
炼丹神器|python的开源库:Shapash

极市导读
一个python的开源库,可以让炼丹师们在炼丹过程中理解自己为什么能练出"好"丹。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
最近时晴又发现了个炼丹神器Shapash,就迫不及待的要推荐给大家.这是个python的开源库,可以让炼丹师们在炼丹过程中理解自己为什么能练出"好"丹.相信诸位炼丹师和我一样,不仅追求一个好的模型,同时也追究模型的可解释性,废话不多说,我们看看"太阳女神"如何解释我们的模型吧.
shapash适用于很多模型:Catboost,Xgboost,LightGBM,Sklearn Ensemble等.可以简单的用pip进行安装:
$pip install shapash
我们用一个实际的例子来说明shapash的用法.我们先训练一个回归模型,用于预测房价.
数据下载链接:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
先用shapash读入数据:
import pandas as pd
from shapash.data.data_loader import data_loading
# house_dict里面是特征名到特征含义的映射
house_df, house_dict = data_loading('house_prices')
y_df=house_df['SalePrice'].to_frame()
X_df=house_df[house_df.columns.difference(['SalePrice'])]
看下数据如下:
对类别特征进行编码:
from category_encoders import OrdinalEncoder
categorical_features = [col for col in X_df.columns if X_df[col].dtype == 'object']
encoder = OrdinalEncoder(cols=categorical_features).fit(X_df)
X_df=encoder.transform(X_df)
我们可以看到,所有特征都变成数值了:
找个任意的回归模型训练,这里我用随机森林:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
Xtrain, Xtest, ytrain, ytest = train_test_split(X_df, y_df, train_size=0.75)
reg = RandomForestRegressor(n_estimators=200, min_samples_leaf=2).fit(Xtrain,ytrain)
#预估测试集
y_pred = pd.DataFrame(reg.predict(Xtest), columns=['pred'], index=Xtest.index)
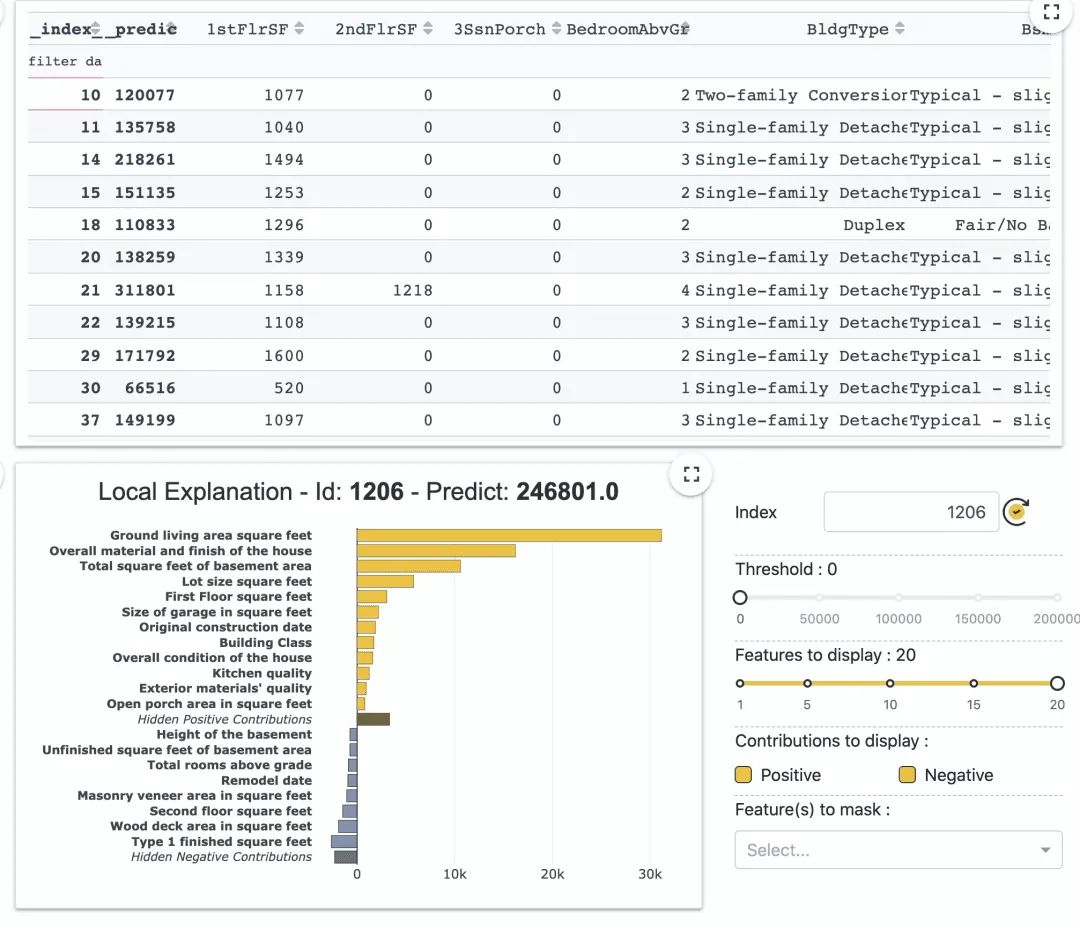
这里我们不探讨该模型效果,直接看看如何用"太阳女神"解释该模型:
from shapash.explainer.smart_explainer import SmartExplainer
xpl = SmartExplainer(features_dict=house_dict) # Optional parameter
xpl.compile(
x=Xtest,
model=reg,
preprocessing=encoder,# Optional: use inverse_transform method
y_pred=y_pred # Optional
)
然后使用一行代码,就可以解释模型了:
app = xpl.run_app()
我们可以看到特征重要性:
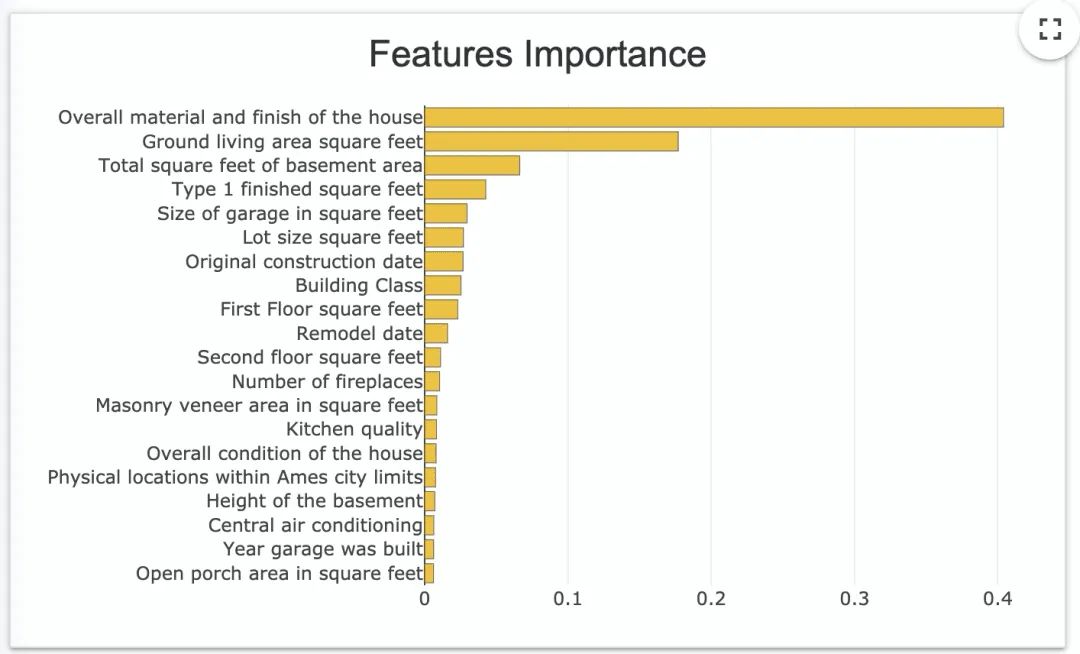
已经特征多大程度影响预估:

当我们选择特征重要性最低的特征时,可以发现该特征影响的样本较少,影响值的范围也小了很多(-2000~2000).
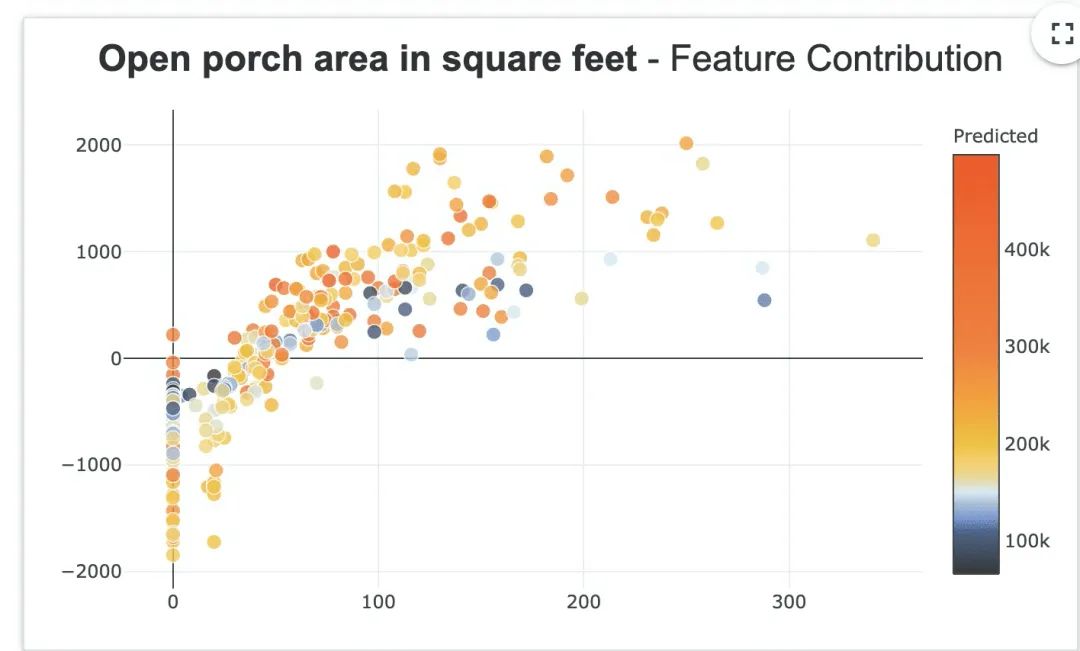
此外还有一些可视化的特性等待大家探索:
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
