
大家来找茬:记一起 clang 开启 -Oz 选项引发的血案
前言
笔者来自字节跳动终端技术 AppHealth (Client Infrastructure - AppHealth) 团队,在工作中我们会对开源 LLVM 及 Swift 工具链进行维护和定制,推动各项编译器优化在业务场景中的落地。编译器作为一个复杂的软件也会有 bug,也会有各种兼容性和正确性的问题,这里我们分享一则开启 clang 的
-Oz 优化选项时发现的编译器缺陷。问题
在 Xcode 中我们可以对 clang 编译器设置不同的优化等级,比如在 Debug 模式下默认会使用
-O0,在 Release 模式默认使用 -Os(兼顾执行速度和体积),但是在一些性能要求不大的场景,我们可以使用 -Oz级别,开启后编译器会针对代码体积采取更加激进的优化手段。
公司的一个视频组件为了减包开启 clang 的
-Oz 优化级别进行编译,但在开启后的测试中发现,视频组件在导出视频时出现内存暴涨然后发生 OOM 闪退,并且可以稳定重现。通过 Instruments 及 Xcode 的 Memory Graph 功能可以看到大量的 GLFramebuffer 被创建,而每个 GLFramebuffer 中会持有一个 2MB 的 CVPixelBuffer ,导致占用大量内存。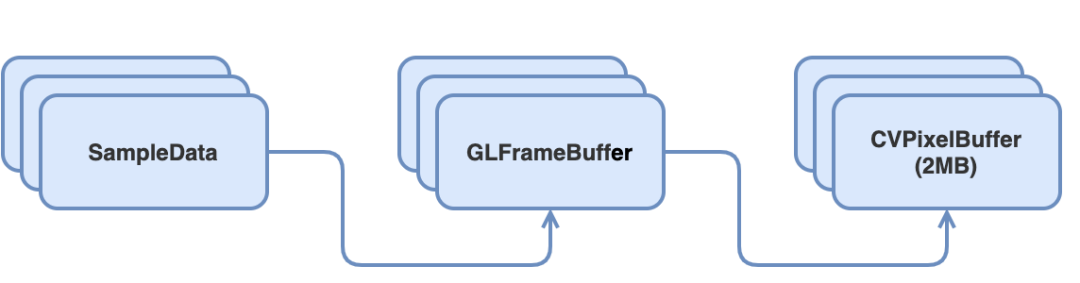
预期中这些
GLFramebuffer 应该被复用而不是重复创建,但通过日志发现每次获取时都没有可用的 buffer,于是就不断创建新的 buffewr。在代码逻辑中, buffer 是否能重用依赖于 -[GLFramebuffer unlock] 是否被调用,但是通过观察发现:这些 buffer 会堆积到导出任务结束后才被 unlock,所以我们需要找到 unlock 被推迟的原因。通过阅读代码发现:
GLFramebuffer 会被一个 SampleData 对象持有,并在 -[SampleData dealloc] 被调用时对 GLFramebuffer 进行 unlock ,当 SampleData 对象被放到 autoreleasepool 中堆积起来就会出现内存暴涨,符合前面观察到 buffer 批量 unlock 的现象(在 autoreleasepool 批量释放对象的时候)。
注意到之前不开启
-Oz 时 SampleData 对象是不会进入 autorelasepool 的,所以没有问题,于是接下来我们需要找到为什么开启 -Oz 后 SampleData 对象会被进入 autorelasepool。在 ARC 下对象是通过诸如
objc_autoreleaseReturnValue / objc_autorelease 的 C 函数来触发 autorelease 操作,我们无法通过符号断点到 -[SampleData autorelease] 来确认释放时机,除非把代码改回 MRC,所以这里得通过特殊的方式:在工程中添加如下一个类,并在 compiler flag 设置
-fno-objc-arc 关闭 ARC:
// 和 SampleData 一样都是继承自 NSObject
@interface BDRetainTracker : NSObject
@end
@implementation BDRetainTracker
- (id)autorelease {
return [super autorelease]; // 此处设置断点
}
@end
在重写的
autorelease 方法设置断点,然后在 App 启动后执行:
class_setSuperclass(SampleData.class, (Class)NSClassFromString(@"BDRetainTracker"));
如此一来
SampleData 被 autorelease 时会在我们设置的断点停下。通过这种方法结合上下文可以发现 SampleData 被 autorelease 的时机集中在 -[CompileReaderUnit processSampleData:] :
- (BOOL)processSampleData:(SampleData *)sampleData {
...
SampleData *videoData = [self videoReaderOutput];
...
如果改写成以下形式,发现内存暴涨现象就会消失:
- (BOOL)processSampleData:(SampleData *)sampleData {
@autoreleasepool {
...
SampleData *videoData = [self videoReaderOutput];
...
}
这里
[self videoReaderOutput] 返回一个 autoreleased 对象是符合 ARC 的约定的,但是之前没开启 -Oz 时编译器进行了优化,对象并不会进入 autoreleasepool,方法返回后就马上被释放了,查看 LLVM 的相关文档:
When returning from such a function or method, ARC retains the value at the point of evaluation of the return statement, then leaves all local scopes, and then balances out the retain while ensuring that the value lives across the call boundary. In the worst case, this may involve anautorelease, but callers must not assume that the value is actually in the autorelease pool.
ARC performs no extra mandatory work on the caller side, although it may elect to do something to shorten the lifetime of the returned value.
由于 autorelase 是一个有比较大开销的操作,所以 ARC 会尽可能将其优化掉,但是从这个现象我们可以猜测,开启
-Oz 后此处的编译器对应的优化失效了,让我们查看 SampleData *videoData = [self videoReaderOutput] 处的汇编:
adrp x8, #0x1018b5000
ldr x1, [x8, #0x1c0] ; 加载 @selector(videoReaderOutput)
bl _OUTLINED_FUNCTION_40_100333828 ; 调用外联函数
bl _OUTLINED_FUNCTION_0_1003336bc ; 调用外联函数
其中调用的两个
_OUTLINED_FUNCTION_ 函数的内容如下:
_OUTLINED_FUNCTION_40_100333828:
mov x0, x20
b imp_stubsobjc_msgSend
_OUTLINED_FUNCTION_0_1003336bc:
mov x29, x29
b imp_stubsobjc_retainAutoreleasedReturnValue
所以这里生成的代码逻辑是符合预期的:
调用objc_msgSend(self, @selector(videoReaderOutput), ...)返回一个 autoreleased 对象
然后对返回的对象调用objc_retainAutoreleasedReturnValue进行强引用
我们可以对比之前开启
-Os 生成的代码,此处 LLVM 的 MIR outliner 生效了:
adrp x8, #0x10190d000
ldr x1, [x8, #0xf0]
mov x0, x20
bl imp_stubsobjc_msgSend
mov x29, x29
bl imp_stubsobjc_retainAutoreleasedReturnValue
Machine Outliner
编译器在 -Oz 优化级别下 3~4 行和 5~6 行两段指令因为在多处被使用,于是分别被抽离到独立的函数进行复用,而原来的地方变成了一条函数调用的指令,数量从 4 条变成 2 条,从而达到减包的目的,这便是 LLVM 的 Machine Outliner 所做的事情,在 -Oz 下它会被默认开启来达到更极致的代码体积缩减(在其它优化级别下需要通过 -mllvm -enable-machine-outliner=always 来开启),其大致原理如下:
extern int do_something(int);
int calc_1(int a, int b) {
return do_something(a * (a - b));
}
int calc_2(int a, int b) {
return do_something(a * (a + b));
}
这段代码中
calc_1/calc_2 都调用了 do_something,尽管参数都不一样,但是我们能从汇编看到一些重复出现的指令序列(这里用 ARMv7 架构的汇编方便演示)
calc_1(int, int):
add r1, r1, r0 ; A
mul r0, r1, r0 ; B
add r1, r1, r0 ; A
mul r0, r1, r0 ; B
b do_something(int) ; C
calc_2(int, int):
add r1, r1, r0 ; A
add r1, r1, r0 ; A
mul r0, r1, r0 ; B
b do_something(int) ; C
我们给相同的指令打上相同的标签,所以
calc_1 的指令序列是 ABABC 而 calc_2 是 AABC,编译器通过构造一个后缀树可以找到它们的最长公共子串是 ABC,那么 ABC 这一段就可以被剥离成一个独立的函数:
calc_1(int, int):
add r1, r1, r0 ; A
mul r0, r1, r0 ; B
b OUTLINED_FUNCTION_0
calc_2(int, int):
add r1, r1, r0 ; A
b OUTLINED_FUNCTION_0
OUTLINED_FUNCTION_0:
add r1, r1, r0 ; A
mul r0, r1, r0 ; B
b do_something(int) ; C
由于在 ARC 代码中编译器插入的内存管理相关指令非常常见,所这些操作多数会被 outlined(读者如果对其实现细节感兴趣可以参考这个演讲)。
ARC 优化
但是为何指令被 outline 后 ARC 的优化会失效呢?留意到 mov x29, x29 这条指令,它实际上并没有做任何有意义的操作(将 x29 寄存器的值又存到 x29),它只是个特殊的标记,是编译器用于辅助运行时进行优化的手段, videoReaderOutput 的实现中返回 autorelease 对象是一个这样的调用:
return objc_autoreleaseReturnValue(ret);
其运行时的实现大致如下:
// Prepare a value at +1 for return through a +0 autoreleasing convention.
id objc_autoreleaseReturnValue(id obj) {
if (prepareOptimizedReturn(ReturnAtPlus1)) return obj;
return objc_autorelease(obj);
}
// Try to prepare for optimized return with the given disposition (+0 or +1).
// Returns true if the optimized path is successful.
// Otherwise the return value must be retained and/or autoreleased as usual.
static ALWAYS_INLINE bool
prepareOptimizedReturn(ReturnDisposition disposition) {
assert(getReturnDisposition() == ReturnAtPlus0);
if (callerAcceptsOptimizedReturn(__builtin_return_address(0))) {
if (disposition) setReturnDisposition(disposition);
return true;
}
return false;
}
static ALWAYS_INLINE bool
callerAcceptsOptimizedReturn(const void *ra){
// fd 03 1d aa mov x29, x29
if (*(uint32_t *)ra == 0xaa1d03fd) {
return true;
}
return false;
}
static ALWAYS_INLINE void
setReturnDisposition(ReturnDisposition disposition) {
tls_set_direct(RETURN_DISPOSITION_KEY, (void*)(uintptr_t)disposition);
}
objc_autoreleaseReturnValue 中会使用 __builtin_return_address 获取返回地址的指令,检查是否存在标记 mov x29 x29,如果有,意味着我返回的这个对象会马上被 retain,所以没必要放到 autoreleasepool 中,此时运行时会在 Thread Local Storage 中记录此处做了优化,然后回计数 +1 的对象即可。对应地
videoReaderOutput 的调用方会使用 objc_retainAutoreleasedReturnValue 引用住对象,实现如下:
// Accept a value returned through a +0 autoreleasing convention for use at +1.
id objc_retainAutoreleasedReturnValue(id obj) {
if (acceptOptimizedReturn() == ReturnAtPlus1) return obj;
return objc_retain(obj);
}
// Try to accept an optimized return.
// Returns the disposition of the returned object (+0 or +1).
// An un-optimized return is +0.
static ALWAYS_INLINE ReturnDisposition
acceptOptimizedReturn() {
ReturnDisposition disposition = getReturnDisposition();
setReturnDisposition(ReturnAtPlus0); // reset to the unoptimized state
return disposition;
}
static ALWAYS_INLINE ReturnDisposition
getReturnDisposition() {
return (ReturnDisposition)(uintptr_t)tls_get_direct(RETURN_DISPOSITION_KEY);
}
objc_retainAutoreleasedReturnValue 看到 TLS 中的标记知道无需进行额外 retain,于是两者配合从而优化掉了一次 autorelease 和 retain 操作,但这是编译器和运行时的优化细节,不应该假设优化一定会被发生。正是由于开启 -Oz 后,machine outliner 棒打鸳鸯把 objc_msgSend 和 objc_retainAutoreleasedReturnValue 的调用指令及标记 outline 了,导致这个优化没有触发,对象进入 autoreleasepool。总结
所以本质上这既是一个开发者的疏忽:使用占用大内存的临时对象后没有及时增加 autoreleasepool 将其释放,只是 ARC 的优化将这个问题隐藏,最终在开启 -Oz 后被暴露。
同时,这也是一个编译器的 bug,不应该将此处代码进行 outline 导致 ARC 的优化失效,这个 bug 直到最近才在 LLVM 里面被修复。
同样是使用 ARC 的 Swift 也有类似的问题,在某些 ARC 优化(比如
-enable-copy-propagation )没有开启的情况下一些对象的生命周期可能会被延长,然后这个现象被开发者利用,在编译器保证之外的生命周期使用该对象,一开始可能没有问题,但是一旦这些优化由于编译器的升级或者代码的改动突然生效了,那么之前使用对象的地方可能就会访问到一个被释放的对象,更多具体的例子可以参考 WWDC 21 的 Session 10216。相关链接
LLVM 的相关文档
https://clang.llvm.org/docs/AutomaticReferenceCounting.html#unretained-return-values
Machine Outliner
https://llvm.org/doxygen/MachineOutliner_8cpp_source.html
Outlined 相关演讲
http://www.llvm.org/devmtg/2016-11/Slides/Paquette-Outliner.pdf
指令被 outline 后 ARC 的优化
https://github.com/opensource-apple/objc4/blob/cd5e62a5597ea7a31dccef089317abb3a661c154/runtime/objc-object.h#L929-L984
bug 修复
https://github.com/llvm/llvm-project/commit/ed4718eccb12bd42214ca4fb17d196d49561c0c7
WWDC 21 的 Session 10216
https://developer.apple.com/videos/play/wwdc2021/10216
关于字节终端技术团队
字节跳动终端技术团队(Client Infrastructure)是大前端基础技术的全球化研发团队(分别在北京、上海、杭州、深圳、广州、新加坡和美国山景城设有研发团队),负责整个字节跳动的大前端基础设施建设,提升公司全产品线的性能、稳定性和工程效率;支持的产品包括但不限于抖音、今日头条、西瓜视频、飞书、瓜瓜龙等,在移动端、Web、Desktop等各终端都有深入研究。
就是现在!客户端/前端/服务端/端智能算法/测试开发 面向全球范围招聘!一起来用技术改变世界,感兴趣可以联系邮箱 chenxuwei.cxw@bytedance.com,邮件主题 简历-姓名-求职意向-期望城市-电话。
移动研发平台 veMARS 是终端技术团队基于字节跳动过去九年在抖音、今日头条、西瓜视频、飞书、瓜瓜龙等 App 研发中的实践成果,沉淀并在火山引擎开放。致力于为开发者提供移动开发解决方案,帮助企业降本增效,打造高质量、高性能的优质 App 体验。
👇 点击阅读原文,免费体验。