
springboot第57集:Redis万字挑战,一文让你走出微服务迷雾架构周刊
Redis的内存回收机制通过内置的内存管理器来实现。当内存使用量超过了maxmemory配置的限制时,Redis会根据预先配置的内存淘汰策略来选择要删除的数据,以释放内存空间。这些策略通常基于数据的访问模式和重要性来决定,以保证在内存不足的情况下,删除的数据对系统的影响最小。
假设我们的maxmemory配置为100MB,当前Redis的内存使用量已经达到了100MB。此时有一个客户端执行了新的命令,向Redis添加了新的数据。由于内存已经达到了限制,Redis会根据预先配置的内存淘汰策略来选择要删除的数据或释放的内存块。比如,如果采用LRU策略,Redis会删除最近最少使用的数据,释放相应的内存空间,以保持内存使用量在可接受的范围内。
Redis的内存回收是由Redis自身的内存管理机制来实现的。当Redis的内存使用量超过了maxmemory配置的限制时,Redis会根据预先配置的内存淘汰策略来进行内存回收,以保持内存使用量在可接受的范围内。
内存回收的主要步骤如下:
- 客户端执行新的命令,向Redis添加新的数据。
- Redis检查当前内存使用情况,如果已使用的内存超过了maxmemory设置的限制,则触发内存回收机制。
- 根据预先配置的内存淘汰策略,Redis选择要删除的数据或者释放的内存块。
- 执行内存回收操作,可以是删除特定的键值对、释放缓存的数据、执行LRU算法等。
- 内存回收完成后,Redis会再次检查内存使用情况,确保内存使用量在maxmemory限制内。
Redis提供了多种内存淘汰策略,常见的包括LRU(Least Recently Used,最近最少使用)、LFU(Least Frequently Used,最不经常使用)、随机淘汰等。可以根据具体的业务需求和场景选择合适的淘汰策略来进行内存回收。
 image.png
image.png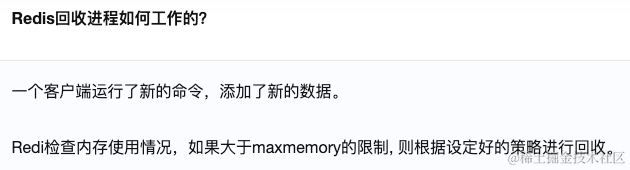 image.png
image.png可以将每个用户的信息存储在一个散列表中,例如:
HMSET user:123 name John email john@example.com password password123
以下几种方式来进行Redis内存优化:
- 合并小的字符串:如果需要存储的字符串较小,可以考虑合并多个小字符串为一个较大的字符串,以减少Redis中键的数量,从而降低内存占用。例如,将多个短字符串拼接成一个较长的字符串。
- 使用数据结构的压缩表示:Redis提供了一些数据结构的压缩表示,如压缩列表(ziplist)和整数集合(intset),它们可以在一定程度上减少内存的消耗。可以通过配置参数来启用这些压缩表示,例如对于列表类型的数据可以使用压缩列表来存储。
- 设置适当的过期时间:对于不需要长期保存的数据,可以设置合适的过期时间,让Redis自动清理过期数据,以释放内存空间。
- 使用LRU策略进行内存淘汰:当Redis内存达到限制时,可以通过配置LRU(Least Recently Used)策略来淘汰最近最少使用的数据,以保证内存占用在可接受范围内。
- 使用分片技术:将数据分散存储在多个Redis实例中,每个实例只存储部分数据,可以降低单个实例的内存压力。
 image.png
image.pngRedis集群中的复制是通过异步复制来实现的。在Redis集群中,每个主节点可以有多个从节点,主节点将自己的写操作同步给从节点,从而实现数据的备份和故障恢复。
具体的异步复制原理如下:
- 当一个从节点与主节点建立连接后,从节点会向主节点发送复制请求。
- 主节点接受复制请求后,将自己的数据发送给从节点,并开始进行数据同步。主节点将写操作记录到自己的AOF文件或RDB文件中,并将这些写操作发送给所有连接的从节点。
- 从节点接收到主节点发送的数据后,将这些数据写入自己的数据库中,实现与主节点数据的同步。
需要注意的是,Redis的复制是单向的,从主节点到从节点,不支持从从节点到主节点的复制。另外,复制是异步进行的,主节点不会等待从节点复制成功后再返回响应给客户端,因此主节点的写操作和从节点的复制是并行执行的,这也是可能导致数据丢失的一个原因。
原理解释: 假设我们有一个Redis集群,其中包含一个主节点和两个从节点。当主节点接收到写操作后,它会将操作记录到自己的AOF文件或RDB文件中,并将写操作发送给两个从节点。从节点接收到主节点发送的数据后,将这些数据写入自己的数据库中,实现与主节点数据的同步。
 image.png
image.pngRedis集群在某些情况下可能会出现写操作丢失的情况。这主要是由于Redis集群的异步复制机制和数据持久化策略导致的。
具体来说,当主节点接收到写操作后,它会将操作记录到自己的AOF文件或者RDB文件中,然后立即向客户端返回操作成功的响应,而不会等待从节点完成数据同步。因此,在主节点将写操作记录到持久化文件之后,它会立即返回成功的响应给客户端,这时写操作就被认为是完成了。
然而,由于从节点的复制是异步的,从节点可能不会立即复制主节点的写操作。如果在写操作记录到主节点的持久化文件之后但还未复制到从节点时,主节点发生故障,那么从节点将无法获得该写操作的复制,导致该写操作丢失。
这种情况通常发生在以下场景中:
- 主节点在将写操作记录到持久化文件后但尚未同步给从节点时发生故障。
- 从节点在复制写操作之前发生故障。
因此,Redis集群并不能保证数据的强一致性,而是提供了较强的最终一致性。在实际应用中,开发者需要根据业务需求和数据一致性的要求,采取相应的数据备份和恢复措施,以减少写操作丢失的可能性。
 image.png
image.pngRedis集群的主从复制模型是一种典型的分布式架构,旨在提高数据的可用性和可靠性。在Redis集群中,每个节点都可以担任主节点(Master)或从节点(Slave)的角色,通过主从复制来实现数据的备份和故障恢复。
主从复制的原理如下:
- 每个Redis集群节点都可以配置为主节点或从节点。主节点负责接收客户端请求并进行数据写入操作,而从节点则负责复制主节点的数据,并在主节点故障时接替主节点的角色,继续提供读写服务。
- 当一个从节点与主节点建立连接后,会向主节点发送复制请求,主节点接受请求后会将自己的数据发送给从节点,并开始进行数据同步。
- 主节点将写入的数据记录到自己的AOF文件或RDB文件中,然后将这些写入操作发送给所有连接的从节点。
- 从节点接收到主节点发送的数据后,会将这些数据写入自己的数据库中,实现与主节点数据的同步。
主从复制模型的优点包括:
- 数据备份:主节点的数据可以被多个从节点复制,确保了数据的备份和冗余,提高了数据的可靠性。
- 故障恢复:当主节点发生故障时,可以自动将一个从节点晋升为主节点,继续提供服务,实现了高可用性。
示例原理解释: 假设我们有一个Redis集群,其中包含3个节点,每个节点都配置为主节点。每个主节点都有2个从节点进行数据复制。当主节点出现故障时,其对应的从节点会被自动晋升为主节点,继续提供服务。这样就保证了集群在部分节点失败的情况下仍然可以继续运行。
 image.png
image.png在Redis集群中,最大节点个数通常取决于集群所使用的哈希槽的数量。每个Redis集群预分配了16384个哈希槽,因此最大节点个数取决于这些哈希槽的分配情况。
理论上,最大节点个数应该是16384,即每个节点负责管理一个哈希槽。但在实际应用中,通常会根据集群的规模和需求来确定节点的数量。如果节点数量过多,可能会增加集群的管理成本,而如果节点数量过少,则可能会影响集群的性能和扩展性。
在实际情况下,常见的Redis集群节点个数通常在几个到几十个之间,具体数量取决于业务需求、数据量、负载情况等因素。
原理解释: 假设我们有一个Redis集群,预分配了16384个哈希槽,如果我们每个节点负责管理一个哈希槽,那么最大节点个数就是16384。例如,如果我们有10个节点,每个节点负责管理1638个哈希槽,这样总共有16384个哈希槽被分配,这是一个常见的配置。
 image.png
image.pngRedis集群采用了哈希槽(Hash Slot)的概念来实现数据的分片和负载均衡。在Redis集群中,一共有16384个哈希槽,每个槽可以存放一个或多个键值对。当需要在Redis集群中放置一个key-value时,Redis会根据CRC16(key)对16384取模得到一个数字,这个数字就是对应的哈希槽的编号,然后将这个key-value放置到对应的哈希槽中。
使用哈希槽的好处在于:
- 哈希槽提供了一种简单而有效的方式来将数据分片存储在多个节点上,实现了数据的分布式存储。
- 由于每个节点只需要维护部分哈希槽上的数据,因此可以充分利用集群中的所有节点,实现了负载均衡。
- 当集群需要扩容或缩容时,只需要对部分哈希槽进行迁移,而不需要迁移所有的数据,因此具有较好的可扩展性。
原理解释: 假设我们有一个Redis集群,包含3个节点,每个节点负责管理部分哈希槽,如下所示:
- 节点1:负责哈希槽0-5461
- 节点2:负责哈希槽5462-10922
- 节点3:负责哈希槽10923-16383
当需要在集群中放置一个key为"mykey"的值时,Redis会对"mykey"进行CRC16计算,并对16384取模,假设得到的结果是8000,则"mykey"会被放置到哈希槽8000上。然后Redis会根据哈希槽的分配规则将"mykey"存储到负责管理哈希槽8000的节点上。
如何在微服务中调用延迟队列:
import org.redisson.Redisson;
import org.redisson.api.RDelayedQueue;
import org.redisson.api.RQueue;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
public class MicroserviceDelayedQueueExample {
public static void main(String[] args) {
// 创建 Redisson 客户端连接
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
// 获取已经存在的延迟队列
RQueue<String> queue = redisson.getQueue("myDelayedQueue");
RDelayedQueue<String> delayedQueue = redisson.getDelayedQueue(queue);
// 在微服务中,监听并处理延迟队列中的元素
new Thread(() -> {
while (true) {
try {
// 阻塞等待队列中的延迟元素
String element = queue.take();
// 处理延迟元素
System.out.println("Received delayed element: " + element);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
// 关闭 Redisson 客户端连接
// redisson.shutdown();
}
}
Redisson 来创建延迟队列
我们首先创建了一个 Redisson 客户端连接,然后通过 Redisson 获取队列对象,并将其转换为延迟队列。接着,我们向延迟队列中添加了一个延迟元素,指定了延迟时间为 10 秒。最后,关闭了 Redisson 客户端连接。
import org.redisson.Redisson;
import org.redisson.api.RDelayedQueue;
import org.redisson.api.RQueue;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
public class RedissonDelayedQueueExample {
public static void main(String[] args) throws InterruptedException {
// 创建 Redisson 客户端连接
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
// 创建延迟队列
RQueue<String> queue = redisson.getQueue("myDelayedQueue");
RDelayedQueue<String> delayedQueue = redisson.getDelayedQueue(queue);
// 添加延迟元素到队列
delayedQueue.offer("Delayed element", 10, TimeUnit.SECONDS);
// 关闭 Redisson 客户端连接
redisson.shutdown();
}
}
 image.png
image.png
import org.redisson.Redisson;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonExample {
public static void main(String[] args) {
// 创建 Redisson 客户端连接
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
// 获取或创建 Redisson 对象
RBucket<String> bucket = redisson.getBucket("myBucket");
// 设置值
bucket.set("Hello, Redisson!");
// 获取值
String value = bucket.get();
System.out.println("Value from Redis: " + value);
// 关闭 Redisson 客户端连接
redisson.shutdown();
}
}
Redis支持的Java客户端主要有 Redisson、Jedis、Lettuce 等。每种客户端都有其自身的特点和优势,可以根据实际需求选择合适的客户端。
-
Redisson:
- Redisson 是一个基于 Redis 客户端和操作框架,提供了分布式和可扩展的 Java 数据结构。
- Redisson 支持各种各样的分布式对象,如分布式集合、分布式锁、分布式队列等,方便开发人员构建分布式应用。
- Redisson 使用 Netty 进行底层网络通信,性能较高,并且提供了丰富的功能和易用的 API。
- 官方推荐使用 Redisson,因为它提供了更多的功能和更好的性能。
Jedis:
- Jedis 是 Redis 官方推荐的 Java 客户端之一,提供了操作 Redis 数据库的各种方法和接口。
- Jedis 使用传统的同步方式进行网络通信,需要注意在高并发环境下可能存在性能瓶颈。
- Jedis 的 API 比较简单易用,但不支持异步操作。
Lettuce:
- Lettuce 是另一个常用的 Redis Java 客户端,相比于 Jedis,Lettuce 使用了异步、基于 Netty 的实现方式,可以提供更高的并发性能。
- Lettuce 支持响应式编程模型,可以与 Spring Reactor、Project Reactor、RxJava 等框架集成,提供异步、非阻塞的操作接口。
- Lettuce 在分布式场景下表现优秀,具有较低的延迟和较高的吞吐量。
 image.png
image.pngRedis常见性能问题及解决方案如下:
- Master不做持久化工作: Master节点在处理请求时不应该负责做任何持久化工作,如RDB快照和AOF日志文件的生成,以免影响其处理性能。可以通过设置
save ""来关闭RDB持久化,或将AOF持久化的频率调整为较低的水平。 - Slave节点开启AOF备份数据: 对于Slave节点,如果数据的重要性要求较高,可以开启AOF持久化方式,将数据备份到磁盘上,以保证数据的持久性。可以设置AOF同步频率为每秒同步一次,以减少数据丢失的可能性。
- Master和Slave在同一局域网内: 为了提高主从复制的速度和连接的稳定性,建议将Master和Slave节点部署在同一个局域网内,减少网络延迟和数据传输的风险。
- 避免在压力很大的主库上增加从库: 当主库面临较大压力时,增加从库可能会导致主库负载进一步增加,影响系统的稳定性和性能。因此,在压力很大的主库上增加从库需要慎重考虑,可以通过升级硬件或优化主库性能来缓解压力。
- 主从复制使用单向链表结构: 主从复制架构应该使用单向链表结构而不是图状结构,即Master节点对应多个Slave节点,而Slave节点不应该相互连接。这样的结构更为稳定,便于解决单点故障问题。例如,如果Master节点挂了,可以立即将一个Slave节点提升为新的Master节点,而其他Slave节点保持连接,不受影响。
原理解释:
采用以上优化措施可以提高Redis的性能和稳定性。例如,将Master节点的持久化工作转移至Slave节点可以减轻Master节点的负载,提高其处理能力;同时,通过在同一局域网内部署Master和Slave节点,可以降低网络延迟,提高主从复制的速度和稳定性。使用单向链表结构的主从复制架构可以更好地管理节点之间的关系,提高系统的可靠性。
 image.png
image.png选择合适的持久化方式需要根据应用的特点、数据的重要性以及性能要求等因素综合考虑。下面是一些选择持久化方式的指导原则:
- 数据重要性: 如果数据的持久性要求很高,不能容忍丢失任何数据,那么应该选择AOF持久化方式,因为AOF会记录每个写操作,数据更加可靠。
- 数据一致性: 如果需要更快速地恢复数据并且可以容忍少量数据的丢失,可以选择RDB持久化方式,因为RDB会在指定时间间隔内对数据进行快照存储,恢复速度比较快。
- 性能影响: 需要考虑持久化方式对性能的影响。RDB持久化方式会在指定时间间隔内进行数据快照,可能会影响Redis的性能;而AOF持久化方式由于是追加写,可能会增加磁盘的IO操作。
- 备份和恢复需求: 如果需要定期备份数据并且能够快速恢复,RDB持久化方式更适合,因为RDB文件体积小,恢复速度快。
 image.png
image.png
# 启用RDB持久化方式(默认配置)
save 900 1
save 300 10
save 60 10000
# 启用AOF持久化方式(默认配置)
appendonly yes
appendfilename "appendonly.aof"
启用了默认配置下的RDB和AOF持久化方式。对于RDB持久化方式,设置了三个保存点,分别表示在900秒内至少发生1个变更、在300秒内至少发生10个变更、在60秒内至少发生10000个变更时进行快照存储。对于AOF持久化方式,设置了开启AOF并指定了AOF文件名。
Redis提供了两种主要的持久化方式:RDB(Redis Database Backup)和AOF(Append Only File)。
-
RDB持久化方式:
- RDB持久化方式是通过在指定的时间间隔或者达到一定条件时对数据进行快照存储的方式。
- 在RDB持久化方式下,Redis会将内存中的数据以快照的形式保存到磁盘上的一个文件中(默认文件名为
dump.rdb)。 - RDB持久化方式的优点是备份数据快速且文件小巧,适合用于数据备份和全量恢复。
- 但缺点是如果Redis意外崩溃,可能会导致最后一次快照之后的数据丢失。
AOF持久化方式:
- AOF持久化方式是通过记录每次对Redis服务器写的操作,将操作日志以追加的方式保存到文件中。
- 当Redis服务器重启时,会重新执行AOF文件中的命令来恢复原始的数据。
- AOF持久化方式的优点是可以确保数据的完整性和持久性,适合用于数据恢复和保护。
- 另外,Redis还提供了AOF文件的后台重写功能,可以优化AOF文件,减小文件大小,提高性能。
混合持久化方式:
- 除了单独使用RDB或AOF持久化方式外,还可以同时开启两种持久化方式。
- 在这种情况下,当Redis重启时,会优先加载AOF文件来恢复数据,因为AOF文件保存的数据集通常比RDB文件保存的数据集更完整。
 image.png
image.png
import redis.clients.jedis.Jedis;
public class SsoExample {
private static final String REDIS_HOST = "localhost";
private static final int REDIS_PORT = 6379;
public static void main(String[] args) {
// 连接到Redis服务器
Jedis jedis = new Jedis(REDIS_HOST, REDIS_PORT);
// 模拟用户登录,生成一个唯一的会话ID
String sessionId = generateSessionId();
// 将会话ID存储到Redis中,并设置过期时间
storeSessionId(jedis, sessionId);
// 模拟用户访问其他服务,检查会话ID是否有效
String userId = getUserIdBySessionId(jedis, sessionId);
if (userId != null) {
System.out.println("User with session ID " + sessionId + " is logged in. User ID: " + userId);
} else {
System.out.println("Invalid session ID: " + sessionId);
}
// 关闭连接
jedis.close();
}
// 生成一个唯一的会话ID(可以使用UUID等方式生成)
private static String generateSessionId() {
return "session_" + System.currentTimeMillis();
}
// 将会话ID存储到Redis中,并设置过期时间
private static void storeSessionId(Jedis jedis, String sessionId) {
String userId = "user123"; // 假设用户ID为user123
jedis.setex(sessionId, 3600, userId); // 设置会话ID并设置过期时间为3600秒(1小时)
}
// 根据会话ID从Redis中获取用户ID
private static String getUserIdBySessionId(Jedis jedis, String sessionId) {
return jedis.get(sessionId);
}
}
import redis.clients.jedis.Jedis;
public class RedisExample {
public static void main(String[] args) {
// 连接到Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// 示例1:Session共享(单点登录)
String sessionId = "session_id_123";
jedis.setex(sessionId, 3600, "user_id_123"); // 设置Session并设置过期时间为3600秒
// 示例2:页面缓存
String pageKey = "page_key_123";
String cachedPage = "<html>...</html>"; // 假设这是页面的缓存内容
jedis.setex(pageKey, 3600, cachedPage); // 设置页面缓存并设置过期时间为3600秒
// 示例3:队列
String queueName = "task_queue";
jedis.lpush(queueName, "task1", "task2", "task3"); // 将任务推送到队列中
// 示例4:排行榜/计数器
String leaderboardKey = "leaderboard";
jedis.zadd(leaderboardKey, 1000, "user1"); // 设置用户积分
long rank = jedis.zrevrank(leaderboardKey, "user1"); // 获取用户排名
System.out.println("User1's rank: " + (rank + 1)); // 输出用户排名(从1开始)
// 示例5:发布/订阅
String channel = "news_channel";
jedis.publish(channel, "Breaking news: New product released!"); // 发布新闻消息到频道
// 关闭连接
jedis.close();
}
}
Redis适用于多种场景,包括但不限于以下几种:
- Session共享(单点登录): Redis可以用作Session共享的存储后端,存储用户的登录状态信息,实现单点登录功能。通过将Session存储在Redis中,可以实现跨多个应用服务器的Session共享,提高用户体验和系统的可扩展性。
- 页面缓存: Redis可以用作页面缓存,存储页面的静态内容或动态生成的数据,减少数据库和后端服务的访问压力,提高网站的访问速度和性能。
- 队列: Redis提供了List数据类型,可以用作队列(Queue)的存储后端,实现异步任务处理、消息队列等功能。通过将任务或消息放入Redis的List中,消费者可以异步地从List中取出任务进行处理,实现解耦和高效的任务处理。
- 排行榜/计数器: Redis提供了Sorted Set和Hash等数据类型,可以用于实现排行榜和计数器功能。通过Sorted Set存储用户的积分或评分信息,并使用相关命令对其进行排名和计数,可以实现实时的排行榜功能。同时,通过Hash存储对象的属性信息和计数器,可以实现计数器功能。
- 发布/订阅: Redis提供了发布/订阅(Pub/Sub)功能,可以用于实现消息发布和订阅的模式。发布者将消息发布到指定的频道,订阅者可以订阅对应的频道,并接收到发布者发布的消息。这种模式适用于实时通信、实时推送等场景。
 image.png
image.png
# 启动第一个主节点(Master1),监听在6379端口
redis-server --port 6379 --cluster-enabled yes --cluster-config-file nodes-6379.conf --cluster-node-timeout 5000 --appendonly yes
# 启动第一个从节点(Slave1),连接到Master1
redis-server --port 6380 --cluster-enabled yes --cluster-config-file nodes-6380.conf --cluster-node-timeout 5000 --appendonly yes --slaveof 127.0.0.1 6379
# 启动第二个主节点(Master2),监听在6381端口
redis-server --port 6381 --cluster-enabled yes --cluster-config-file nodes-6381.conf --cluster-node-timeout 5000 --appendonly yes
# 启动第二个从节点(Slave2),连接到Master2
redis-server --port 6382 --cluster-enabled yes --cluster-config-file nodes-6382.conf --cluster-node-timeout 5000 --appendonly yes --slaveof 127.0.0.1 6381
Redis数据分片模型是一种用于解决存储大量数据的方案,通过将数据分割成多个片段(或称为分片)存储在不同的节点上,从而提高系统的存储能力和吞吐量。每个节点都可以独立地处理自己负责的数据片段,从而实现数据的水平扩展。
在Redis数据分片模型中,可以将每个节点都设计为独立的主节点(Master),每个主节点负责存储和处理一部分数据。为了保证数据的高可用性,每个主节点通常都会有多个从节点(Slave)作为备份,从而实现主备切换和故障转移。
优化内容:
- 数据分片: 将数据按照一定的规则进行分片,每个分片存储在不同的主节点上。例如,可以根据数据的键值进行哈希分片,将相同的键值映射到同一个主节点上,从而实现数据的分布式存储。
- 主从架构: 每个主节点都有多个从节点作为备份,当主节点发生故障时,可以自动将其中一个从节点提升为主节点,从而实现故障转移和高可用性。
- 动态扩展: 当数据量增加时,可以动态地增加新的主节点,从而实现集群的水平扩展。新的主节点可以根据需要分配新的数据分片,并且可以通过复制数据从其他主节点进行数据同步。
 image.png
image.png
# 配置Redis读写分离模型,主节点监听在6379端口,从节点监听在6380端口
# 启动主节点
redis-server --port 6379 --slaveof no one
# 启动从节点
redis-server --port 6380 --slaveof 127.0.0.1 6379
Redis读写分离模型是一种常见的架构设计,通过将读请求和写请求分别发送到不同的节点上,从而提高系统的性能和可用性。通常情况下,写请求发送到主节点(Master),而读请求发送到从节点(Slave)。这种架构的优点在于可以利用多个节点的计算和存储资源,提高系统的并发处理能力和可靠性。
然而,读写分离模型也存在一些缺陷,包括:
- 数据同步延迟: 从节点需要通过主节点进行数据同步,而数据同步是异步的过程,可能会导致从节点的数据与主节点的数据不一致,造成读取到过期数据的情况。
- 存储能力受限: 每个节点都必须保存完整的数据,因此集群的存储能力仍然受限于单个节点的存储能力。当数据量很大时,可能会影响集群的扩展能力。
- 不适合Write-intensive应用: 对于写入频繁的应用,由于所有写请求都需要发送到主节点进行处理,可能会造成主节点的负载过高,影响系统的性能和稳定性。
为了克服这些缺陷,可以采取以下优化策略:
- 增加从节点: 可以增加从节点的数量,以提高读取请求的并发处理能力,并降低读取延迟。通过增加从节点,可以实现读请求的负载均衡,提高系统的整体性能。
- 数据分片: 将数据分成多个片段存储在不同的节点上,从而实现数据的水平扩展。这样可以降低单个节点的存储压力,提高集群的存储能力和扩展性。
- 使用其他缓存方案: 对于写入频繁的应用,可以考虑使用其他缓存方案或者数据库方案,如分布式缓存、分布式数据库等,以满足高并发写入的需求。
 image.png
image.png
# 使用Redis Cluster搭建集群
# 假设我们有6台Redis服务器,分别监听在不同的端口上(7000-7005)
# 启动集群的每个节点
redis-server --port 7000 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --appendonly yes
redis-server --port 7001 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --appendonly yes
redis-server --port 7002 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --appendonly yes
redis-server --port 7003 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --appendonly yes
redis-server --port 7004 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --appendonly yes
redis-server --port 7005 --cluster-enabled yes --cluster-config-file nodes.conf --cluster-node-timeout 5000 --appendonly yes
# 创建集群
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1
在设计Redis集群方案时,可以考虑以下几种方案:
- twemproxy: Twemproxy(又称nutcracker)是一个开源的代理服务器,用于将客户端请求分发到多个后端Redis服务器。它能够提供负载均衡、故障转移等功能,但不支持自动数据迁移和重新平衡。
- Codis: Codis是一个基于Redis的代理层,提供了Twemproxy类似的功能,但具有更多的特性和优化。Codis支持动态添加和删除节点,并且可以自动进行数据迁移和重新平衡,从而实现节点数量的动态调整。
- Redis Cluster: Redis Cluster是Redis官方推出的集群方案,从Redis 3.0版本开始正式支持。Redis Cluster采用了分布式哈希槽的概念,将数据分散存储在多个节点中,并且支持节点间的自动数据迁移、故障转移和重新平衡。它具有内置的高可用性和自动化管理特性,是一个功能丰富、稳定可靠的分布式解决方案。
优化内容: 在选择Redis集群方案时,需要根据具体的业务需求和技术要求进行综合考虑。对于大多数情况下,Redis Cluster是一个很好的选择,因为它是官方推荐的解决方案,具有较好的稳定性和性能。但在一些特殊场景下,如需要更多的定制化和优化时,也可以考虑使用Twemproxy或Codis等方案。
 image.png
image.png
# 在Redis配置文件redis.conf中设置数据淘汰策略为volatile-lru
maxmemory-policy volatile-lru
# 动态修改Redis数据淘汰策略为volatile-ttl
127.0.0.1:6379> CONFIG SET maxmemory-policy volatile-ttl
OK
Redis有以下几种数据淘汰策略:
- volatile-lru(最近最少使用): 从已设置过期时间的数据集中挑选最近最少使用的数据进行淘汰。即在过期的数据中选择最近最少被访问的数据进行淘汰。
- volatile-ttl(即将过期): 从已设置过期时间的数据集中挑选即将过期的数据进行淘汰。即优先淘汰将要过期的数据,以释放空间。
- volatile-random(随机淘汰): 从已设置过期时间的数据集中随机挑选数据进行淘汰。
- allkeys-lru(全局LRU): 从所有数据集中挑选最近最少使用的数据进行淘汰。即在所有数据中选择最近最少被访问的数据进行淘汰。
- allkeys-random(全局随机): 从所有数据集中随机挑选数据进行淘汰。
- noeviction(禁止淘汰): 当内存达到最大使用限制时,Redis不会淘汰数据,而是拒绝写入新数据,直到有足够的空间为止。
 image.png
image.png
import redis.clients.jedis.Jedis;
public class RedisAdvantagesExample {
public static void main(String[] args) {
// 连接到Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// 设置键值对
jedis.set("key", "value");
// 获取键值对
String value = jedis.get("key");
System.out.println("Value for key: " + value);
// 设置过期时间
jedis.expire("key", 60); // 设置key的过期时间为60秒
// 使用主从复制实现数据备份
jedis.set("key1", "value1");
jedis.slaveof("localhost", 6380); // 将当前Redis实例设置为从节点,主节点地址为localhost:6380
// 关闭连接
jedis.close();
}
}
Redis相比memcached具有以下优势:
- 丰富的数据类型支持: Redis支持多种数据类型,如字符串、列表、集合、有序集合和哈希等,而memcached仅支持简单的字符串类型。这使得Redis可以更灵活地处理不同类型的数据,并且可以更方便地进行数据结构化存储和操作。
- 更快的速度: 由于Redis的数据存储在内存中,而memcached也是基于内存的,但Redis在数据结构和算法上的优化使得其性能更高,通常比memcached更快。
- 持久化支持: Redis支持数据的持久化,可以将数据保存到磁盘上,以防止数据丢失。而memcached仅用于缓存,不提供数据持久化功能。
- 数据备份支持: Redis支持主从复制(master-slave)模式,可以实现数据的备份和高可用性。当主节点发生故障时,从节点可以自动接管服务,保证系统的可用性。而memcached没有内置的备份机制。
 image.png
image.png
import redis.clients.jedis.Jedis;
public class RedisThroughputExample {
public static void main(String[] args) {
// 连接到Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// 设置10000个键值对
long startTime = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
jedis.set("key" + i, "value" + i);
}
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
double throughput = 10000.0 / (duration / 1000.0); // 计算吞吐量,单位:键/秒
System.out.println("Redis单点吞吐量:" + throughput + " keys/second");
// 关闭连接
jedis.close();
}
}
在衡量系统性能时,QPS(Queries Per Second,每秒查询数)和TPS(Transactions Per Second,每秒事务数)是两个常用的指标。
- QPS(Queries Per Second): 指的是系统在每秒内所处理的查询请求数量。这些查询请求可以是任何类型的,比如HTTP请求、数据库查询、RPC调用等。对于Web服务来说,QPS表示每秒钟能够响应的HTTP请求的数量。QPS的计算方式通常是通过统计一段时间内的总请求数,然后除以这段时间的长度(秒数)得到。
- TPS(Transactions Per Second): 指的是系统在每秒内所处理的事务数量。事务可以是一次完整的操作或者交易,例如在数据库中的一次读写操作,或者一次完整的业务流程。对于分布式系统,TPS还可以表示系统在每秒内处理的分布式事务数量。
优化内容:
- 使用高效的数据结构和算法: 优化数据结构和算法可以提高Redis的单点吞吐量。例如,合理选择数据类型、使用批量操作、使用合适的数据结构等。
- 垂直扩展和水平扩展: 可以通过增加硬件资源(垂直扩展)或者增加Redis实例数量(水平扩展)来提高Redis的吞吐量。垂直扩展主要是增加单个Redis实例的性能,比如增加CPU核心数、内存大小等;水平扩展则是增加Redis集群的节点数量,通过分布式架构来提高吞吐量。
- 优化网络和IO性能: 优化网络和IO性能可以减少Redis在数据传输和存储上的延迟,进而提高吞吐量。例如,合理配置网络参数、使用高性能的网络设备、使用SSD硬盘等。
- 使用多线程和异步IO: 尽管Redis是单线程的,但可以通过多线程和异步IO等技术来提高并发处理能力,从而提高吞吐量。
 image.png
image.png使用Redis的优势主要包括以下几点:
- 快速的读写性能: Redis数据存储在内存中,相比传统的基于磁盘的数据库系统,Redis具有更快的读写速度。内存访问速度远远快于磁盘访问速度,使得Redis可以实现高性能的数据存储和检索。
- 丰富的数据类型和功能: Redis支持多种数据类型,如字符串、列表、集合、有序集合和哈希等,使得它可以应用于各种不同的场景。此外,Redis还提供了丰富的功能,如事务支持、发布/订阅模式、持久化、数据过期自动删除等,满足了各种不同的需求。
- 原子性操作和事务支持: Redis支持原子性操作,即对数据的更改要么全部执行,要么全部不执行,保证了数据操作的一致性。同时,Redis还提供了事务支持,可以将多个命令打包成一个事务,保证这些命令要么全部执行,要么全部不执行,从而实现复杂操作的原子性。
- 丰富的特性和灵活性: Redis具有丰富的特性和灵活性,可以应用于多种场景。例如,可以将Redis用作缓存,提高访问速度;可以使用Redis的发布/订阅模式实现消息队列,实现实时通信;还可以通过设置键的过期时间,自动删除过期数据,节省存储空间。
原理示例:
Redis之所以快速,主要是因为数据存储在内存中,并且采用了高效的数据结构和算法。例如,Redis的哈希表实现了快速的键值查找操作,时间复杂度为O(1);列表和集合等数据结构的操作也都是基于内存的,因此速度非常快。此外,Redis还使用了单线程模型和非阻塞IO技术,有效地减少了线程切换和IO等待的开销,进一步提高了性能。
import redis.clients.jedis.Jedis;
public class RedisExample {
public static void main(String[] args) {
// 连接到Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// 设置键值对
jedis.set("key", "value");
// 获取键值对
String value = jedis.get("key");
System.out.println("Value for key: " + value);
// 设置过期时间
jedis.expire("key", 60); // 设置key的过期时间为60秒
// 等待60秒后再次获取键值对
try {
Thread.sleep(60000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String expiredValue = jedis.get("key");
System.out.println("Expired value for key: " + expiredValue); // 输出: null,说明key已过期被删除
// 关闭连接
jedis.close();
}
}
 image.png
image.pngRedis之所以选择单线程模型,主要是因为以下几个原因:
- 减少锁竞争: 在多线程环境下,对共享数据的并发访问会导致锁竞争,增加了开销并可能引发死锁等问题。Redis通过单线程避免了这种锁竞争,简化了并发控制,提高了系统的可靠性和稳定性。
- 避免线程切换开销: 多线程模型会频繁进行线程切换,而线程切换本身也是有开销的,特别是在高并发环境下,线程切换开销会变得更加显著。Redis的单线程模型避免了这种开销,使得系统更加高效。
- 简化代码逻辑: 多线程编程相对复杂,涉及线程同步、死锁等问题,需要更复杂的代码逻辑来处理。而单线程模型可以大大简化代码的编写和维护,降低了系统的复杂度。
虽然Redis是单线程模型,但是通过异步非阻塞IO、事件驱动等技术,可以处理大量并发连接而不影响性能。
举个简单的例子来说明Redis的单线程模型原理:
假设有多个客户端同时连接到Redis服务器,并发执行命令。Redis会将这些命令请求放入一个队列中,然后逐个执行。由于Redis是单线程的,每次只能执行一个命令,这样就避免了多线程并发访问共享数据的问题。同时,Redis会通过异步非阻塞IO来处理网络通信,从而可以高效地处理大量并发连接。这种单线程模型在处理大量短时的命令请求时非常高效,同时也避免了多线程带来的复杂性和开销。
 image.png
image.png
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Tuple;
import java.util.List;
import java.util.Set;
public class RedisDataTypesExample {
public static void main(String[] args) {
// 连接到Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// string类型示例
jedis.set("string_key", "Hello Redis!");
String stringValue = jedis.get("string_key");
System.out.println("String value: " + stringValue);
// list类型示例
jedis.lpush("list_key", "item1", "item2", "item3");
List<String> listValues = jedis.lrange("list_key", 0, -1);
System.out.println("List values: " + listValues);
// set类型示例
jedis.sadd("set_key", "member1", "member2", "member3", "member1");
Set<String> setValues = jedis.smembers("set_key");
System.out.println("Set values: " + setValues);
// sorted set类型示例
jedis.zadd("sorted_set_key", 1, "member1");
jedis.zadd("sorted_set_key", 2, "member2");
jedis.zadd("sorted_set_key", 3, "member3");
Set<Tuple> sortedSetValues = jedis.zrangeWithScores("sorted_set_key", 0, -1);
System.out.println("Sorted set values: ");
for (Tuple tuple : sortedSetValues) {
System.out.println(tuple.getElement() + ": " + tuple.getScore());
}
// hash类型示例
jedis.hset("hash_key", "field1", "value1");
jedis.hset("hash_key", "field2", "value2");
jedis.hset("hash_key", "field3", "value3");
List<String> hashValues = jedis.hmget("hash_key", "field1", "field2", "field3");
System.out.println("Hash values: " + hashValues);
// 关闭连接
jedis.close();
}
}
 image.png
image.png
import redis.clients.jedis.Jedis;
public class RedisExample {
public static void main(String[] args) {
// 连接到Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// 缓存示例
jedis.set("key1", "value1");
String value = jedis.get("key1");
System.out.println("Value for key1: " + value);
// 哨兵和复制示例
jedis.set("key2", "value2");
String value2 = jedis.get("key2");
System.out.println("Value for key2: " + value2);
// 事务示例
jedis.watch("key1");
jedis.set("key1", "new_value");
Transaction transaction = jedis.multi();
transaction.set("key2", "new_value2");
transaction.exec();
// Lua脚本示例
String luaScript = "return redis.call('GET', KEYS[1])";
Object result = jedis.eval(luaScript, 1, "key1");
System.out.println("Result of Lua script: " + result);
// 持久化示例(省略)
// 发布/订阅示例
jedis.publish("channel", "hello");
// 分布式锁示例
String lockKey = "resource_lock";
String requestId = UUID.randomUUID().toString();
String lockResult = jedis.set(lockKey, requestId, "NX", "EX", 30);
if ("OK".equals(lockResult)) {
System.out.println("Lock acquired successfully");
// 执行业务逻辑
jedis.del(lockKey);
} else {
System.out.println("Failed to acquire lock");
}
// 关闭连接
jedis.close();
}
}
Redis主要具有以下功能:
- 缓存:作为一种内存数据库,Redis主要用于缓存常用数据,以提高访问速度。
- 键值存储:Redis以键值对的形式存储数据,支持多种数据类型,如字符串、哈希、列表、集合、有序集合等。
- 哨兵和复制:哨兵(Sentinel)用于监控和管理多个Redis实例,实现自动故障转移;复制(Replication)支持将一个Redis服务器的数据复制到多个备份服务器,提高可用性和数据备份。
- 事务:支持事务操作,通过MULTI、EXEC、DISCARD等命令实现对一系列命令的原子性执行。
- Lua脚本:支持使用Lua脚本执行复杂的操作,提高灵活性和执行效率。
- 持久化:支持将内存中的数据持久化到硬盘,保证数据安全性和持久性,主要有RDB快照和AOF日志两种持久化方式。
- 发布/订阅:支持发布/订阅模式,实现消息的发布和订阅,用于构建实时通信、消息队列等应用。
- 分布式锁:通过SETNX、SETEX等命令实现分布式锁,保证多个客户端对共享资源的安全访问。
 image.png
image.png加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview