
一文讲清,MySQL中的二级索引
主键索引是InnoDB存储引擎默认给我们创建的一套索引结构,我们表里的数据也是直接放在主键索引里,作为叶子节点的数据页。
但我们在开发的过程中,往往会根据业务需要在不同的字段上建立索引,这些索引就是二级索引,今天我们就给大家讲讲二级所有的原理。
比如,你给name字段加了一个索引,你插入数据的时候,就会重新搞一棵B+树,B+树的叶子节点,也是数据页,但是这个数据页里仅仅放了主键字段和name字段。
叶子节点的数据页的name值,跟主键索引一样的,都是按照大小排序的。同一个数据页里的name字段值都是大于上一个数据页里的name字段值。
name字段的B+树也会构建多层索引页,这个索引页里放的是下一层的页号和最小name字段值。就像这样:
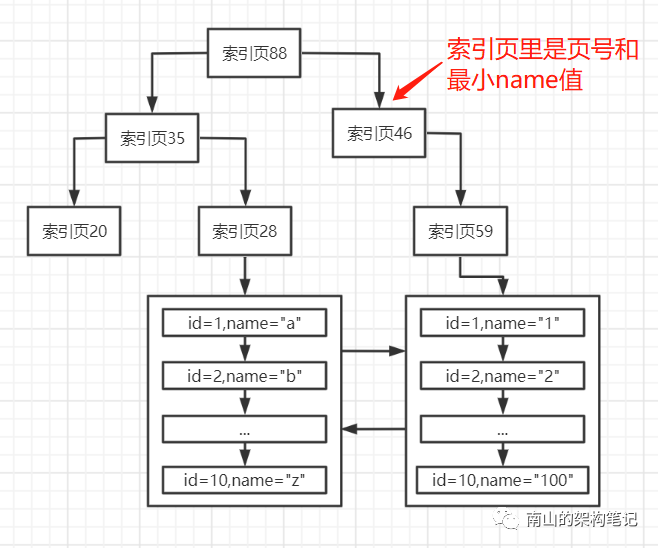
图1 二级索引
假设你要根据name字段来搜索数据,比如:select * from user where name=‘xxx',过程与主键索引一样的。从name索引的根节点开始找,一层一层的向下找,一直找到叶子节点,定位到name字段值对应的主键值。
但此时叶子节点的数据页没有完整所有字段,就需要根据主键到主键索引里去查找,从主键索引的根节点一路找到叶子节点,就可以找到这行数据的所有字段了,这个过程就叫回表。
二级索引,可以对多个字段建立联合索引,比如,name + age + sex
此时联合索引与单个字段的索引原理是一样的,只不过叶子节点的数据页里放的是id + name + age + sex,然后默认按照name排序,name一样就按age排序,age一样就按sex排序。
每个name + age +sex的索引页里,放的就是下层节点的页号和最小的name + age + sex值。当你用name + age + sex搜索的时候,就会走name + age + sex联合索引这棵树,再回表查询。
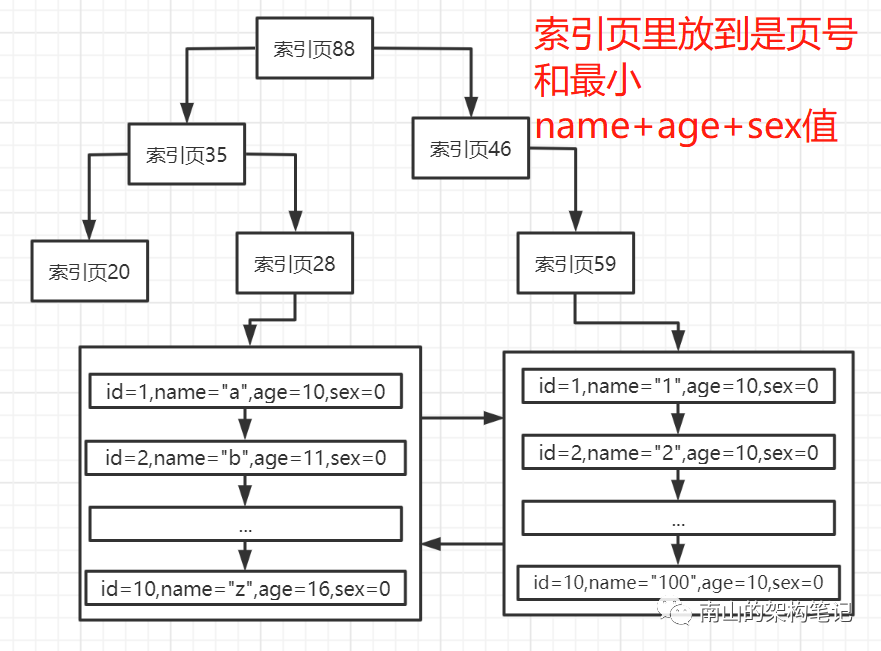
以上就是innoDB二级索引的原理了,有没有感觉也不过如此?
索引的利弊
随着我们不停的在表里插入数据,就会不停的在数据页里插入数据,然后一个数据页放满了就会分裂成多个数据页,这个时候就需要索引页去指向各个数据页。
如果数据页太多了,那么索引页里的数据页指针也就会太多了,索引页也必然会放满的,此时索引页也会分裂成多个,再形成更上层的索引页。
这个过程跟主键索引是一模一样的,所以你如果搞懂了主键索引,二级索引也很简单的。
索引的好处是显而易见的,查找数据的时候不需要全表扫描,性能是很高的。
但索引也有其缺点,如果用的不好,反而对会有副作用。
首先,要创建索引,就要占用存储空间。我们每创建一个索引,MySQL就会搞出一个B+树,每棵B+树都要占用很多的磁盘空间啊,所以搞太多索引,也是很耗费磁盘空间的。
其次,你在进行增删改查的时候,每次都需要维护各个索引的数据有序性,因为每个B+树都要求页内是按照值大小来排序的,页之间也是有序的。所以你不停的增删改查,各个索引的数据页要不停的分裂、增加新的索引页,如果你一个表里搞太多索引,增删改的性能就会比较差
所以综合上面两个原因,我们不建议给一张表搞太多索引的。
联合索引查询原理
之所以要讲联合索引的查询原理,是想带着读者们更清晰的理解索引的工作原理,我们平时设计索引也大多是设计的联合索引。
假如有一个索引KEY(class, name, course),对学生班级、姓名、科目名称建立的联合索引。联合索引的示意图如下:
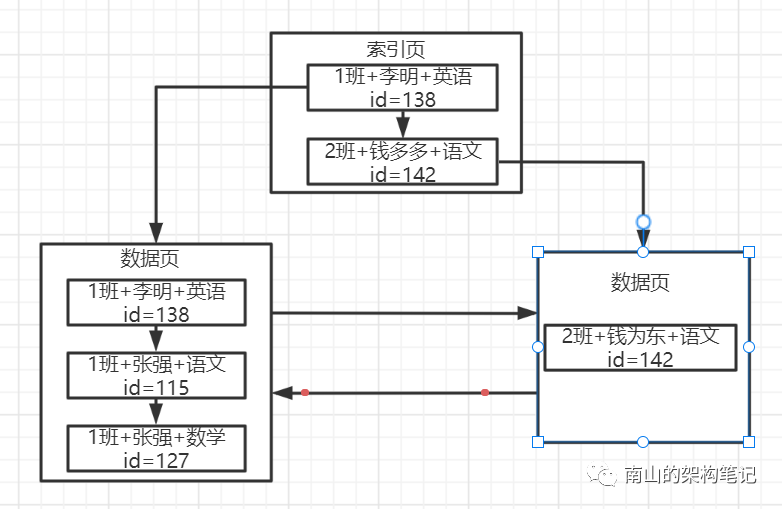
每个数据页都包含了联合索引的三个字段值和主键值,数据页内部也是按照顺序来排序的。
首先按照班级值来排序,如果一样则按照学生姓名来排序,如果一样,则按照科目名称来排序,所以数据页内部都是按照这三个字的值来排序的。
数据页内部与数据页之间也是有序的,数据页内部组成单向链表,数据页之间组成双向链表。
图中索引页分别指向两个数据页,索引页放的是数据页里最小的那个数据值。
假如我们要执行语句:select * from student where class='1班‘ and student_name='张强' and course_name='数学'。
查询时先到索引页里去找,索引页里有多个数据页的最小值记录,此时直接在索引页里基于二分查找方法来找就可以了,先根据班级名来找1班这个值对应的数据页,直接可以定位到所在的数据页。
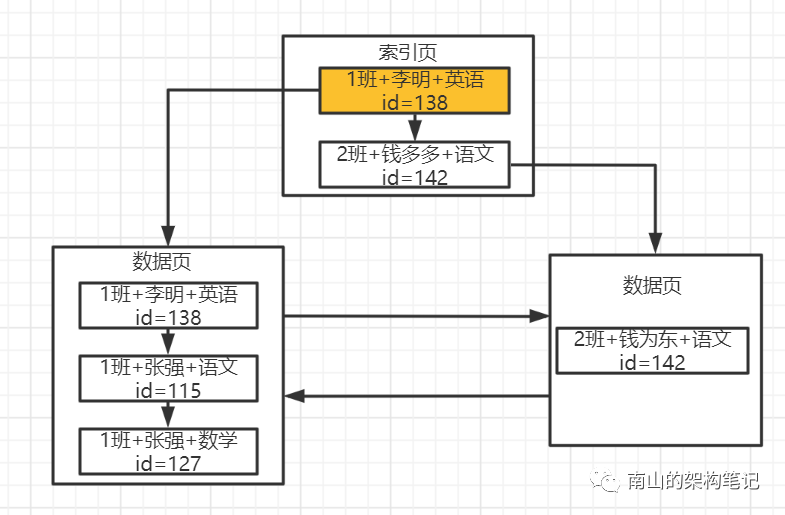
图2 查找到索引页
然后就可以找到索引指向的那个数据页就可以了,在数据页内部是一个单向链表, 你也是基于二分查找就可以了,先按1班这个值查询,你发现有几条数据都是1班,然后按照张强这个学生姓名查找,发现也有多条数据,接着按照科目名称来二分查找。
很快就定位到一条数据了,对应的就是图中的id=127的数据。
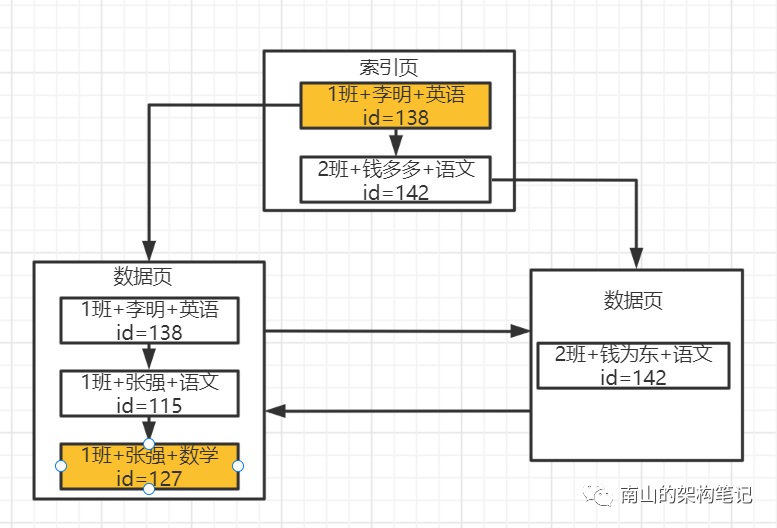
图3 查找到数据
然后根据主键id=127回表查找完整的字段,在主键索引开始二分查找迅速定位到各层级的索引页,再逐步向下定位到id=127的那条数据,就可以拿到所有字段的值了。
上面的过程就是联合索引的查找过程。对于联合索引,就是一次安装各个字段来进行二分查找,先定位到第一个字段对应的值在哪个页,如果第一个字段值一样,就按第二个字段值来查找,以此类推,就找到最终的数据了。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️