
我的Kaggle第一金-Happywhale

老肥今天和大家分享的是最近结束的Kaggle竞赛Happywhale - Whale and Dolphin Identification。
该竞赛为计算机视觉类型比赛,任务是识别鲸鱼和海豚个体,评价指标为MAP@5。在大佬队友们的Carry下,我们队最终位列第三,我也收获了自己第一块Kaggle金牌,下面就和大家一起分享一下我们团队本次比赛的方案。
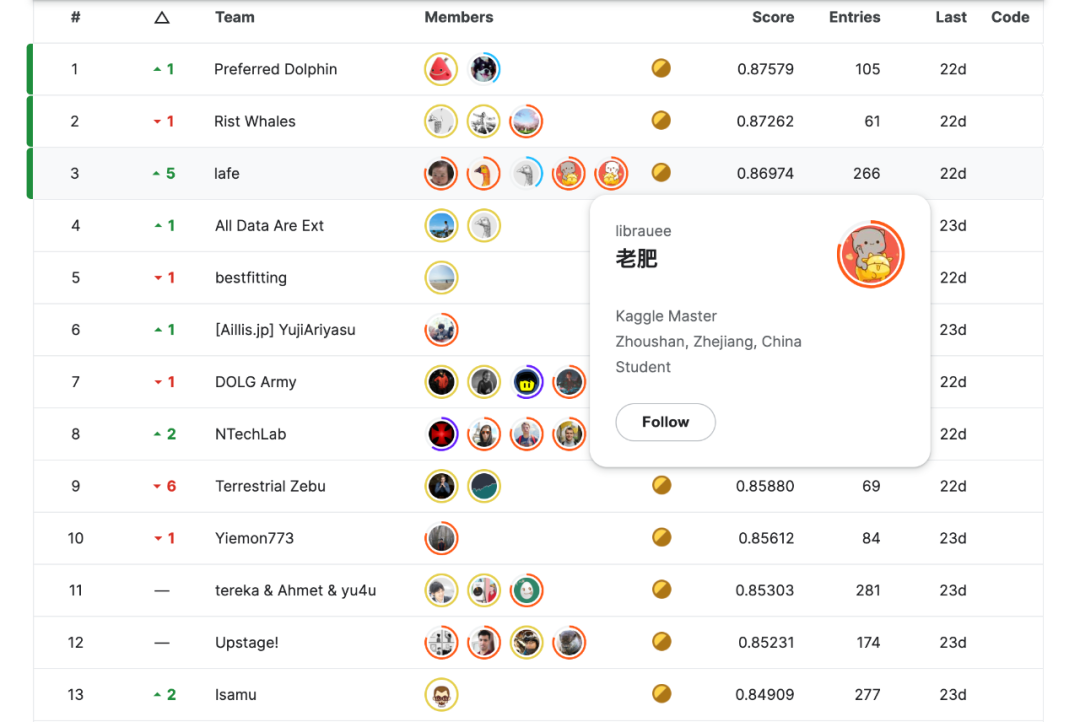
赛题描述
本次比赛的数据包括来自28个不同研究机构的30个不同物种的超过15,000个独特的海洋哺乳动物个体图像。海洋研究人员已经手动识别并给出了个体标注。对于每张图像,我们的任务是预测个体 id(individual_id)。如果在测试数据中有些个体没有在训练数据中观察到,这些个体应该被预测为新个体(new_individual)。
赛题的评价指标为MAP@5:
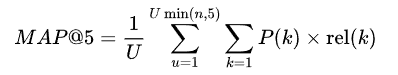
解决方案
我们整体通过“全身”、“鱼鳍”两条路径进行模型的训练和学习,将两条路径学习得到图像的Embedding进行concat融合,最终计算Embedding之间的余弦相似度来获得测试集的预测结果。
首先是图像预处理的部分,这一部分相当关键,是本次比赛中重大的上分点之一。通过观察数据集我们可以发现存在大量目标占整个图像比例较小的情况,我们需要提取图像的显著区域能有助于模型学习,具体方案设计如下图所示:
首先标注5000余张鲸鱼和海豚的身体图片,使用
yolov5训练显著目标检测, 每张图片只检测显著目标, (参数设置mosaic=0, degrees=0, mixup=0)。在训练集上推理, 将(num_box==0, num_box>1, score_box<0.4)的异常图片重新标注后重新训练检测器。当检测到的鱼身大于1个时,通过相同类别的其他图片进行
对比标注。在测试集上推理, 对于(num_box>1, num_box==0)的图片调整检测器的score阈值和推理阶段的分辨率(使用不同分辨率推理同一张图), 异常图片上会存在多个box, 再将box crop后与训练集特征进行
余弦度量, 如果距离大于0.5则选择距离最近的box为该图的显著目标, 如果距离小于0.5选择检测得分较高的box。最终得到每一张图片对应一个box。
在图像显著区域中我们还可以进一步提取鱼鳍区域来更进一步的提升模型的性能,我们只使用包含鱼鳍的图像进行训练并且推理包含鱼鳍的图像,当图像不包含鱼鳍时,我们使用全身图像推理对测试集结果进行填充。具体检测的方法可以参照【1】这篇帖子。
接下来是模型训练的部分,模型训练使用了在小模型例如efficientnetb5、小分辨率512 * 512上进行Trick的调试选择的方法以加快迭代速度,最终将系列Trick也就是涨分点使用到最终提交的大模型efficientnet_b7、eca_nfnet_l2以及大分辨率768 * 768以及1024 * 1024上。
在训练过程中,我们发现训练集的损失很低,同时验证机的损失要高很多。为了缓解过拟合的现象,我们从数据增强和特征空间的角度进行优化。
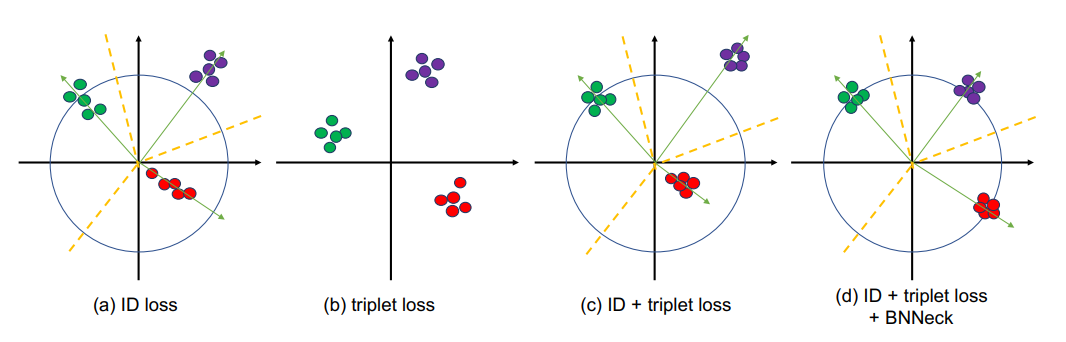
特征空间角度:backbone -> gempooling【2】 -> bnn-neck【3】 -> arcface(s=30, m=0.3) or adaface(m=0.3, h=0.333,s=30, t_alpha=0.01。由于arcface只度量余弦角度, 特征空间没有进行距离约束, 利用bnneck可以对特征空间进行整形, 并且增加了特征区分的难度, 可以缓解过拟合问题(直接的表现便是涨点)。至于adaface,在图像质量高的时候,让损失函数更关注于hard samples,而当图像质量低的时候,不再过度强调hard samples,同样提升了性能。
数据增强角度:通过对数据集进行分析,我们发现许多个体差异很大程度上依赖于纹理差异。因此,我们认为锐化和灰度缩放可以使模型增加纹理的影响,减少对颜色的依赖。同时使用MixUp可以增加模型学习的难度,提升模型的泛化能力。
鱼鳍部分的训练和鱼身部分的训练有所不同,未使用MixUp或是CutMix等混合增强,采用的Head分别为arcface与curricularface,backbone为efficientnet_b7模型,分辨率大小为512 * 512,具体可以参考代码【4】,鱼身与鱼鳍训练的Trick具有差异性,在鱼身数据上work的在鱼鳍上并不一定work,而两者相结合则可以带来较好的收益。
在训练迭代的过程中,我们也使用了伪标签的技术,该技术是本次竞赛的另一个重大上分点。生成伪标签的方法是使用不同的相似性阈值来生成测试集的预测结果,并将top1预测为new_id的样本去除。同时由于伪标签集和验证集之间存在某个交集,我们计算伪标签集和验证集的相似度,并删除具有高相似度得分的验证集的图像,以确保离线得分与在线得分保持一致。
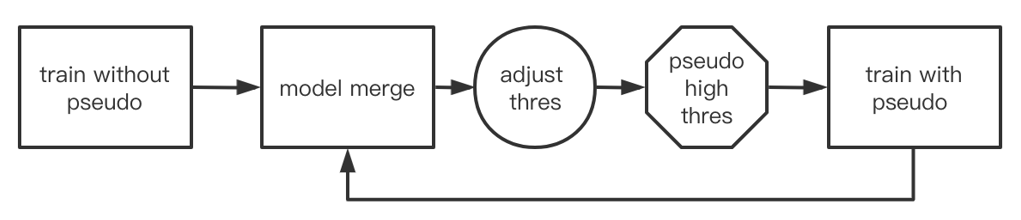
step 1: 鱼身的数据被用来训练模型。在进行多模型集成后,在测试集上获得具有较高阈值的伪标签。
step 2: 我们进一步使用step 1中的伪标签来辅助训练鱼鳍模型,然后将鱼鳍模型与鱼身模型进行集成,接着使用新的集成模型通过设置一个相对较低的阈值来获得新的伪标签以进行下一步迭代。
最后是模型集成的部分,因为我们将数据分为十折进行训练,当使用两个不同折的模型进行集成时会出现标签泄露的问题(举个简单例子,fold1的模型训练看见过 [0, 2, 3, 4, 5, 6, 7, 8, 9] 折的数据标签,其将1折的数据当作验证集,而fold2的模型训练看见过 [0, 1, 3, 4, 5, 6, 7, 8, 9] 折的数据标签,当fold1和fold2模型用于集成时, 将fold1或是2来当作验证集会发生泄露),而相同fold的模型之间集成则不会存在该问题(因为所使用训练和验证数据之间没有交叉),并且我们还可以通过贝叶斯优化的方法对每个模型输出Embdding进行加权以获得更高的线下验证分数。
那么如何对不同折之间的模型进行集成呢,我们通过对不同折生成的提交文件中的推理结果进行重新排序,通过对不同预测位置(top1-5)、不同fold的提交文件赋予不同的权值生成排序结果,具体可以参考【5】。
最后我们所采用的模型为鱼身的b6、b7与nfnet_l2,鱼鳍的两个b7,将这些模型的同折的Embedding进行加权拼接,将这些模型的[0、1、2、3]fold(十折中的前四折)生成的预测结果进行重排得到最终的提交结果。
不得不说,本次比赛收获满满,感谢队友之间的通力合作!他们也在国内国外的社区上分享了方案【6、7、8】,大家也可以进一步探索交流。
参考资料
https://www.kaggle.com/competitions/happy-whale-and-dolphin/discussion/310153 https://arxiv.org/abs/1711.02512 https://arxiv.org/abs/1903.07071 https://www.kaggle.com/code/librauee/train-newpse-backfins-b7-512-curri-fold1 https://www.kaggle.com/code/yamsam/simple-ensemble-of-public-best-kernels https://zhuanlan.zhihu.com/p/501387749 https://www.kaggle.com/competitions/happy-whale-and-dolphin/discussion/319896 https://www.kaggle.com/competitions/happy-whale-and-dolphin/discussion/319789
——END—— 觉得有用的话,就关注一下吧,感谢支持!
