
开源 SPL 优化报表应用应对没完没了
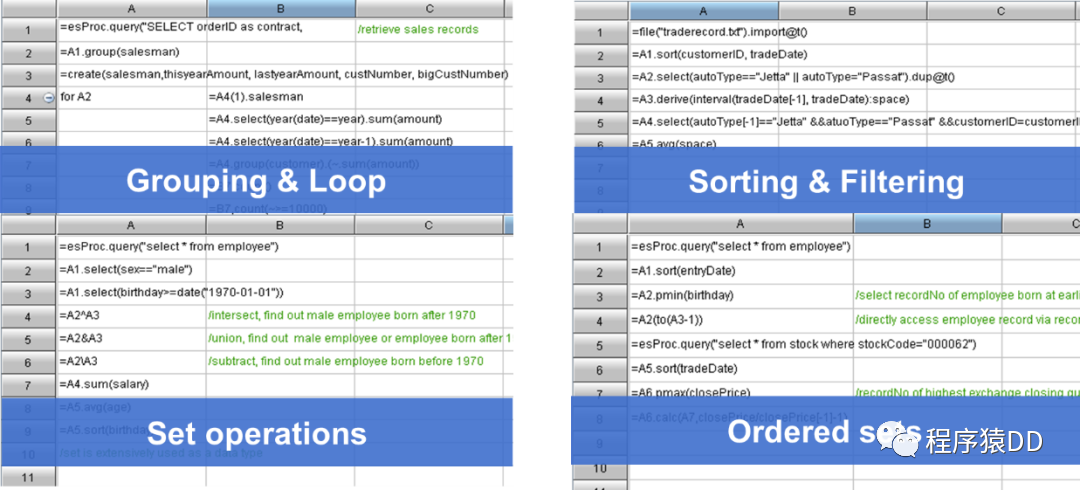
降低报表的开发工作量
select code,max(risenum)-1 maxRiseDays from( select code,count(1) risenum from(select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays from(selectcode,ddate,case when price>=lag(price) over(partition by code order by ddate)then 0 else 1 end changeSignfrom stock_record))group by code,unRiseDays)group by codehaving max(risenum) > 5
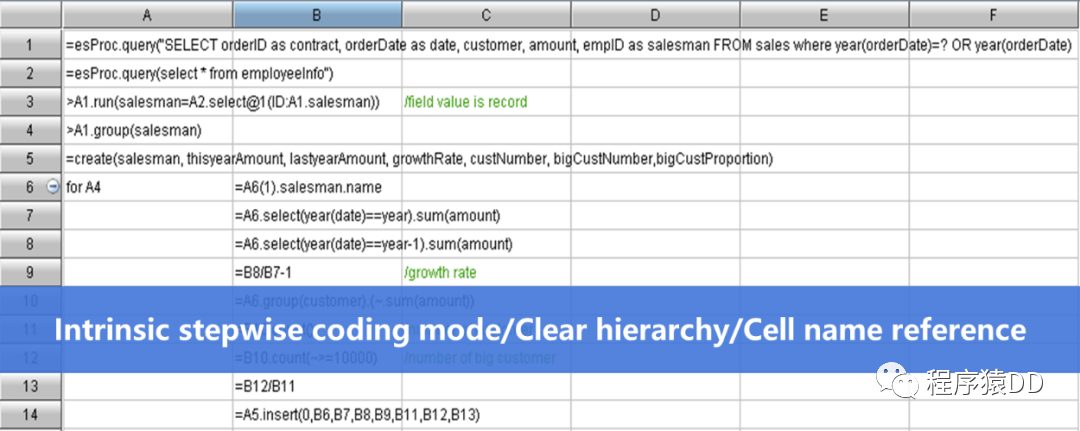
而同样的计算用 SPL 则要简单很多:
| A | ||
| 1 | =connect@l("orcl").query@x("select * from stock_record order by ddate") | |
| 2 | =A1.group(code) | |
| 3 | =A2.new(code,~.group@i(price | 计算每只股票的连续上涨天数 |
| 4 | =A3.select(maxrisedays>=5) | 选出符合条件的记录 |
SPL 还提供了简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…
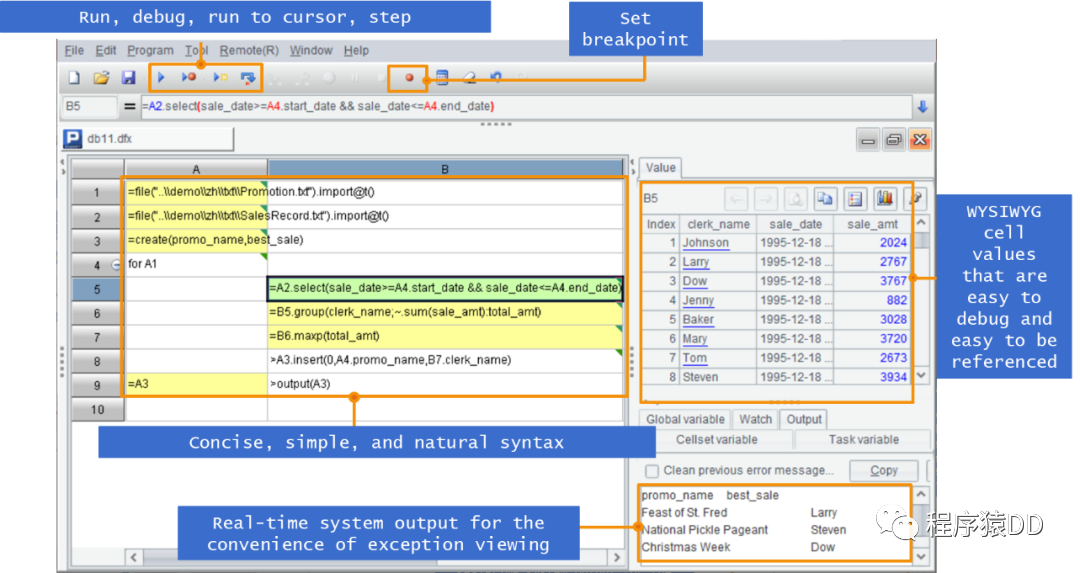
改善存储过程和 JAVA 做数据准备的缺点
减少数据库中的中间表
实现报表的热切换
解决多样性数据源

提升报表性能
这个运算复杂度是平方级的,数据量小的时候没什么影响,数据量稍大时性能就会急剧下降。
低成本应对没完没了
附录
我们怎样把 A 石油集团油井分析报表开发周期缩短 10+ 倍
我们怎样把 B 石化集团多维度多层级叉乘统计报表开发周期缩短 120 倍
我们怎样把 D 制造企业库龄计算报表开发周期缩短 7.5 倍

评论