
PageHelper实现分页原理
场景
PageHelper.startPage(page, pageSize);看到这句话后开始思考为何它可以直接实现分页逻辑,它是怎么实现的?为何在数据库查询的前面加上了这句话就可以实现分页,里面到底发生了什么?
介绍
com.github.pagehelper.PageHelper是一个开源的分页源码工具
<dependency>
<groupId>com.github.pagehelpergroupId>
<artifactId>pagehelper-spring-boot-starterartifactId>
<version>1.2.12version>
dependency>配置文件中也需要配置
# 分页插件配置
pagehelper:
helperDialect: mysql
supportMethodsArguments: true源码分析
分页参数的传递
public static Page startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
Page page = new Page(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
Page oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
setLocalPage(page);
return page;
} 这段代码中第一行是写入参数,第二行和第三行都是null,可以不考虑
主要的代码是这两行:
getLocalPage();
setLocalPage(page);
这里用到了一个ThreadLocal;
ThreadLocal,很多地方叫做线程本地变量,为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
展示到这就看不到其他了,这就很尴尬了,然后继续看jar包中的代码,然后发现了PageInterceptor这个类,分页拦截器,前面已经设置了分页参数在本地变量中,然后就该是调用了,很大可能就是在这个拦截器中进行实现。
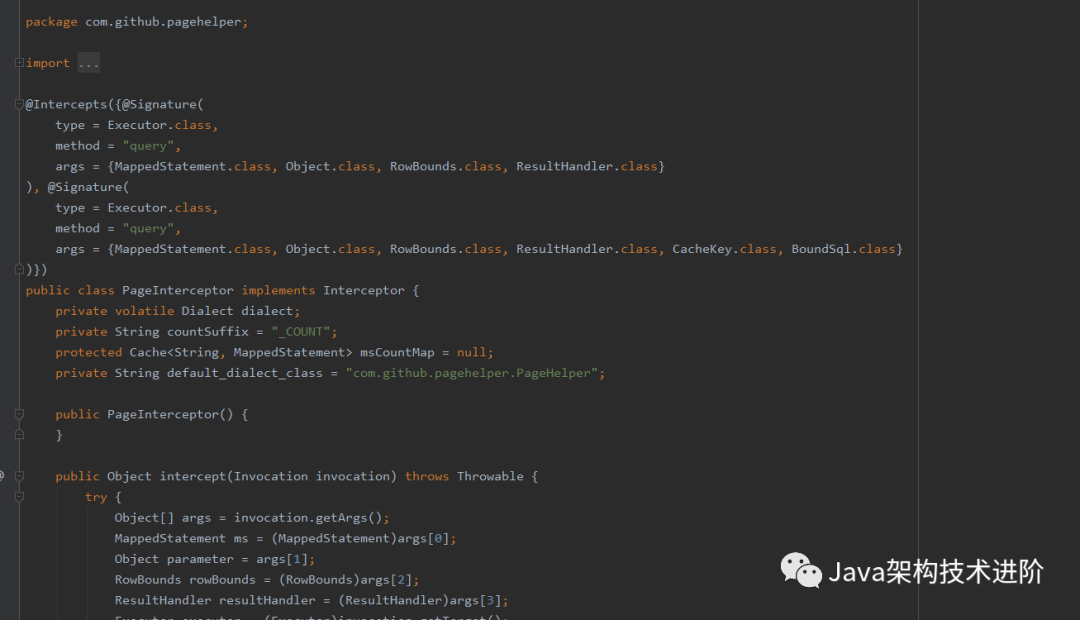
PageInterceptor 实现Mybatis的Interceptor 接口,进行拦截
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement)args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds)args[2];
ResultHandler resultHandler = (ResultHandler)args[3];
Executor executor = (Executor)invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
if (args.length == 4) {
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
cacheKey = (CacheKey)args[4];
boundSql = (BoundSql)args[5];
}
this.checkDialectExists();
List resultList;
if (!this.dialect.skip(ms, parameter, rowBounds)) {
if (this.dialect.beforeCount(ms, parameter, rowBounds)) {
Long count = this.count(executor, ms, parameter, rowBounds, resultHandler, boundSql);
if (!this.dialect.afterCount(count, parameter, rowBounds)) {
Object var12 = this.dialect.afterPage(new ArrayList(), parameter, rowBounds);
return var12;
}
}
resultList = ExecutorUtil.pageQuery(this.dialect, executor, ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
Object var16 = this.dialect.afterPage(resultList, parameter, rowBounds);
return var16;
} finally {
if (this.dialect != null) {
this.dialect.afterAll();
}
}
}然后进入查看ExecutorUtil.pageQuery,看是怎么实现的:
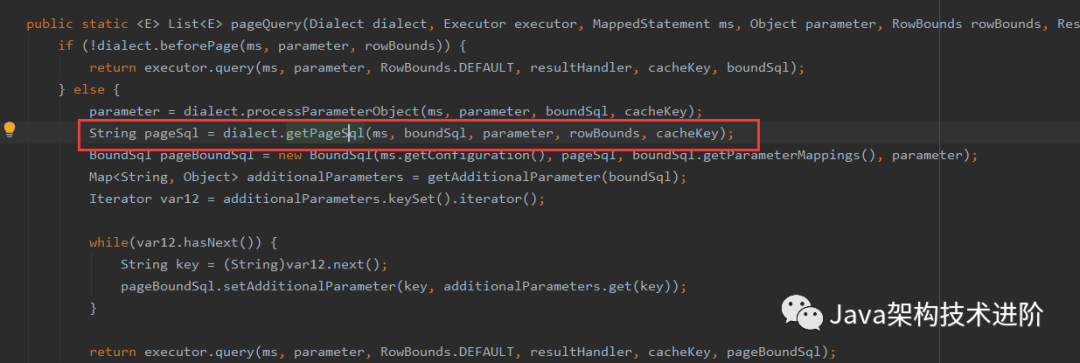
查看分页的sql语句,继续:
public String getPageSql(MappedStatement ms, BoundSql boundSql, Object parameterObject, RowBounds rowBounds, CacheKey pageKey) {
String sql = boundSql.getSql();
Page page = this.getLocalPage();
String orderBy = page.getOrderBy();
if (StringUtil.isNotEmpty(orderBy)) {
pageKey.update(orderBy);
sql = OrderByParser.converToOrderBySql(sql, orderBy);
}
return page.isOrderByOnly() ? sql : this.getPageSql(sql, page, pageKey);
}看到最后的三则表达式后后的getPageSql
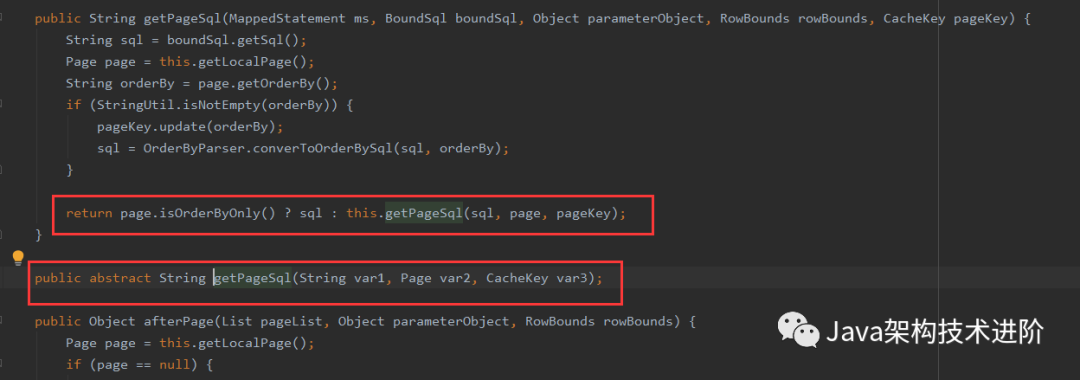
进入到MySqlDialect类的getPageSql方法进行SQL封装,根据page对象信息增加Limit。分页的信息就是这么拼装起来的
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
return sqlBuilder.toString();
}总结
原来PageHelper的分页功能是在我们执行SQL语句之前动态的将SQL语句拼接了分页的语句,从而实现了从数据库中分页获取的过程。
评论