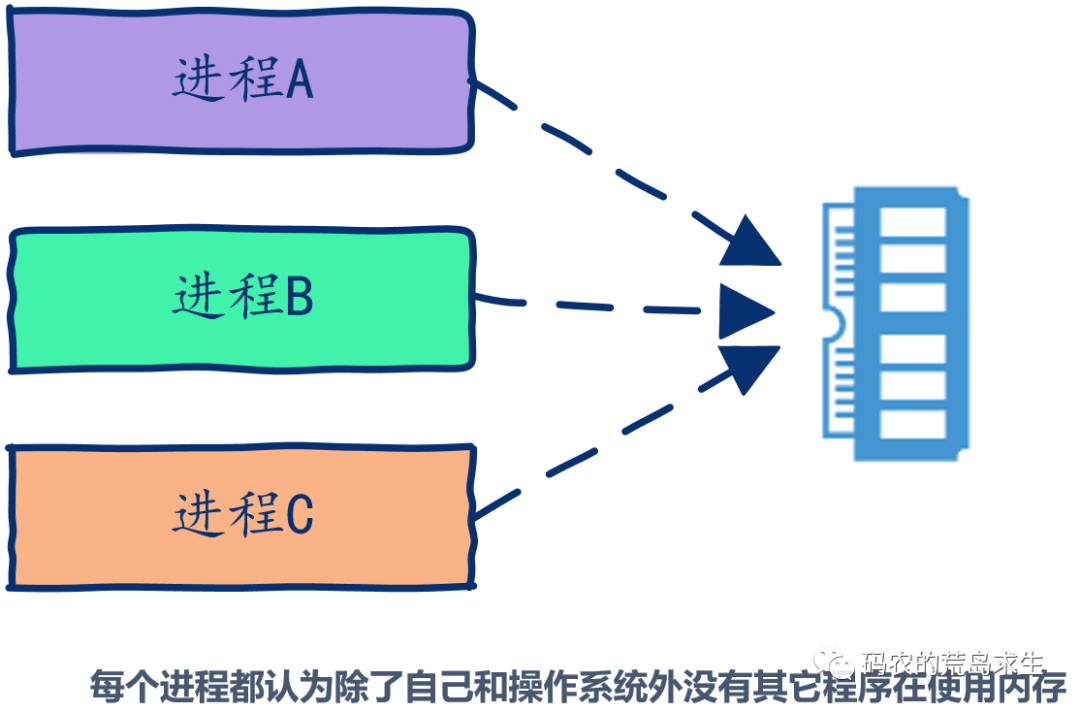

实现一个malloc函数,也就是如果有人向我申请一块内存,我该怎样从堆区这片区域中找到一块返回给申请者。
实现一个free函数,也就是当某一块内存使用完毕后,我该怎样还给堆区这片区域。
从停车场到内存管理

快速找到停车位,在内存申请中,这涉及到以最大速度找到一块满足要求的空闲内存
尽最大程度利用停车场,我们的停车场应该能停尽可能多的车,在内存申请中,这涉及到在给定条件下尽可能多的满足内存申请需求
任务拆分

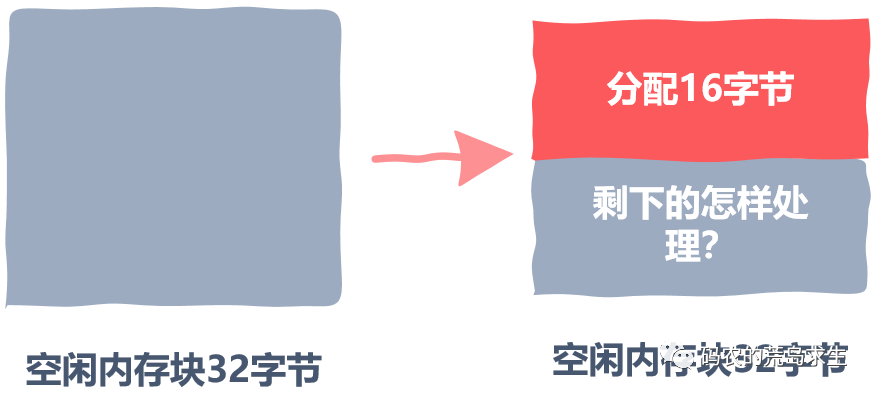
管理空闲内存块

一个标记,用来标识该内存块是否空闲 一个数字,用来记录该内存块的大小

跟踪内存分配状态
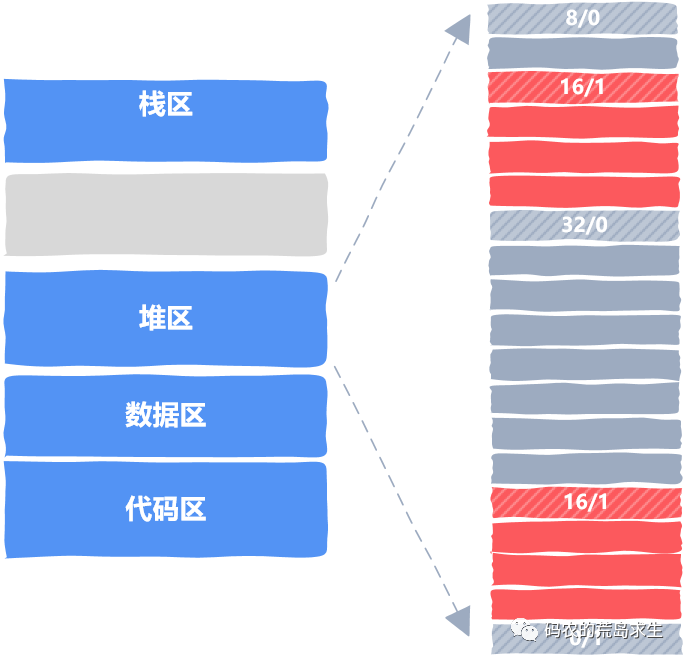
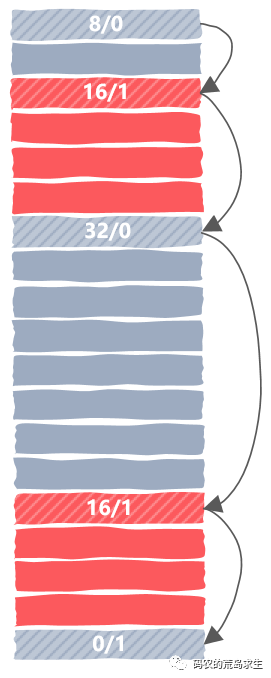
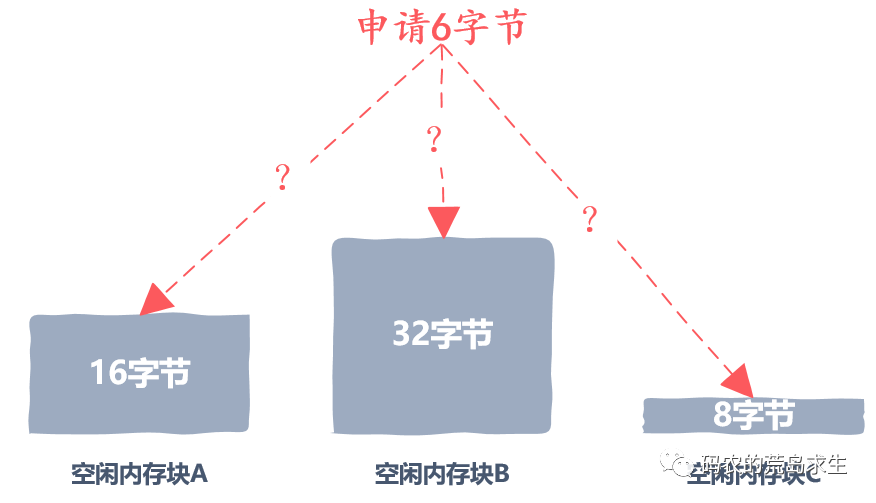
怎样选择空闲内存块

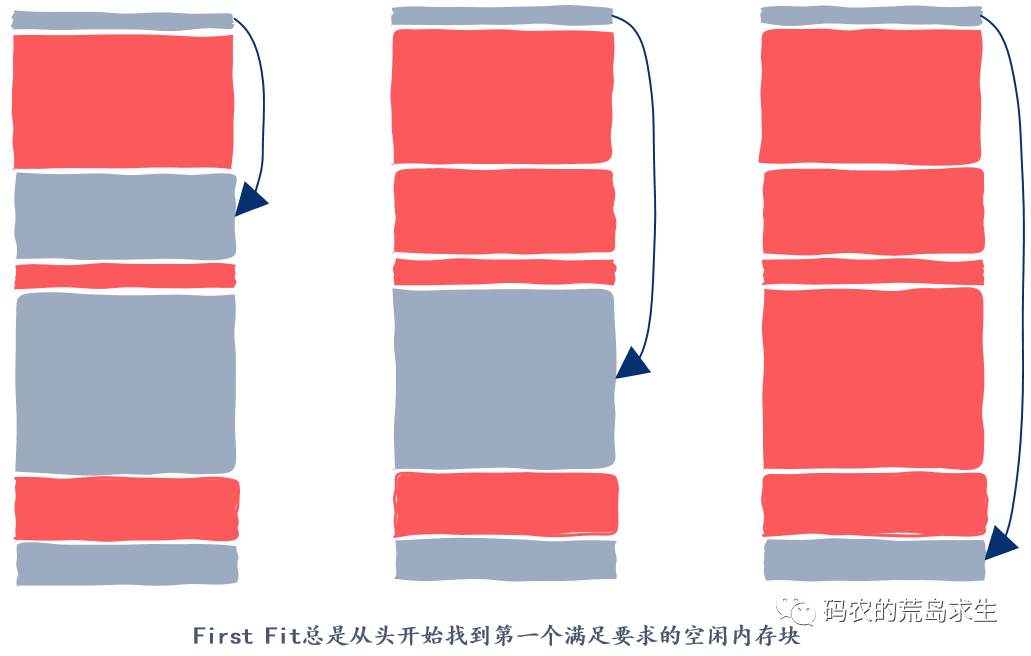

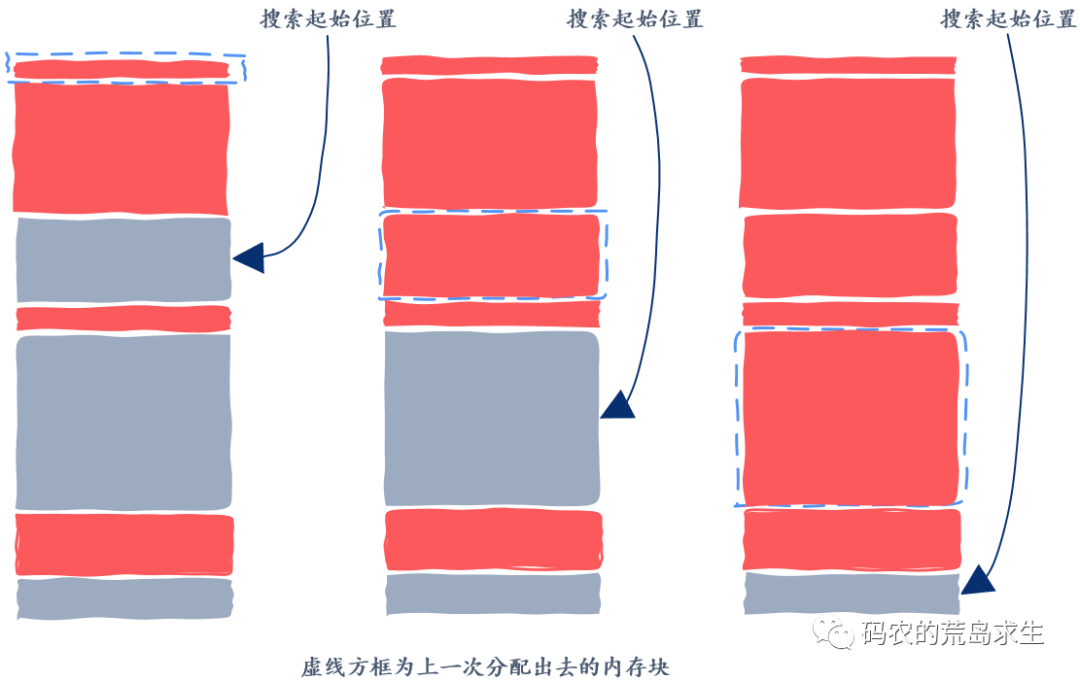
没有银弹

分配内存
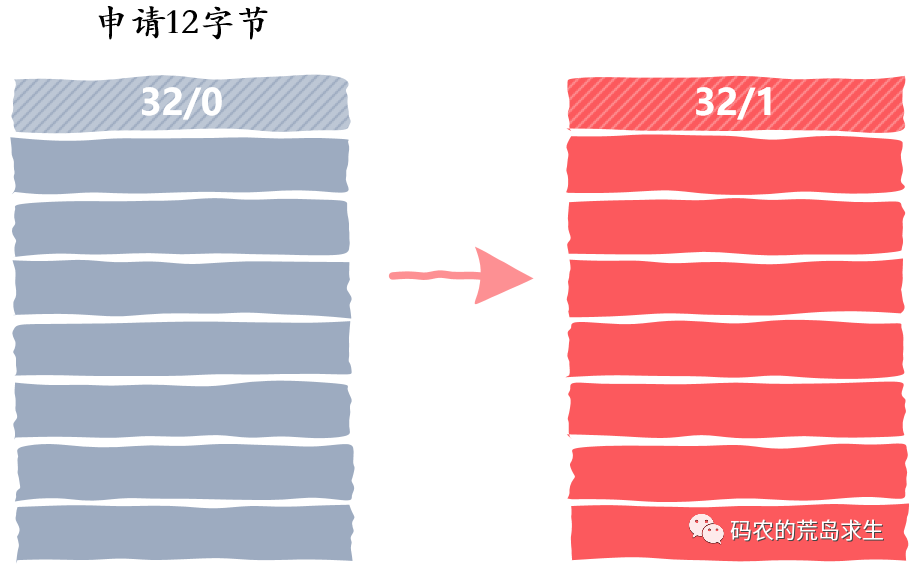
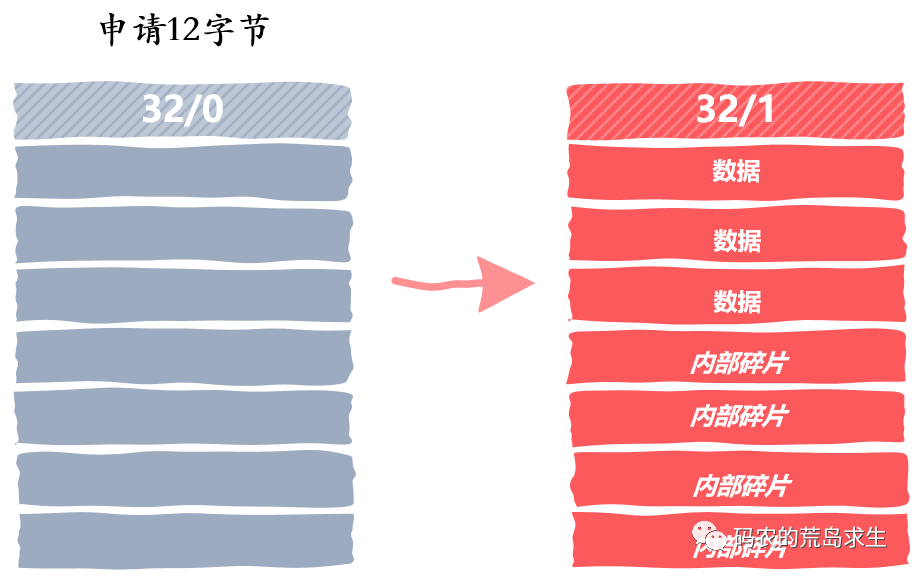
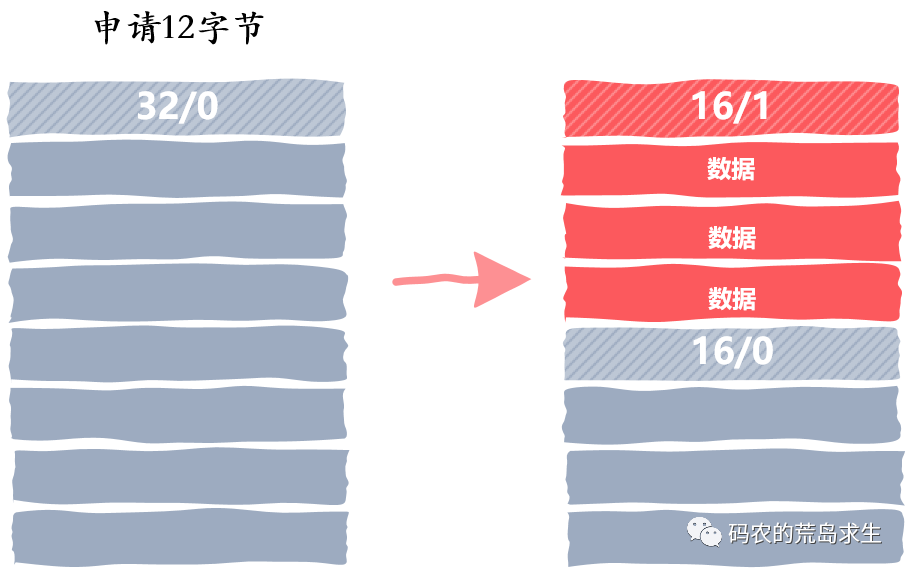
释放内存
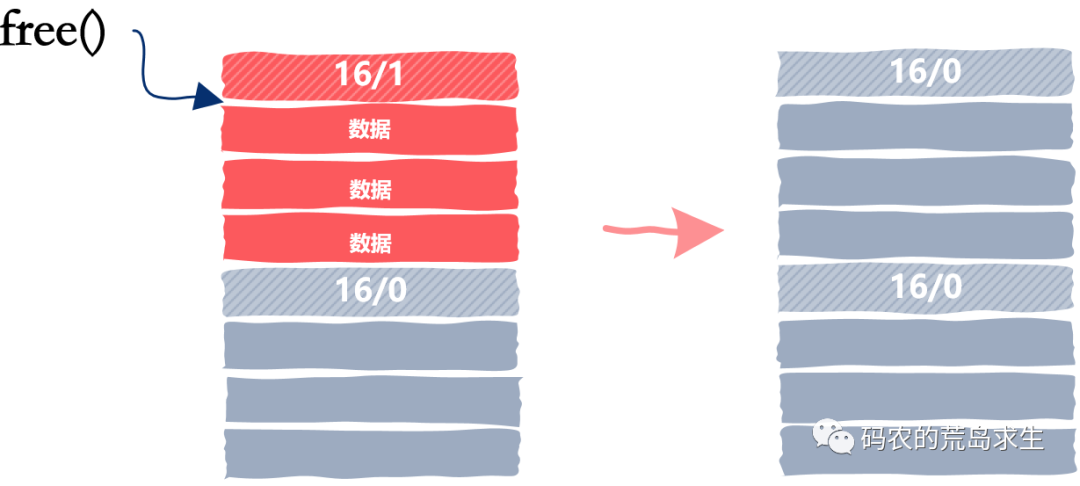
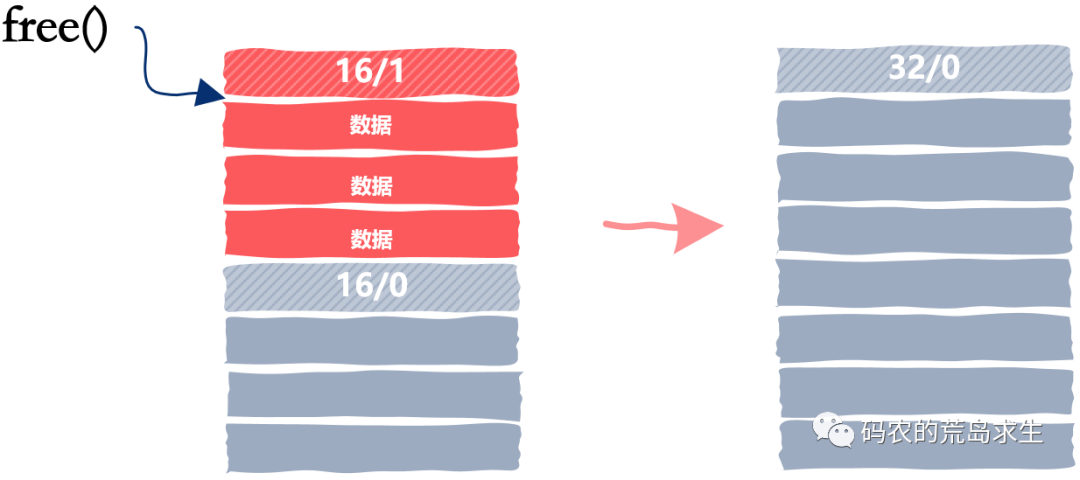
free(ptr);obj* ptr = malloc(12);free(ptr);obj* ptr = malloc(12);...
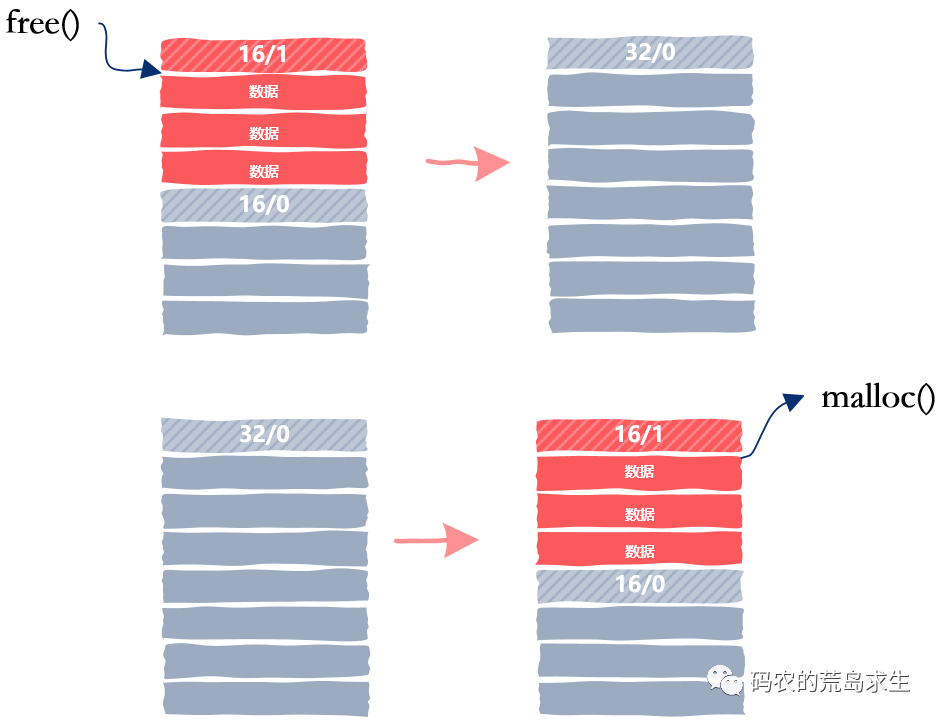
高效合并空闲内存块
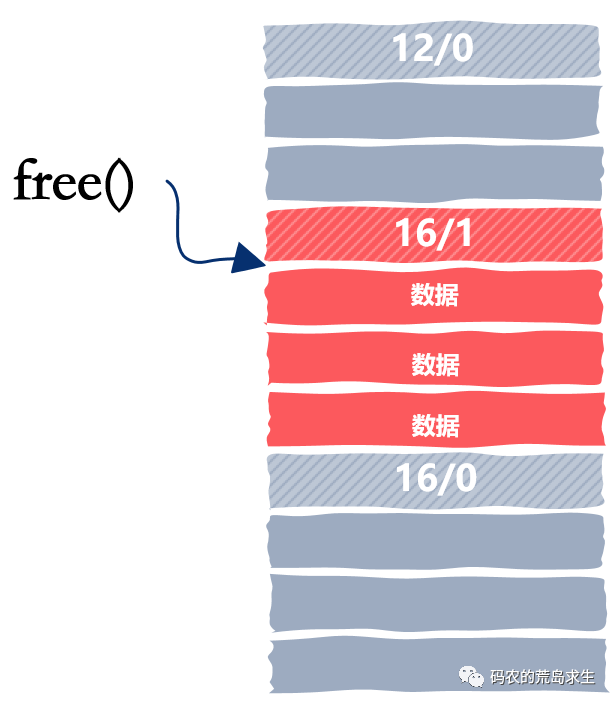
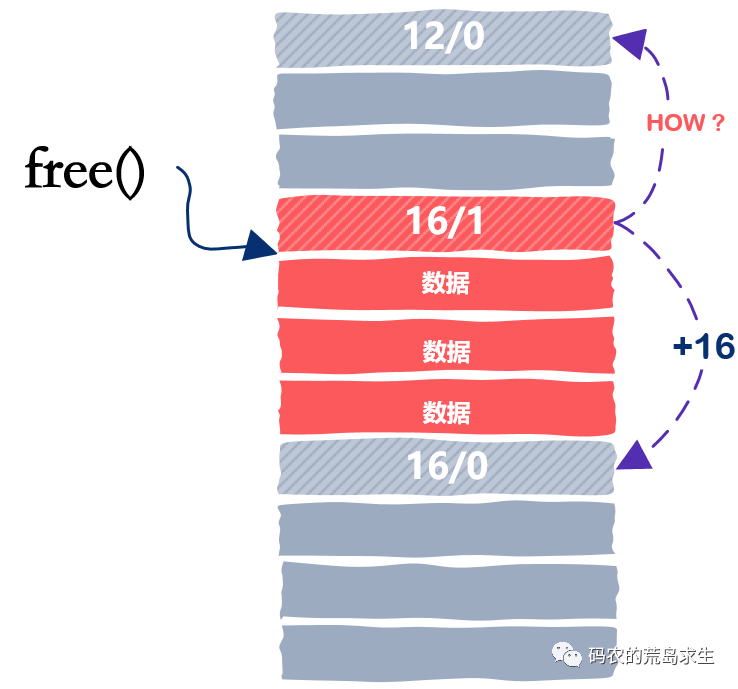

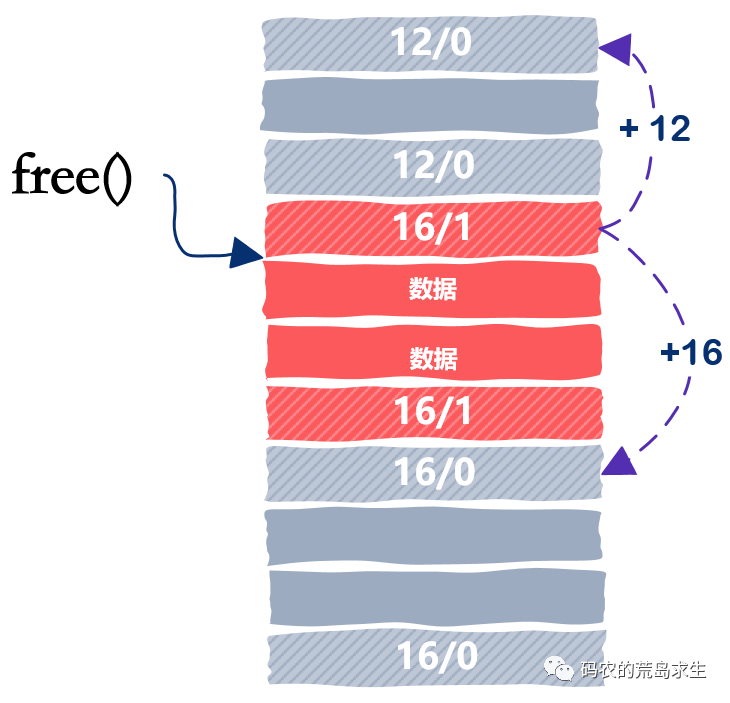
收工
总结
评论