
Groupby 分组后,如何合并列里的内容?
Pandas 百问百答第 012 篇。
前两天回答了一个群友的问题,感觉有点意思,记录如下:
问题:
有如下图这样的一个 df,想按公司和部门分组
分组后,想把部门人数与运营成本两列的内容合并成一列
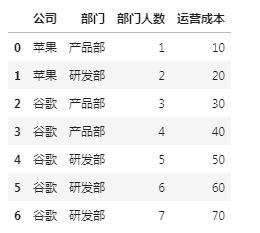 原始 df
原始 df就是把同一个公司、同一个部门的内容合并到一个数据单元中
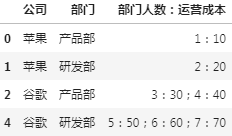 输出的 df
输出的 df
类似这样的需求以前也有人提过,今天就与大家分享一下解决方案:
要实现列的内容合并,需要先把部门人数和运营成本两列的类型从数字改为文本,如果要合并的列类型本身就是文本,则无需转换
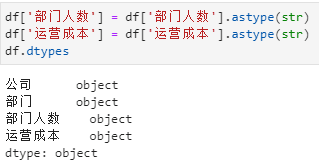
上图中可以看到部门人数和运营成本两列的类型为object,即字符串类型创建临时列,把要合并的列先合并了,分组后,直接操作这个临时列就可以了
新增一列部门人数:运营成本,该列的目的是按公司与部门把每组内部的临时合并一列中的内容组合在一起,这里用的是 transform,不改变原始 df 的行数,只是在原有 df 上增加分组合并的内容
因为上一步用的是 transform,因此处理过的 df 存在重复值,需要去重

上图显示了如何添加合并列,如何分组并合并每组中的内容,可以看到输出的 df 与原始 df 的行数一样都是 6 行,这就是 transform 的特性,虽然分组 groupby,但不是减少行数选择需要输出的列,如公司、部门、部门人数:运营成本,然后去重,就可以得到想要的结果了

补充说明,群友当时还想输出为 JSON 格式,pandas 提供了
to_json方法,可以将 dataframe 输出为 JSON 格式,本篇重点不是这个,就先不介绍了,有兴趣的朋友,可以去官网搜索to_json,自己看下。
下载 完整 ipynb 文件,请继续往下看。。。

第 011 篇:活用 shift,10 秒搞定 500 万
第 010 篇:惊了!大牛换了个思路,就让 Pandas 快了 1000x!
第 009 篇:不会爬,没数据?没关系!3分钟搞定1w+数据,超实用!
第 008 篇:Pandas 还能这么玩儿?这样排序才叫真功夫!
第 007 篇:如何把多个 df 保存至一个 Excel?
第 006 篇:三分钟告诉你 1575119387982 是什么?
第 005 篇:如何选择适合小白的 Python 数据分析书?
第 004 篇:如何安装 Python 数据分析编程环境
第 003 篇:如何用 Anaconda 安装、升级、删除支持库?
第 002 篇:如何配置 Jupyter Notebook?
第 000 篇:1 分钟修改 Jupyter 启动文件夹
要查看源码,请在 python大咖谈后台输入分组合并,下载完整的 ipynb 文件