
带你全面剖析python自然语言处理(TF-IDF和TextRank)
前面已经做了两期python自然语言处理的相关文章,跳转连接:

🚩TF-IDF和TextRank
from jieba.analyse import *with open('sample.txt','r') as f: # 'r'是只读,a为覆盖,w为覆盖写入data = f.read() # 读取sample.txt
⭐️TF-IDF

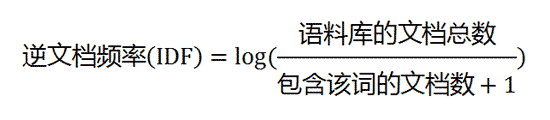
# TF-IDFfor keyword, weight in extract_tags(data, topK=10, withWeight=True): # 输出10个关键词print('%s %s' % (keyword, weight))
⭐️TextRank
# TextRankfor keyword, weight in textrank(data, withWeight=True):print('%s %s' % (keyword, weight))
⭐️基于 TF-IDF 算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
import syssys.path.append('../')import jiebaimport jieba.analysefrom optparse import OptionParserUSAGE = "usage: python extract_tags.py [file name] -k [top k]"parser = OptionParser(USAGE)parser.add_option("-k", dest="topK")opt, args = parser.parse_args()if len(args) < 1:print(USAGE)sys.exit(1)file_name = args[0]if opt.topK is None:topK = 10else:topK = int(opt.topK)content = open(file_name, 'rb').read()tags = jieba.analyse.extract_tags(content, topK=topK)print(",".join(tags))
from sklearn.feature_extraction.text import TfidfVectorizercorpus = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?',]vectorizer = TfidfVectorizer()tdm = vectorizer.fit_transform(corpus)space = vectorizer.vocabulary_print(space)
⭐️基于 TextRank 算法的关键词抽取
from __future__ import unicode_literalsimport syssys.path.append("../")import jiebaimport jieba.possegimport jieba.analyseprint('='*40)print('1. 分词')print('-'*40)seg_list = jieba.cut("我来到北京清华大学", cut_all=True)print("Full Mode: " + "/ ".join(seg_list)) # 全模式seg_list = jieba.cut("我来到北京清华大学", cut_all=False)print("Default Mode: " + "/ ".join(seg_list)) # 默认模式seg_list = jieba.cut("他来到了网易杭研大厦")print(", ".join(seg_list))seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式print(", ".join(seg_list))print('='*40)print('2. 添加自定义词典/调整词典')print('-'*40)print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))#如果/放到/post/中将/出错/。print(jieba.suggest_freq(('中', '将'), True))#494print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))#如果/放到/post/中/将/出错/。print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))#「/台/中/」/正确/应该/不会/被/切开print(jieba.suggest_freq('台中', True))#69print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))#「/台中/」/正确/应该/不会/被/切开print('='*40)print('3. 关键词提取')print('-'*40)print(' TF-IDF')print('-'*40)s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"for x, w in jieba.analyse.extract_tags(s, withWeight=True):print('%s %s' % (x, w))print('-'*40)print(' TextRank')print('-'*40)for x, w in jieba.analyse.textrank(s, withWeight=True):print('%s %s' % (x, w))print('='*40)print('4. 词性标注')print('-'*40)words = jieba.posseg.cut("我爱北京天安门")for word, flag in words:print('%s %s' % (word, flag))print('='*40)print('6. Tokenize: 返回词语在原文的起止位置')print('-'*40)print(' 默认模式')print('-'*40)result = jieba.tokenize('永和服装饰品有限公司')for tk in result:print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))print('-'*40)print(' 搜索模式')print('-'*40)result = jieba.tokenize('永和服装饰品有限公司', mode='search')for tk in result:print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
========================================1. 分词----------------------------------------Building prefix dict from the default dictionary ...Dumping model to file cache C:\Users\Y\AppData\Local\Temp\jieba.cacheLoading model cost 2.162 seconds.Prefix dict has been built successfully.Full Mode: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学Default Mode: 我/ 来到/ 北京/ 清华大学他, 来到, 了, 网易, 杭研, 大厦小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, ,, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造========================================2. 添加自定义词典/调整词典----------------------------------------如果/放到/post/中将/出错/。494如果/放到/post/中/将/出错/。「/台/中/」/正确/应该/不会/被/切开69「/台中/」/正确/应该/不会/被/切开========================================3. 关键词提取----------------------------------------TF-IDF----------------------------------------欧亚 0.7300142700289363吉林 0.659038184373617置业 0.4887134522112766万元 0.3392722481859574增资 0.335824019852340454.3 0.254356755380851067000 0.254356755380851062013 0.25435675538085106139.13 0.25435675538085106实现 0.19900979900382978综合体 0.19480309624702127经营范围 0.19389757253595744亿元 0.1914421623587234在建 0.17541884768425534全资 0.17180164988510638注册资本 0.1712441526百货 0.16734460041382979零售 0.1475057117057447子公司 0.14596045237787234营业 0.13920178509021275----------------------------------------TextRank----------------------------------------吉林 1.0欧亚 0.9966893354178172置业 0.6434360313092776实现 0.5898606692859626收入 0.43677859947991454增资 0.4099900531283276子公司 0.35678295947672795城市 0.34971383667403655商业 0.34817220716026936业务 0.3092230992619838在建 0.3077929164033088营业 0.3035777049319588全资 0.303540981053475综合体 0.29580869172394825注册资本 0.29000519464085045有限公司 0.2807830798576574零售 0.27883620861218145百货 0.2781657628445476开发 0.2693488779295851经营范围 0.2642762173558316========================================4. 词性标注----------------------------------------我 r爱 v北京 ns天安门 ns========================================6. Tokenize: 返回词语在原文的起止位置----------------------------------------默认模式----------------------------------------word 永和 start: 0 end:2word 服装 start: 2 end:4word 饰品 start: 4 end:6word 有限公司 start: 6 end:10----------------------------------------搜索模式----------------------------------------word 永和 start: 0 end:2word 服装 start: 2 end:4word 饰品 start: 4 end:6word 有限 start: 6 end:8word 公司 start: 8 end:10word 有限公司 start: 6 end:10>>>
🚩TF-IDF结合余弦相似度做相似度分析
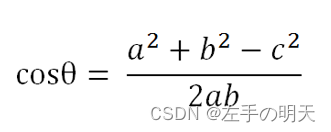
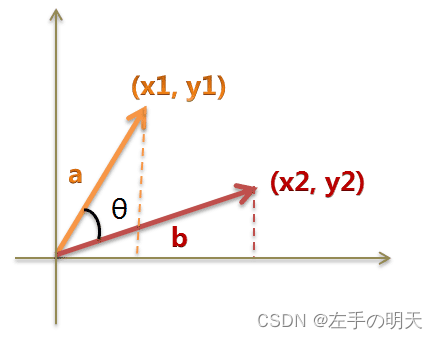
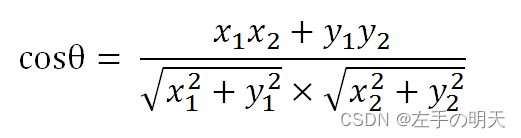
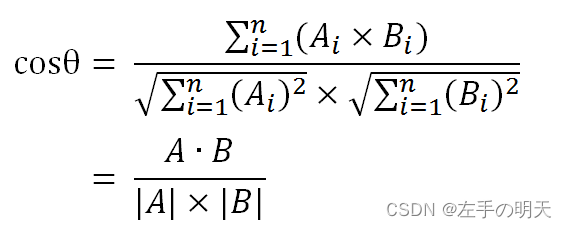
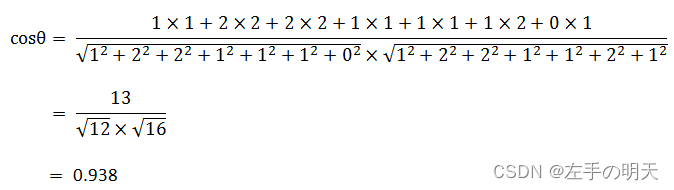
def cos_sim(a,b):
"""
计算a,b向量的余弦相似度
@param a: 1*m的向量
@param b: n*m的矩阵
@return: 1*n的值,每个样本的bi与a的余弦相似度
"""
cos_result = np.dot(a, b.T) / np.sqrt(np.sum(b ** 2, axis=1)) / np.sqrt(np.dot(a, a.T))
return cos_result
import numpy as np
def cosine_similarity(x,y):
num = x.dot(y.T)
denom = np.linalg.norm(x) * np.linalg.norm(y)
return num / denom
cosine_similarity(np.array([0,1,2,3,4]),np.array([5,6,7,8,9]))#0.9146591207600472cosine_similarity(np.array([1,1]),np.array([2,2]))#0.9999999999999998cosine_similarity(np.array([0,1]),np.array([1,0]))#0.0
推荐阅读
(点击标题可跳转阅读)
【初学不要怕】教你全方位理解python函数及其使用(包括lambda函数和递归函数详解系列)
【加解密算法实现】全面剖析RSA加解密算法(附完整C/Python源码)
老铁,三连支持一下,好吗?↓↓↓



点分享

点点赞

点在看
评论