
使用 golang gopacket 实现进程级流量监控
如何分析某服务器上哪个进程的流量多 ? 猜不少人都有类似的需求, 社区里已经有 c 写的 nethogs 工具, 该工具很方便的获取流量较高的 TOP N 进程列表。
既然有 nethogs 工具,为什么还需要用 goalng 来实现一遍 ?主要是 nethogs 不够灵活,没有开放接口供其他程序调用。对的,我们现在就需要这类接口。当然,不是每个公司都有这类需求,大家通常都是当流量异常时,登上去分析下异常流量。
代码
项目名为 go-netflow, 代码已经提交到 github。
地址为 https://github.com/rfyiamcool/go-netflow,有兴趣的可以看看,记得点 star 哈。
从设计到流量测试完毕,用了差不多 两天半 的时间。go-netflow 的接口方面还算完善,最少满足了我们容器云团队及 sre 的需求。但他的 cli 终端部分很是简陋,有兴趣的同学可以帮忙提交 pr。
实现
像 promethues, openfalcon 这类开源监控软件,通过 /proc/net/snmp 和 /proc/net/netstat 获取连接和流量信息。
/proc/net/snmp文件只是提供了主机各层的IP、ICMP、ICMPMsg、TCP、UDP详细数据/proc/net/netstat文件提供了主机的收发包数、收包字节数据。
这两个文件只能看到主机级别的信息,没法实现进程级别的流量采集。
但是我们可以从其他路子来实现细粒度的进程级别的流量监控。😁
通过 /proc/net/tcp ,/proc/net/udp 文件,我们可以拿到 tcp及udp 的四元组和 inode 信息。通过 /proc/{pid}/fd/ 可以拿到 pid 及 socket inode文件描述符的映射关系。
那么怎么流量从哪里获取?抓包,类似 tcpdump 这类使用 pcap 来抓包。
这里详细的说下,基于 pcap 的进程流量统计的实现.
- 启动阶段扫描
/proc/net/tcp和/proc/{pid}/fd/{socket inode}。构建三个缓存hashmap
- connInodesMap, 定义了 tcp 连接和 inode 号 的对应关系。
- inodePidMap, 定义了 inode 和 进程 pid 号 的对应关系。
- processMap,存放了进程的基本信息, 最近15秒的流量缓存及流量统计结果。
地址:源端口_目标地址:目标端口从 connInodeMap 里获取 inode 索引号, 再通过 inode 到 inodePidMap 获取 pid 进程号,再用 pid 到 processMap 里获取进程对象,然后进行进出流量的累加计算。上面说的正常的流程,如果在 pcap 捕获流量时期,有新的连接和新的进程创建了,那么就会拿不到对应的 inode 或者 pid 信息。所以,需要定时重新扫描那几个元数据文件,然后对这几个缓存 map 进行增减处理。把暂未找到进程的 packet ,放到一个 ringbuffer 缓存里,每次定时扫描完 /proc 元数据后,再尝试计算 ringbuffer 里的缓存。
注意的几个点:
/proc 的那个几个元数据不能使用 inotify 来监听,只能是定时扫描或者利用你通知来被动更新。udp也是同理,这里就不复述了。
如何判断是进出流量?
如果 src.ip 是本地的ip地址,那么就是出流量,src.ip 不是本地ip地址,那么肯定就是进流量了。go-netflow 在启动阶段就需要获取本地的ip地址列表。
如何监听多个网卡
google golang gopacket 库默认只能 openlive 一个网卡,没找到可以 openlive 多个设备网卡的相关方法。平时我们用 tcpdump 抓包时,可以通过 -i any 匹配多个网卡。那么在 gopacket 如何实现多个设备网卡监听?实例化多个 openlive 实例不就行了,我居然还还提了 issue 询问该问题,当然没人回复我了。
如何限定 cpu/mem 占用资源
tcpdump 在大流量网关下是相当消耗 cpu 资源的,netflow 里做了一些简单的限制,不是同步处理全量的包,而是扔到队列中异步处理,如果队列满了,则直接丢弃。通过简单的 atomic 计数器来进行限制处理的包数。
但难免还是有意外造成 cpu 资源大量占用,如何限定 cpu 资源?
这里直接使用 linux cgroups 来限定cpu及mem资源,new netflow 对象时可以传入 cgroups 的参数。cpu为核数,可以为 0.5 ,也就是仅占用一个 cpu core 的 50% 资源。mem 是限定的内存量,单位是 MB,默认为0,及为不限制。
WithLimitCgroup(cpu float64, mem int)
写入pcap文件
netflow支持pcap文件的写入,后面可通过 tcpdump 或 wireshark 来读取 netflow 写入的pcap文件。
超时机制
netflow 限定了默认超时时间为 5 分钟,当超过 5 分钟后会关闭所有设备的监听。这么做主要为了避免长时间运行忘了关闭,尤其是通过 netflow 接口来进行抓包的。
效果
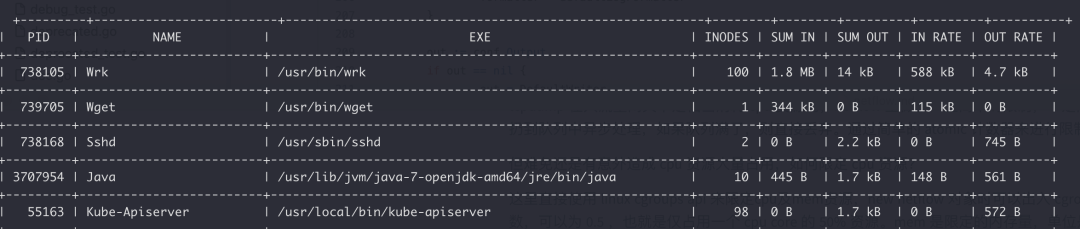 img
img优化
go-netflow 还是有一些优化空间的, 内存方面可以针对一些对象做复用, 使用 sync.pool 减少新对象的创建。CPU的开销主要在 google gopacket 调用上, cgo 的调用一点也不便宜, 暂时没有好的方法来优化。另外, 进程的流量监控无需太细致,粗粒度采样足够了。
大家觉得文章对你有些作用!如果想赏钱,可以用微信扫描下面的二维码,感谢!
另外再次标注博客原地址 xiaorui.cc
